こんにちは、LayerX CTOの@y_matsuwitterです。最近はパン作りにハマっています。無心に小麦と酵母の声を聞くことで精神の安寧を求めています。
この記事は LayerXテックアドカレ2023 19日目の記事です。前回は @shota_tech が「Go の linter 雰囲気で使っていたから調べ直した #LayerXテックアドカレ」を書いてくれました。次回はEMオフィスの@serimaより「Engineering Officeの話」がポストされる予定なのでご期待ください。
ISUCON13
昨日開催のISUCONに参加してきました。とても楽しい問題ですし、これだけの人数での開催を支えている運営の皆さんには頭が上がりません。個人でもLayerXとしてもスポンサーさせていただきました。ありがとうございます!
10年近く一緒に出場している.datというチームで、私はプロンプトを考え、エディタでTabを押す係をしていました。割とマジです。10年も経つと皆ポジションも変わり、チームメンバーがLayerX、Cookpad、くふうカンパニーのCTO・CPOという構成になってしまいました。
残念ながらそれほど芳しい成績は残せず、3万点前後をうろうろしていたのですがChatGPTやCopilotをフル活用した戦い方に振り切っていたのでそのお話をさせてください。
スタート前の方針
今回のISUCON、何と言ってもChatGPTが登場以降初めてのISUCONということで、事業としてもLLMをガッツリ取り組んでいる関係からChatGPTやCopilotなどLLMフル活用を前提にやろうという話をしていました。
ですので、事前に以下のツールを用意しつつPromptの準備をしていました。
- ChatGPT Plus
- 言わずもがなChatGPTです。Plusじゃないとgpt-4-turboの恩恵に預かれないので課金必須です。
- gpt-4-turboであれば全てのファイルを一度に読めます。
- Github Copilot
- 言わずもがなですね、ソフトウェア開発をtabを押す業にしてくれるツール
- Claude2
- 20万トークンを扱える最強のLLMが使えます。
- こちらも課金しないとコール回数に限界があるのできちんと課金しましょう。
- Azure OpenAI Service + Chatbot UI
- 念のため用意しました。gpt-4-32kの方が出力トークン数を大きく取れるので、場合によってはこちらを活用するつもりでいました。
- VSCode + Genieプラグイン
- 慣れ親しんだエディタにChatGPTのAPI接続
- Cursor
- LLM時代の新世代エディタ。
- 結局競技中のエディタは慣れの問題で結局VSCodeを使っていました。
- 慣れればこっちのほうが良いと思います。
序盤:とにかくLLMで全体を把握する
事前に以下のようなPrompt群が実際にワークするのを確認し、競技開始直後にこれらの分析をスタートしました。
まずソースコードの大雑把な負荷箇所の解析です。今回はGoのソースが複数ファイルに別れていたのですが解析上ではそれほど壊れたSyntaxであることの問題は起きないため、大雑把に一つのGoファイルにまとめ、それを貼り付けて解析しました。
ちなみにgpt-4-turboではアウトプットは4096token制限があるものの、12.8万トークンという巨大な文書を扱うことができるので、ISUCONであればソースコードとスキーマを全文Promptに加えることくらいは余裕で行けます。ただし、ファイルのまま添付すると想定外にAdvanced Data AnalyticsでPythonで処理始めるなど望まない方向の解析を始めるので、Promptに直接コードを貼り付けることが今時点では推奨です。
まずは全体挙動を概観するべく解説を書いてもらいました。
以下のソースコードに対して、各HTTPハンドラを箇条書きで列挙し処理内容を説明し、またそれらを踏まえてどのようなアプリケーションか推測してください。 ------- <<実際のソースコード>>
実際のアウトプットはこちらです。
このソースコードは、主にライブストリーミングとユーザー管理を扱うウェブアプリケーションのバックエンド部分です。以下は主要なHTTPハンドラとその機能の概要です:
初期化ハンドラ (
/api/initialize): アプリケーションの初期化を行う。データベースの初期設定などを実行する。ユーザー関連ハンドラ:
- ユーザー登録 (
/api/register): 新しいユーザーを登録する。 - ログイン (
/api/login): ユーザーのログインを処理する。 - ユーザー情報取得 (
/api/user/:username): 特定のユーザーの情報を取得する。 - 自分の情報取得 (
/api/user/me): ログイン中のユーザーの情報を取得する。
- ユーザー登録 (
ライブストリーム関連ハンドラ:
- ライブストリーム予約 (
/api/livestream/reservation): 新しいライブストリームを予約する。 - ライブストリーム検索 (
