
こちらはこの記事はLayerX AI Agentブログリレーの6日目の記事です。前回は@yuya_takeyamaによるclaude-code-base-action で設定ファイル自動生成のための Agentic Workflow を作るでした。
こんにちは。バクラク事業部 BizOps部 データグループの@civitaspoです。最近、Snowflakeを中心としたAI Agentシステムの構築に思いを馳せており、その一環で技術調査したAI Observability in Snowflake Cortexについて紹介しようと思います。
AI Observability in Snowflake CortexはSnowflakeが2024年5月に買収を発表したTruEraの技術を基盤とした機能です。本記事では、AI Observability in Snowflake Cortexの概要と、TruLensを使った実装方法、およびSnowflake上での確認方法について紹介したいと思います。
SnowflakeによるTruEraの買収
AI Observability in Snowflake Cortexの話をする前に、この機能の基盤技術を開発したTruEraについて少し触れておきます。2024年5月22日、SnowflakeはAI/ML Observabilityプラットフォームを提供するTruEraの買収を発表しました。TruEraは2019年に設立された企業で、LLMアプリケーションやMLモデルの本番環境における評価・監視機能を提供するObservabilityプラットフォームを提供していました。
買収前のTruEraのブログを読む限り、Enterprise-gradeの顧客が本番環境で利用するほどには有名なプラットフォームだったようです。
TruEraが開発していたTruLensというオープンソースのAI Observabilityフレームワークは、2025年9月16日時点でGitHub上のスター数が2800を超えています。
この買収により、TruLensを使ったAI ObservabilityがSnowflake Cortexの機能として「AI Observability in Snowflake Cortex」という名称で提供されることになりました。一方、Snowflakeは買収時にTruLensをオープンソースとして維持することを約束しています。Streamlit買収時も同様の感想を持ちましたが、SnowflakeはOSSの利用者を大切にしていて良いですね。
AI Observabilityとは何か
次に、AI Observabilityという汎用的な概念について説明します。AI Observability とは、生成 AI システムの挙動を多角的に観測し、品質・信頼性・効率を保つためのプラクティスおよびツール群を指します。従来のObservabilityシステムでは、システムの健全性を測るためにレイテンシやエラー率、スループットといった稼働指標を主として用いる一方、AI Observabilityでは、稼働指標に加えて「応答内容の質」も評価対象に含めます。具体的には以下のような品質指標を用います。
- 回答がユーザーの意図に合っているか(Relevance)
- 根拠が与えられたコンテキストに基づいているか(Groundedness)
- 有害な内容を含んでいないか(Harmfulness)
- 事実と異なる情報を生成していないか(Hallucination)
- など
LLM は同じ入力でも異なる応答を返す非決定的な性質を持ち、ブラックボックス性やプロンプトインジェクション、トークン管理など固有の課題も伴うため、これらを定量化しながら信頼性を担保するための仕組みとしてAI Observabilityが存在します。
2025年9月16日現在、TruLens以外にも様々なソリューション・製品が存在します。LangfuseやDatadogのLLM Observabilityなどです。
Langfuseに関しては弊社から複数の記事を出していますので合わせてご覧になられてください。
tech.layerx.co.jp tech.layerx.co.jp tech.layerx.co.jp
AI Observability in Snowflake Cortexとは
AI Observability in Snowflake Cortexは、TruLensを基盤として、Snowflake上でLLMアプリケーションの観測・評価・改善を実現する統合機能です。2025年7月31日に正式にGAとなり、すべてのユーザーが利用可能になりました。
docs.snowflake.com www.snowflake.com
主に以下の3つの機能を提供します。
- Evaluations
- Comparisons
- Tracing
それぞれ詳しく見ていきます。
Evaluations
LLMの出力品質を定量的に評価する機能です。AI ObservabilityではLLM-as-a-judge(LLMを評価者として使用)アプローチを採用しており、デフォルトではllama3.1-70bが評価者として使用されます。
2025年9月16日時点で評価可能なメトリクスは以下のとおりです。
- Context Relevance: 検索サービスやリトリーバから取得したコンテキストが、ユーザーのクエリに適切かどうかを評価します。
- Groundedness: 生成された回答が、取得したコンテキストに裏付けられているか(事実に基づいているか)を測定します。
- Answer Relevance: 生成された回答が、ユーザーの質問にどれだけ関連しているかを評価します(正解ラベルがなくても評価可能)。
- Correctness: 生成された回答が、与えられた正解(ground truth)にどれだけ整合しているかを測定します。
- Coherence: 回答全体が論理的に一貫し、矛盾や飛躍がないかを評価します。
