はじめに
こんにちは!LayerX AI・LLM事業部でマネージャーを務めていますエンジニアの恩田( さいぺ )です。
AI・LLM事業部では「Ai Workforce」というプロダクトを開発しています。 エンタープライズ企業のドキュメントワークを効率化する生成AIプラットフォームと銘を打っており、そのユースケースは多岐にわたるのですが、その一つに論文からの項目抽出があります。

(出典)Jin, Bowen, et al. "Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG." arXiv preprint arXiv:2410.05983 (2024).
この例では論文から以下のような項目を取得しています。
- 著者名
- 著者の所属
- 実験に用いたデータセット
- 論文全体の概要(要約)
- 論文が解決する課題
- 先行研究との比較
このように、LLM(大規模言語モデル)に入力ドキュメントから何らかの値を抽出したり、要約を作らせたりというタスクは、読者のみなさんもよく行うことだと思います。 一方で、LLMによって生成されたテキストの正確さや信頼性は100%ではなく、その評価の仕方にも課題が多くあります。 本記事では、LayerXのプロジェクト「Ai Workforce」を例に、これらの課題と解決策を掘り下げます。
Ai Workforceにおける精度評価の対象
上述の抽出対象の項目は大きく「単純な値を取得するもの」と「文章が生成されるもの」の2つに分けられます。1つ目の「単純な値を取得するもの」は、exact matchやROUGE scoreといった評価手法を用いることで定量的に評価することが可能です。一方で、2つ目の「文章が生成されるもの」は、人間が目視で評価するしかないため、定量的な評価が難しいという課題があります。

LLM生成文章の精度評価の課題
「文章が生成されるもの」の精度評価には以下のような課題があります。
- 評価の主観性: 人間による評価にはばらつきが生じやすく、一貫した評価基準を設定するのが難しい
- 多様な生成結果: 生成された文章に対し、どこまでが「正解」と言えるかの基準が曖昧で、文脈やニュアンスの違いが大きく影響する
これらの課題により、従来の評価方法ではスケールさせることが難しく、AI・LLM事業部でもAi Workforceを導入する際に大きな工数が掛かる課題となっていました。
一般的な精度評価手法
そもそも、一般的にLLMが生成した文章の精度を評価するにはどのようなメトリクスがあるのでしょうか。 LLM Evaluation Metrics: The Ultimate LLM Evaluation Guideが非常によくまとまっていたので、引用すると、以下のようなメトリクスがあります。
- Answer Relevancy: 有益で簡潔な回答か
- Correctness: 事実として正しいか
- Hallucination: 捏造された情報が含まれていないか
- Contextual Relevancy: 文脈として適切か
- Responsible Metrics: バイアスや有害な情報が含まれていないか
- Task-Specific Metrics: ユースケースに応じた特定の評価指標
また、これらメトリクスを測るために、統計的なスコアやモデルベースのスコアについても紹介されています。 昨今話題のLLM-as-a-Judgeもモデルベースのスコアの一つと言えるでしょう。

(出典)Jeffrey Ip. "LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide", 2024. https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
間接的な精度評価の提案
とはいえ、LLMが生成した文章は上記のメトリクスやスコアを用いてもなかなかうまく評価することができないことも多いです。 そういった場合に提案したいのが、間接的な精度評価です。
例えば、Retrieve-augmented generation(RAG)であれば、Generation結果そのものではなく、Retrieveされたドキュメント・チャンクでrecallを計算することが可能です(Retrieveが失敗すれば生成も失敗するため、全体的な評価の上限を計測できる)。 他にも生成された文章に必ず含んでほしいキーワードがある場合、そのキーワードが含まれているかどうかを評価することも有効です。
このように直接的なメトリクスを計算せずとも、精度の上限や下限を把握する方法を導入することで、精度の 定量化 が可能です。
間接的な評価の意義とプロンプトチューニングの高速化
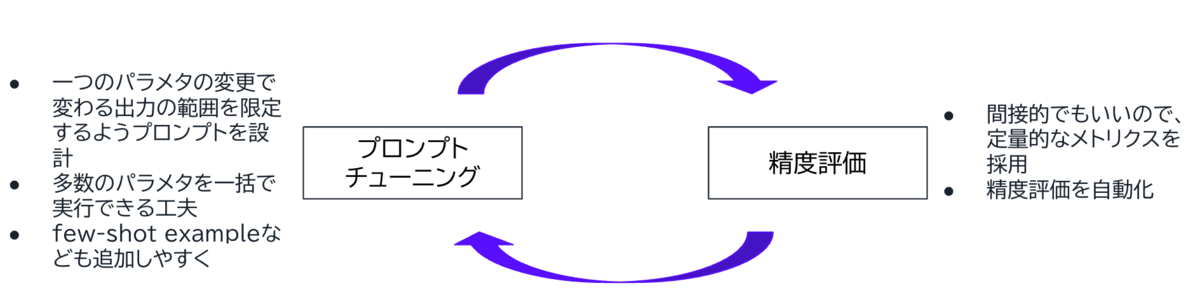
間接的な精度評価はプロンプトチューニングと組み合わせるとその真価を発揮します。 プロンプトチューニングと精度評価を密接に連携させることで、プロンプトの変更が精度にどのような影響を与えるかを短期間で把握できるようになります。 今まではLLMの生成文書を人手で評価していた箇所を、自動的に行えるため、プロンプトの改善と結果の向上を効率的に追求できます。 また、実際にプロンプトのチューニングをしていると試したいアイデアが何個も湧いてくると思います。その一つ一つを並行して試し、結果を比較することで、最適なプロンプトに効率的にたどり着くことができます。
このように、間接的な評価手法を取り入れることで、プロンプトチューニングのサイクルが高速化し、LLMのパフォーマンスを最適化するための土台が整います。 Ai Workforceは、LLMのPoCで終わらず、実際の業務に組み込んでこそ本当に価値を提供できるプロダクトであるため、業務に求められる精度の達成は必達です。 まだ本記事で紹介した手法を100点で実践できているわけではありませんが、こういった方法を駆使して、より高速に高い精度を実現するための取り組みを進めています。
最後に
一緒にAi Workforceを育て、お客さまに届ける仲間を募集しています。 この記事の内容に興味を持った方はぜひ【AI・LLM】ソフトウェアエンジニア兼プロダクトマネージャーからご連絡ください!ご一緒できる日を楽しみにしています!
また、明日11/19にプロダクト紹介イベントを開催予定です。ご都合の合う方はぜひご参加ください!
ポジション別応募ページ
【AI・LLM】ソフトウェアエンジニア / 株式会社LayerX
※本記事は AI Engineering Decoded #4で発表した内容に加筆・修正を行ったものです。