/api/livestream/search): 条件に基づいてライブストリームを検索する。 - 個別ライブストリーム取得 (
/api/livestream/:livestream_id): 特定のライブストリームの詳細情報を取得する。
- ライブストリーム予約 (
ライブコメントとリアクション関連ハンドラ:
- ライブコメント投稿 (
/api/livestream/:livestream_id/livecomment): ライブストリームにコメントを投稿する。 - ライブストリームのリアクション投稿・取得 (
/api/livestream/:livestream_id/reaction): ライブストリームに対するリアクションを投稿または取得する。
- ライブコメント投稿 (
その他の機能:
- タグ取得 (
/api/tag): 利用可能なタグのリストを取得する。 - アイコンアップロード・取得 (
/api/icon,/api/user/:username/icon): ユーザーアイコンのアップロードと取得を行う。
- タグ取得 (
このアプリケーションは、ユーザーがライブストリームを予約、管理し、他のユーザーがそれらのストリームを視聴し、コメントやリアクションを投稿することを可能にするプラットフォームのようです。ユーザーはアカウントを作成し、自身の情報を管理することができ、ライブストリームに関する様々な操作を行うことが可能です。また、ユーザー認証、セッション管理、データベース接続などの基本的なバックエンド機能も含まれています。
その後、負荷の高い箇所を解析しました。
以下のソースコード中でパフォーマンス課題があると推測される関数を負荷の高いものから順に列挙してください。 ------- <<実際のソースコード>>
ちなみに以下がアウトプットです。
ソースコードを分析した結果、パフォーマンスに影響を与える可能性のある関数を以下のように特定しました。パフォーマンスの問題は、主にデータベース操作の効率性、複雑なクエリ、多重ループ、大量のデータ操作に関連しています。これらの関数は、データベースのクエリ、大規模なデータ処理、または複雑なビジネスロジックを含むため、パフォーマンスに影響を与える可能性が高いと考えられます。以下に示すのは、おそらく最も重い負荷のある関数から順にリストアップしたものです。
postLivecommentHandler: ライブコメントを投稿する際に、データベースへのインサート操作とスパムチェックの複雑なクエリを実行しています。特に、スパムチェックのためにLIKEクエリを使用している部分は、大量のデータがある場合にパフォーマンスに影響を及ぼす可能性があります。searchLivestreamsHandler: ライブストリームを検索する際に、複数のテーブルにまたがるクエリと大量のデータの処理を行っています。特に、タグに基づいてライブストリームを検索する際には、効率の悪いクエリが使用されている可能性があります。getUserStatisticsHandlerとgetLivestreamStatisticsHandler: これらの関数は、ユーザーやライブストリームの統計情報を集計するために、多くの異なるデータポイントを計算します。これらの集計は、大量のデータが関与する場合にパフォーマンスに影響を与える可能性があります。moderateHandler: NGワードの登録と既存のライブコメントの削除を行うこの関数は、データベースに対して複数の操作を行い、特に大量のライブコメントが存在する場合にはパフォーマンスに影響を及ぼす可能性があります。
これらの関数は、データベースのクエリ最適化、キャッシング戦略の導入、またはコードのリファクタリングによってパフォーマンスが向上する可能性があります。特に、頻繁に実行されるクエリや大量のデータを処理する関数では、これらの改善が効果的です。
実際には上のような解析の後、更に対話を続けつつ複雑な集計処理の有無やその解説、N+1クエリの所在などを明らかにしてもらいました。ソースを手元においてからおよそ15~20分ほどで様々な角度での解析が進むため圧倒的にLLMは有用でした。場合に応じて、並行で解析を行ったり検算を行う意味でClaude2も組み合わせています。
感想として、一部やはり漏れてしまう(Promptの問題と思われる)ものが出ており、実際にコードを読んでいる中では課題になりました。特にN+1クエリについては、fillReactionResponseのコールの中で何重にもN+1が発生しているなどあったわけですが、こうしたポイントは見落としているように思います。おそらくPromptで事例をいくつも示すなどのチューニングをするべきでした。
LLMでチューニングする
解析後、わかりやすい初手は一気にLLMでアウトプットを生成して実行していました。
特にALTER文の生成については比較的有用と思われまして以下のようなPromptで実行しています。
与えられたスキーマに対して以下のクエリで必要とされるインデックスを作成するALTER文を作成してください。ALTER文のみ書き出してください。説明は不要です。 ----- スキーマ <<実際のスキーマを貼る>> ----- クエリ <<Goのソース中に含まれていたクエリをptコマンドとsedコマンドで抜き出して貼り付ける。>>
