こんにちは。バクラク事業部 機械学習・データ部 データグループの@civitaspoです。みなさんは「人生で一番美味しいと思ったキムチ」に出会ったことはありますか?キムチって美味しいですが、あまり強い感情は抱かないですよね。ところが先日、近所のスーパーの駐車場の端っこに、謎のプレハブ小屋があるのを発見しました。興味本位で中を覗いてみると、そこはキムチ屋でした。そのキムチ屋が販売する自家製キムチは絶品で、私にとって「人生で一番美味しいと思ったキムチ」でした。みなさんも「人生で一番美味しいと思ったキムチ」を探してみてください。
さて、先週に引き続き、Snowflakeに関する記事を書こうと思います。先週は『Don’t Use Passwords in Your Snowflake Account』というタイトルで、Snowflakeのアカウントレベルでパスワード認証を禁止する方法を紹介しました。
今回の記事では、Snowpipe StreamingとAmazon Data Firehoseを使用して、Snowflakeへストリームデータをロードする方法を紹介します。最初に、Snowpipe StreamingとAmazon Data Firehoseに関して基礎的な説明を行います。その後、Snowpipe StreamingとAmazon Data Firehoseを使用したストリームデータ配信システムの構築方法について、運用にあたって考慮したポイントを交えて説明します。
なお、7月はLayerXのエンジニアブログがたくさん出る#ベッテク月間です。LayerXの行動指針の一つである「Bet Technology」を略して「ベッテク」と呼んでいます。今後もベッテクな記事がたくさん出ますので、どんな記事がでるのかこちらのカレンダーからチェックしてみてください!
Snowpipe Streamingとは?

Snowpipe Streamingとは、Snowflakeへの低遅延ロードを実現するためのAPIです。Snowpipeは「ファイル単位のデータロード」にフォーカスしたソリューションであるのに対し、Snowpipe Streamingは「行単位のデータロード」にフォーカスしたソリューションです。メッセージキューに書き込まれたデータなど、行単位で処理する方が適切なデータを、Snowflakeへロードする場合にSnowpipe Streamingを選択すると良いでしょう。
Snowpipe StreamingのAPI仕様に関するドキュメントは、本記事の公開時点では存在していません。しかし、SDKは公開されています。そのため、コードを読むことで内部の仕様を把握することができます。
内部的には以下のような処理が行われています。コードリーディングを容易にするため、それぞれの項目ごとに該当のコードをリンクしています。
/v1/streaming/channels/open/へのリクエストでチャネルのオープンinsertRowsメソッドから受け取ったデータをバッファリング- バッファリングしたデータをファイルとして内部StageへPut
/v1/streaming/channels/write/blobs/へのリクエストでPutしたデータの登録
登録されたデータは、Snowflake内部の非同期処理によって、Native Tableに最適化されたファイルフォーマットへの変換が行われます。登録されたデータはSnowflakeによる変換処理が行われるまでは、最適化されていないファイルフォーマットとなりますが、アクセスすることは可能です。
また、APIやSDKにはExactly-onceセマンティクスをサポートするための機能が実装されています。そのため、Snowpipe Streamingと統合された機能を検証する際は、Exactly-onceセマンティクスをサポートしているかどうか確認すると良いでしょう。
他に特筆すべき制約として、 AUTOINCREMENT や DEFAULT を使用できない*1点が挙げられます。Snowpipe Streamingを使用して書き込むテーブルには、連番用カラムやIngestion Time格納用カラムといったデータ処理を補助するためのカラムを、テーブルのオプションを利用して定義することができません。連番やIngestion TimeはSnowpipe Streamingにストリームデータを配信する前に、データに対して付与しておく必要があります。
Amazon Data Firehoseとは?