SnowflakeのUIでは、Inputクエリに対するLLMのOutputと上記指標を一覧できるUIが提供されています。
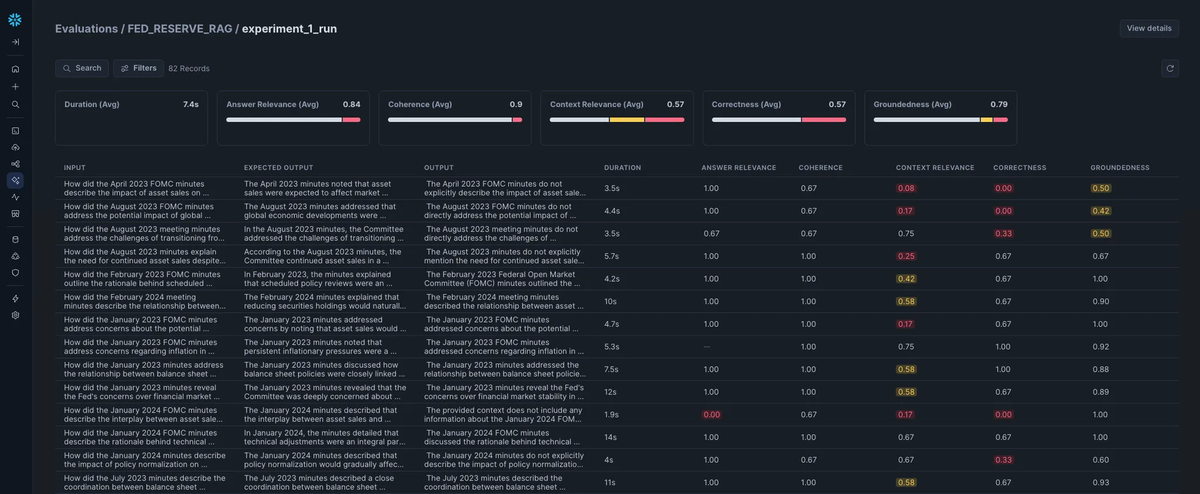
Comparisons
異なるモデル、プロンプト、またはコンフィギュレーション間でのパフォーマンス比較を行う機能です。以下のスクリーンショットから分かるように、アプリケーション・アプリケーションバージョン・実験名・ラベルごとに性能の評価を行うことができます。


Tracing
LLMアプリケーションの実行フローを詳細に記録・可視化する機能です。AI Observability以前から存在していたTracingを、LLMのinput/outputやEvaluationsで付与されたメトリクスが付与された状態で閲覧することができます。


TruLensを使った実装方法
実際にTruLensを使用してSnowflake上でAI Observabilityを実装する方法を説明します。なお、全てのコードはSnowflakeが用意する『Getting Started with AI Observability』のコードを使用します。重要な部分のみを切り出して本記事に記載するので、サンプルアプリケーションを実行するための前準備やコード全体は『Getting Started with AI Observability』を参照してください。
quickstarts.snowflake.com github.com
事前準備
TruLensによるEvaluations実行のために以下の権限が必要です。
CREATE ROLE _AI_O11Y_USER_ACCESS_ROLE; GRANT DATABASE ROLE SNOWFLAKE.CORTEX_USER TO ROLE _AI_O11Y_USER_ACCESS_ROLE GRANT APPLICATION ROLE SNOWFLAKE.AI_OBSERVABILITY_EVENTS_LOOKUP TO ROLE _AI_O11Y_USER_ACCESS_ROLE GRANT CREATE EXTERNAL AGENT ON SCHEMA app_schema TO ROLE _AI_O11Y_USER_ACCESS_ROLE; GRANT CREATE TASK ON SCHEMA app_schema TO ROLE _AI_O11Y_USER_ACCESS_ROLE; GRANT EXECUTE TASK ON ACCOUNT TO ROLE _AI_O11Y_USER_ACCESS_ROLE; GRANT ROLE _AI_O11Y_USER_ACCESS_ROLE TO ROLE SOME_SERVICE_ROLE;
また、以下のパッケージも事前にインストールしておく必要があります。
trulens-coretrulens-providers-cortextrulens-connector-snowflake
RAGアプリケーションへTruLensの@instrumentデコレーダーを付与
TruLensによる計測を行うため、RAG実装の各関数に対して@instrumentデコレータを付与していきます。このデコレータを付与することにより、各関数ごとのtracingを可能とします。
from snowflake.cortex import complete from trulens.core.otel.instrument import instrument from trulens.otel.semconv.trace import SpanAttributes class RAG: def __init__(self): self.retriever = CortexSearchRetriever(snowpark_session=session, limit_to_retrieve=4) @instrument( span_type=SpanAttributes.SpanType.RETRIEVAL, attributes={ SpanAttributes.RETRIEVAL.QUERY_TEXT: "query", SpanAttributes.RETRIEVAL.RETRIEVED_CONTEXTS: "return", } ) def retrieve_context(self, query: str) -> list: """ Retrieve relevant text from vector store. """ return self.retriever.retrieve(query) @instrument( span_type=SpanAttributes.SpanType.GENERATION) def generate_completion(self, query: str, context_str: list) -> str: """ Generate answer from context. """ prompt = f""" You are an expert assistant extracting information from context provided. Answer the question in long-form, fully and completely, based on the context. Do not hallucinate. If you don´t have the information just say so. Context: {context_str} Question: {query} Answer: """ response = "" stream = complete("mistral-large2", prompt, stream = True) for update in stream: response += update print(update, end = '') return response @instrument( span_type=SpanAttributes.SpanType.RECORD_ROOT, attributes={ SpanAttributes.RECORD_ROOT.INPUT: "query", SpanAttributes.RECORD_ROOT.OUTPUT: "return", }) def query(self, query: str) -> str: context_str = self.retrieve_context(query) return self.generate_completion(query, context_str) rag = RAG()