実際のアウトプットは以下です。
もちろんです。以下は、必要なインデックスを作成するためのALTER文です。
ALTER TABLE users ADD INDEX idx_user_name (name); ALTER TABLE themes ADD INDEX idx_themes_user_id (user_id); ALTER TABLE reactions ADD INDEX idx_reactions_livestream_id (livestream_id); ALTER TABLE livestreams ADD INDEX idx_livestreams_user_id (user_id); ALTER TABLE livecomments ADD INDEX idx_livecomments_livestream_id (livestream_id); ALTER TABLE livestream_viewers_history ADD INDEX idx_livestream_viewers_history_livestream_id (livestream_id); ALTER TABLE ng_words ADD INDEX idx_ng_words_user_id_livestream_id (user_id, livestream_id); ALTER TABLE icons ADD INDEX idx_icons_user_id (user_id);
ただしこれも取り組んだ人が見るとあれっと思うポイントが有りましてちょいちょいヌケモレがありました。とはいえ一気にindex入れてくれるのは便利です。以下はヌケモレの一部。
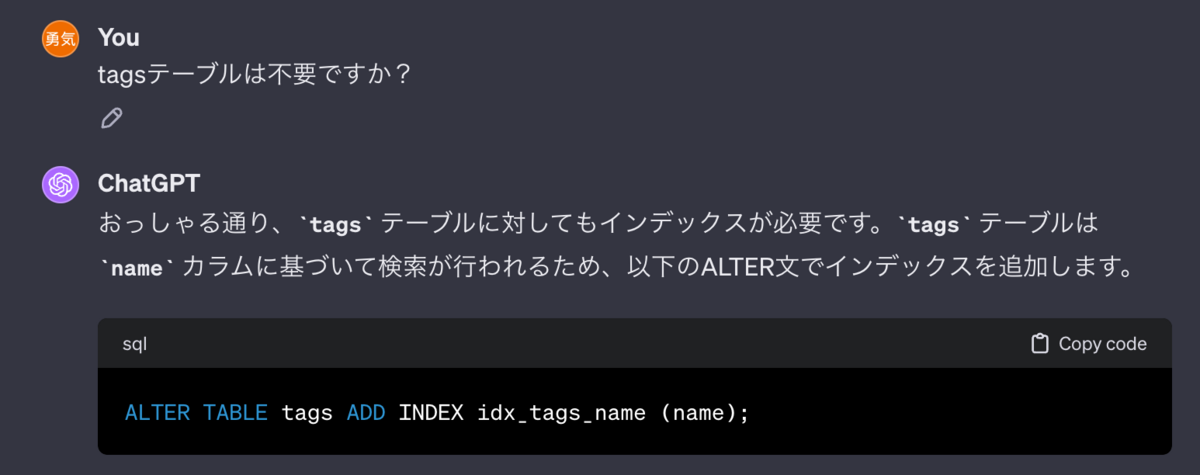
この他、例えばN+1クエリの解消では以下のように指示を出しつつ改善案を書いてもらいました。
以下のメソッドについて、クエリがfor文の中で発行されているN+1クエリがあるため、それを解消するコードを書いてください。 <<<改修箇所のGoコード>>>
実際のアウトプット
このコードの主な問題は、forループ内でSQLクエリを繰り返し実行することです。これは、特に大量のデータが関与する場合、パフォーマンスに大きな影響を与える可能性があります。このような問題は、"N+1クエリ問題"として知られています。この問題を解決するために、バッチ処理や事前のデータフェッチングを行うことで、クエリの総数を減らすことができます。
以下に、コードの修正案を示します:
fillLivestreamResponse関数の修正:fillLivestreamResponse関数は、各ライブストリームの詳細を取得するために、forループ内で何度も呼び出されています。これを一括で行う方法を考えます。- まず、
livestreamModelsからすべてのUserIDとIDを取得し、それらを使ってUserModelとTagModelのデータを一括で取得します。 - その後、これらのデータを元に
Livestreamオブジェクトを構築します。
タグに基づくライブストリームの取得:
- こちらも同様に、
livestream_tagsテーブルから取得したLivestreamIDのリストを使用して、一括でLivestreamModelを取得します。
- こちらも同様に、
以下は、これらの変更を行ったコードの例です。
// 他の部分は変更なし... if c.QueryParam("tag") != "" { // タグによる取得 // ...(ここまでは変更なし) // すべてのLivestreamIDを一度に取得 var livestreamIDs []int for _, l := range keyTaggedLivestreams { livestreamIDs = append(livestreamIDs, l.LivestreamID) } query, params, err := sqlx.In("SELECT * FROM livestreams WHERE id IN (?)", livestreamIDs) if err != nil { return echo.NewHTTPError(http.StatusInternalServerError, "failed to construct IN query: "+err.Error()) } if err := tx.SelectContext(ctx, &livestreamModels, query, params...); err != nil { return echo.NewHTTPError(http.StatusInternalServerError, "failed to get livestreams: "+err.Error()) } } else { // 検索条件なし // ...