Amazon Data Firehose(以下、Firehose)は、AWSが提供する、ストリームデータの配信を行うためのフルマネージドサービスです。サポートしている配信先は、Amazon S3やAmazon RedshiftといったAWSが提供するサービスだけではなく、サードパーティが提供するHTTPエンドポイントや独自のHTTPエンドポイントも定義することができます。
Snowflakeとのインテグレーションは2024年1月にプレビューリリースされ、2024年4月に正式にリリースされました。現在はすべてのAWSリージョンで使用することができます。
Snowflakeとのインテグレーションで特徴的なのは課金体系です。他の配信先を使用するケースと比較すると約3倍のコストとなります。この価格設定は、配信量次第では許容できない可能性があるので、導入前に試算しておきましょう。
最後に、FirehoseのFAQドキュメントにSnowflakeとのインテグレーションに関する重要な記載があるので、引用とともに言及しておきます。
まず、Snowpipe Streamingの章でも記載したExactly-onceセマンティクスに関してです。FirehoseのSnowflakeインテグレーションではExactly-onceセマンティクスをサポートしています。
Q: What delivery model does Firehose use when delivering data to Snowflake streaming?
Firehose uses exactly-once delivery semantics for Snowflake. This means that each record is delivered to Snowflake exactly once, even if there are errors or retries. However, exactly-once delivery does not guarantee that there will be no duplicates in the data end to end, as data may be duplicated by the producer or by other parts of the ETL pipeline.
また、一つのFirehose Streamに対して、一つのSnowflakeテーブルにしか書き込むことができません。ストリームデータの内容から動的に書き込み先を分岐させたい場合は、Snowflakeのテーブルに書き込んだ後、ViewやDynamic Tableとして再定義を行う必要があります。
Q: Is it possible for a single Firehose stream to deliver data to multiple Snowflake tables?
Currently, a single Firehose stream can only deliver data to one Snowflake table. To deliver data to multiple Snowflake tables, you need to create multiple Firehose streams.
Firehoseにデータが到達してからSnowflakeに配信されるまでの遅延は多くのケースで5秒以内です。非常に低遅延でストリームデータの配信が行われるため、後続のデータ処理やモニタリングでは、1分以上のデータ遅延は異常だとみなして、処理を行うのが良いでしょう。
Q: What is the minimum latency for delivering to Snowflake streaming using Firehose?
We expect most data streams to be delivered within 5 seconds.
Amazon Data FirehoseとSnowpipe Streamingを使用したストリームデータ配信システムの構築
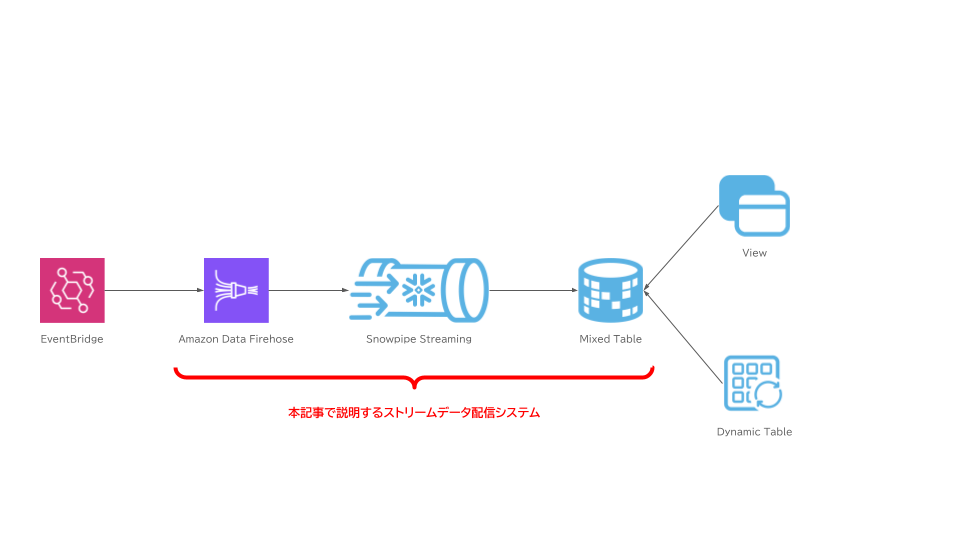
この章から、具体的なシステム構築の方法を紹介していきます。FirehoseとSnowpipe Streamingを使用したストリームデータ配信システムの構築に関する概要を知るには、Snowflakeが提供しているハンズオン資料やAWSブログを参照するのが最適です。ご一読をおすすめします。
このシステムの構築にあたり、大きく分けて3つのリソース作成が必要です*2。
- Snowflake: アクセス用ユーザーの作成
- Snowflake: 書き込み先テーブルの作成
- Firehose: Snowpipe Streamingへの配信設定
これらを順に説明していきます。
Snowflake: アクセス用ユーザーの作成
FirehoseからSnowflakeへ接続するためのユーザーを作成します。このユーザーに必要な条件は以下のとおりです。
- Key-Pair認証を使用できる
- 書き込み先テーブルへの書き込み権限を持っている