RAGアプリケーションの評価
実際に、実装したRAGアプリケーションを評価を行います。まず、計測したデータはSnowflakeへ送信するので、TruLens用のSnowflakeConnectorを初期化します。次に、計測するアプリケーションを定義するTruAppの初期化を行います。ここに定義した情報がSnowflake上で、他アプリケーションや他バージョンと比較する際に利用されます。最後に、評価の条件を定義するRunConfigを初期化します。このRunConfigには評価に使用するデータセットや評価の識別に使用するラベルの定義を行えます。
from trulens.apps.app import TruApp from trulens.connectors.snowflake import SnowflakeConnector from trulens.core.run import Run from trulens.core.run import RunConfig from snowflake.snowpark.context import get_active_session session = get_active_session() tru_snowflake_connector = SnowflakeConnector(snowpark_session=session) app_name = "fed_reserve_rag" app_version = "cortex_search" tru_rag = TruApp( rag, app_name=app_name, app_version=app_version, connector=tru_snowflake_connector ) run_name = "experiment_1_run" run_config = RunConfig( run_name=run_name, dataset_name="FOMC_DATA", description="Questions about the Federal Open Market Committee meetings", label="fomc_rag_eval", source_type="TABLE", dataset_spec={ "input": "QUERY", "ground_truth_output":"GROUND_TRUTH_RESPONSE", }, ) run: Run = tru_rag.add_run(run_config=run_config) run.start()
run.start()を実行することで指定されたデータセットを使用した評価が開始されます。この時点では、LLMによる評価は行われず、あくまでinput/outputの情報やtracing情報の送付のみが行われます。
LLMによる評価
run.start() の実行完了後、 run.compute_metrics(…) を実行することで、 run.start() で取得されたtrace情報に対して、LLMによる評価を実行することができます。
run.compute_metrics([
"coherence",
"answer_relevance",
"context_relevance",
"groundedness",
"correctness",
])
この実装は内部的にはSnowflakeの SYSTEM$EXECUTE_AI_OBSERVABILITY_RUN というProcedureを実行しているだけなので、TruLensを使わなくても実行すること自体は可能です。
おわりに
この記事では、Snowflake AI Observability in Cortexを使用して、LLMアプリケーションの品質を担保する方法について紹介しました。TruEraの買収により、SnowflakeはAI Observabilityを担保できるプラットフォームへと進化しています。AI Observabilityは、LLMアプリケーションを本番環境で安全に運用するために不可欠な要素です。特に、Snowflake環境内で完結できることで、システムによってはお客様の情報を含むかもしれないプロンプトが外部へ流出しないことを保証できる点は大きな魅力です。
現在、AI Observability領域では様々なソリューションやSaaSが群雄割拠している状態ですが、Snowflake上でLLMアプリケーションを実装している会社にとってはSnowflake AI Observability in Cortexは良い選択になるかもしれません。この紹介記事がどなたかの検証・評価に役立てば良いなと祈っています。
LayerXでは、Snowflakeを活用したデータ基盤の構築と、その上でのAI/MLシステムの開発を進めています。データ基盤はもちろんのこと、AI Observabilityの実装や、LLMアプリケーションの品質管理などに興味がある方も、ぜひ一緒にチャレンジしましょう!
最後に改めて、この記事はLayerX AI Agentブログリレーの6日目の記事です。毎日AI Agentに関する知見をお届けします!!LayerXテック公式Xを是非フォローして見逃さないようにお願いします!