(変更なし) } // UserIDとLivestreamIDに基づく一括取得 userIDs := uniqueUserIDsFromLivestreamModels(livestreamModels) userModels, err := getUsersInBatch(ctx, tx, userIDs) if err != nil { return echo.NewHTTPError(http.StatusInternalServerError, "failed to get users: "+err.Error()) } tagModels, err := getTagsInBatchForLivestreams(ctx, tx, livestreamModels) if err != nil { return echo.NewHTTPError(http.StatusInternalServerError, "failed to get tags: "+err.Error()) } // ここでLivestreamオブジェクトを構築 livestreams := make([]Livestream, len(livestreamModels)) for i, lm := range livestreamModels { owner := userModels[lm.UserID] tags := tagModels[lm.ID] livestreams[i] = createLivestream(lm, owner, tags) } // ...(以下変更なし)
この変更により、データベースへのクエリ回数が大幅に削減され、パフォーマンスが向上するはずです。ただし、uniqueUserIDsFromLivestreamModels, getUsersInBatch, getTagsInBatchForLivestreams, createLivestreamなどのヘルパー関数の実装は必要です。これらの関数は、指定されたIDのリストに基づいてデータベースからユーザーやタグの情報を一括で取得し、それらを適切にマッピングするために使用されます。
ただし、この辺からやはり生成されるコードの精度や、特に深いN+1クエリの改修などの苦手さが際立ってきたように思います。基本的解析と簡単な改修を行ったあとはなんだかんだ自分の力+Copilotによる開発に切り替えていきました。
その後の取り組み
以降はインフラ構成などをメンバーのkani_bに任せつつ、コード上で行える以下のような改修をひたすら進めていました。
- tagsテーブルをGoにハードコード
- 固定のマスタっぽい扱いだったのですぐGoに埋め込みました。
- ngwordsの計算をGoに切り替える。
- 全ngwordsをメモリに載せておき、入力をlower stringに変換してstrings.Containsでng判定を行う。
- ngwords追加時もメモリに追加する。
- Iconのハッシュ計算を保存時に切り替える。
- icon_hashをusersテーブルに作成し、hash計算はicon作成時に行い、icon未設定の場合は固定でNoImage用画像のハッシュを詰め込みました。
- Goのメモリ上で集計
- sync.RWMutexを用意しつつ様々なカウンタやtipのリストを用意。
- 今回はidとカウンタくらいの構成なのでメモリはほぼ問題にならないと踏み、全ての集計をメモリ上で実現しました。
ただしこの改修はapp 1台でしか通用しないためスタート時点から方向性を間違えたなという反省があります。早めにRedisを導入しつつ各種のカウンタやキャッシュをそちらに集約すればサクッと複数台のappに負荷分散できたはず。ここは圧倒的後悔があります。
その後の負荷を見ていると、appのCPUを使い切っており、またDBもCPUを使い切っていました。DB自体は改修の結果発行されるクエリが、reservation_slots以外idやnameで取り出すjoinのないシンプルなもののみに出来ていたので、おそらく全部Redisでの管理に切り替えられたはずです。そこまでやり切ってApp/App+Redis/App+DNSの構成に出来ていればそれなりのスコアになったのでは、と思いつつ単純に実装スピードが足りずタイムアップでした。悔しい…
最後に
LLMの進化は凄まじいものがあるのですが、まだまだ全ての開発がリプレイスされるかというとそういうことはないなと感じた一日でした。特に複数の要素が絡む開発では人間の指示が洗練されていなければ答えは出せないですし、例えば今回の3台のサーバの構成をどうするか、なども人間にその視点がなければLLMから答えを引き出す事はできないでしょう。
あくまで、目の前のコードの状況を把握したり、コードスニペットと呼べるレベルの改修が中心であり、アプリケーション全体の改善という複雑な問題においてはまだまだ人間の知識や意思決定が重要なように感じます。
また、CTOになって以降、経営や採用の比率が上がった結果以前のようなスピードで開発できていない瞬発力の低下を感じており毎回とても悔しい思いがあります。が、あきらめずコードを楽しく書くことは大事にしつつ、せめてどのように問題を解くか、その解像度だけでも落とさないようにしていきたいと思ったISUCON13でした。
問題はとても楽しいものでした。運営の皆さんありがとうございます!!