例として、データベース LANDING_FIREHOSE のスキーマ DEMO_SCHEMA へ書込み可能なアクセスロール*3 _LANDING_FIREHOSE_WRITER が存在していて、ユーザー DEMO_USER を作成しようとしている場合、以下のクエリによってユーザー作成が完了します。
CREATE USER TEST_USER RSA_PUBLIC_KEY='The value of your Public Key...'; GRANT ROLE _LANDING_FIREHOSE_WRITER TO USER DEMO_USER;
Snowflakeの運用に慣れている人は「Warehouseのアクセスロールは不要かな?」と疑問を持たれるかもしれません。Snowpipe StreamingはServerless Computeモデルを採用しているので、Warehouseは使用しません。そのため、WarehouseのアクセスロールをGRANTする必要はありません。
ユーザーの作成に関して、注意点が一つあります。それは秘密鍵のByte数です。Firehoseの設定時に秘密鍵を使用するのですが、Firehoseは秘密鍵の最大サイズとして「4096Byteまで」という制約があります。秘密鍵の生成時に、鍵の強度を高めようとbit数を上げすぎてしまうと、Firehoseでは使用不可な鍵が生成されてしまいます。そのため、制約があることを認識して鍵を生成するようにしましょう。以下のように4096bitを指定すると、制約限界に近い鍵を生成することができます*4。
openssl genrsa 4096 | openssl pkcs8 -topk8 -v2 des3 -inform PEM -out rsa_key.p8
Snowflake: 書き込み先テーブルの作成
次に、書き込み先のテーブルを作成します。このテーブルは、どういったアクセスが行われるか慎重に検討してテーブルを作成する必要があります。なぜなら、このテーブルはストリームデータを常に書き込み続けるテーブルであるため、運用開始後にスキーマ変更を行う難易度が非常に高いからです。
テーブルを設計する前に、FirehoseがSnowflakeへデータを書き込む方法について言及しておきます。FirehoseからSnowflakeのテーブルにデータを書き込む方法は2パターン存在します。
一つは、Firehoseに到達したJSONをテーブル定義にマッピングして書き込む方法(JSON_MAPPING)です。JSONのキーをカラム名、バリューを値として書き込みます。この方法はJSONとテーブルのマッピングが一致する場合のみ、データの書き込みが可能です。そのため、Firehoseで配信するJSONのスキーマが固定されている必要があります。なお、JSON_MAPPINGでは配信するJSONの全てのキー・値をフラットに定義されていなければならないわけではありません。JSONのトップレベルのキーがカラム名と一致していれば良く、型はVARIANT型を使用することができます。JSONの値にJSONオブジェクトが格納されるケースではVARIANT型を指定することで、データの格納が可能です。
もう一つは、Firehoseに到達したデータをVARIANT型として書き込む方法(VARIANT_CONTENT)です*5。この方法は、データがJSONである必要もなく、データとカラムの一致を気にする必要もありません。一見、この方法は、配信するデータの変更に強く、障害の発生率を格段に下げる良い方法に見えます。しかし、全てのデータが単一のVARIANT型のカラムに格納されることの良し悪しについて考慮する必要があります。
ストリームデータの多くは時系列データであるため、Micro-PartitionのPruningも時系列で行える必要があります。しかし、VARIANT型に格納された「時間」は、フィルター条件に指定してもPruningが効きません。そのため、単一のVARIANT型カラムで構成されたテーブルは、そのままでは非常に扱いにくいテーブルとなってしまいます。Dynamic Tableなど、データ増分に対して処理を行い、用途ごとに別テーブルとして再定義してあげる必要があります。ただし、ご存知の通りDynamic Tableなど、データ増分に対して処理を行う機能は、Warehouseを高頻度で稼働させるため、その分コストがかかります。
以下に早見表をまとめておきます。
JSON_MAPPING |
VARIANT_CONTENT |
|
|---|---|---|
| ⭕ pros | ・時系列フィルターで使用するカラムを用意することで、Micro-PartitionのPruningを効かせることができる。その他、フィルターで使用するカラムも同様。 | ・どんなデータでも確実にSnowflakeに書き込みできる |
| ❌ cons | ・配信するデータはJSONでなければならない ・配信するJSONのトップレベルキーとSnowflakeテーブルのカラムが一致していなければならないため、データの変更に弱い |
・書き込まれたテーブルは時系列フィルターによるMicro-PartitionのPruningが効かない ・扱いやすいデータに加工するためDynamic Tableの運用が必要になる。運用コスト、金銭コストがかかる。 |
弊社では、上記内容を考慮してJSON_MAPPINGを採用しています。弊社の運用では、Amazon EventBridgeからのイベントをストリームデータとして処理するケースが多く、配信するデータのスキーマを完全に固定することができた*6ためです。
今回は説明を簡略化するため、VARIANT_CONTENTを採用した前提で、テーブルの作成を行います。テーブル名は DEMO_TABLE とします。
CREATE TABLE LANDING_FIREHOSE.DEMO_SCHEMA.DEMO_TABLE ( PAYLOAD VARIANT );
Firehose: Snowpipe Streamingへの配信設定
最後に、Firehoseの配信設定を行います。AWSのドキュメントに沿って必要な項目を埋めていきます。
Firehoseの設定で重要なポイントはエラーハンドリングです。Firehoseの設定では、Snowflakeへの配信が失敗した場合に、S3へのバックアップ出力が可能です。SnowflakeはS3のデータを直接取り込むことが可能なので、配信失敗時のオペレーション簡略化のため、S3へバックアップの出力を行いましょう。バックアップの出力先はExternal Stageとして事前に登録しておくと良いでしょう。配信失敗時は、External Stageからバックアップを参照し、データの取り込みを行います。
設定は以下のようになります。なお、テキストで設定を記述できるようにterraformを使用しています。AWSのConsoleから設定する方法について知りたい方は、先ほど言及したSnowflakeが提供しているハンズオン資料やAWSブログを参照してください。
resource "aws_kinesis_firehose_delivery_stream" "snowflake_firehose_integration" {
name = "blog-demo-snowflake-integration"
destination = "snowflake"
snowflake_configuration {
account_url = "https://your-snowflake-account.snowflakecomputing.com"
user = "DEMO_USER"
private_key = local.dummy_encrypted_rsa_private_key
key_passphrase = local.dummy_key_passphrase
database = "LANDING_FIREHOSE"
schema = "DEMO_SCHEMA"
table = "DEMO_TABLE"
snowflake_role_configuration {
enabled = true
snowflake_role = "_LANDING_FIREHOSE_WRITER"
}
# NOTE: "JSON_MAPPING", "VARIANT_CONTENT", "VARIANT_CONTENT_AND_METADATA_MAPPING" が選択できます。
data_loading_option = "VARIANT_CONTENT"
content_column_name = "PAYLOAD"
# NOTE: `snowflake_firehose_integration`というIAMロールをService Roleとして設定している前提です。
role_arn = aws_iam_role.snowflake_firehose_integration.arn
retry_duration = 30 # 特に意図はありません。0秒から7200秒の間で設定することができます。
# NOTE: s3_backup_mode は "FailedDataOnly" か "AllData" を選択できます。
# 配信されたすべてのデータをバックアップしておく必要がある場合は "AllData" を選択しましょう。
# ref. https://github.com/aws/aws-sdk-go-v2/blob/28fb34d57b5a55167372d14fcbfda14c4153b170/service/firehose/types/enums.go#L597-L600
s3_backup_mode = "FailedDataOnly" # "FailedDataOnly" か "AllData" を選択できます。
s3_configuration {
role_arn = aws_iam_role.snowflake_firehose_integration.arn
bucket_arn = "arn:aws:s3:::blog-demo-backup"
buffering_size = 10 # MB
buffering_interval = 300 # Seconds
compression_format = "GZIP"
error_output_prefix = "error/"
cloudwatch_logging_options {
# ここで設定するCloudwatch Logsにはエラーログのみが格納される。
enabled = true
log_group_name = "blog-demo-log-group"
log_stream_name = "blog-demo-snowflake-integration"
}
}
}
lifecycle {
ignore_changes = [
snowflake_configuration[0].private_key,
snowflake_configuration[0].key_passphrase
]
}
}
ここまでの設定で、FirehoseとSnowpipe Streamingを使用したストリームデータ配信システムを構築することができました。設定した LANDING_FIREHOSE.DEMO_SCHEMA.DEMO_TABLE を参照するとデータが格納され始めているはずです。
TerraformでAmazon Data Firehoseを構築する際の注意事項
最後に、TerraformでFirehoseのSnowflakeインテグレーションを構築する際の注意事項を最後に記載しておきます。
TerraformでFirehoseのSnowflakeインテグレーションを構築するには、terraform-provider-awsを使用します。
しかし、terraform-provider-awsでFirehoseを構築するために使用する kinesis_firehose_delivery_stream はやや不具合があります。たとえば、 snowflake_role_configuration は必須パラメータではありません。そして、たしかにリソースの作成時は必須パラメータとして扱われません。しかし、リソースの更新が発生する場合に限ってのみ snowflake_role_configuration が必須パラメータとして取り扱われる仕様になっています。
特に、tfstateに絶対に秘匿情報を書き込みたくない運用者にとって、kinesis_firehose_delivery_streamで秘匿情報(private_key および key_passphrase)を扱う難易度は非常に高い状態になっています。なぜなら、lifecycle.ignore_changesを使用して、terraform上でのprivate_key および key_passphraseの変更を行わない設定をしても、リソースの更新時には、private_key および key_passphraseが空文字列として更新されてしまうためです。
そこで、弊社はFirehoseとSecretsManagerのインテグレーション機能で秘匿情報を管理しています。現時点でkinesis_firehose_delivery_streamはSecretsManagerを扱うことはできません。そのため、構築後にFirehoseの設定を修正する必要がありますが、kinesis_firehose_delivery_streamで秘匿情報を更新されることがなくなります。
上記の不具合に関しては、terraform-provider-awsへPull Requestを送っていて、レビュー待ちのステータスです。このPull Requestがマージされれば、不具合も解消され、安心してTerraformでFirehoseとSnowflakeのインテグレーションを構築することができるようになるでしょう。
おわりに
この記事では、Snowpipe StreamingとAmazon Data Firehoseを使用してSnowflakeにストリームデータをロードする方法を紹介しました。まだ、この機能が登場してから日が浅く、運用知見が世の中に溜まっていないので、利用されている方や利用を検討している方の一助と慣れれば幸いです。
バクラク事業部では現在、データ基盤で利用するデータウェアハウスソリューションをGoogle BigQueryからSnowflakeへ移管するプロジェクトを進めています。そして、移管後にどういったデータ基盤を構築していくか、ワクワクしながら考えているフェーズです。まだまだ伸びしろが多く、やりたいこともたくさんあるので、一緒にワクワクしながらデータ基盤を作っていける仲間を募集しています。まずは、カジュアル面談からご応募ください!お話しましょう!お待ちしています!
データ関連の求人票
*1:DEFAULT NULL は使用可能。
*2:Private Linkを使用する場合は、専用の設定が必要ですが、弊社では利用していないため、本記事では触れていません。
*3:Aligning object access with business functionsを参照
*4:ECDSAやed25519といった署名アルゴリズムを使って強度を高めるほうが妥当だと思いますが、Snowflakeの仕様で、2048bit以上のRSA鍵でなければならない、と決められています。 Key-pair authentication and key-pair rotationを参照ください。
*5:正確には、VARIANT_CONTENTの情報に加えて、Firehoseがメタデータを格納するVARIANT_CONTENT_AND_METADATA_MAPPINGという方法も存在します。しかし、メタデータとしてFirehose Delivery Streamの名称が格納される程度なので、あえて説明していません。
*6:詳細はEvent structure referenceを参照ください。