機械学習エンジニアの吉田です。今回は機械学習モデルの推論サーバとして NVIDIA Triton Inference Server の性能を検証した話です。
(追記) 続編も書きました tech.layerx.co.jp
背景
バクラクでは請求書OCRをはじめとした機械学習モデルを開発していますが、これらの機械学習モデルは基本的にリアルタイムで推論結果を返す必要があります。 請求書OCRを例にとると、お客様が請求書をアップロードした際にその内容を解析し、請求書の金額や日付などを抽出します。
このような推論用のAPIサーバはNginx, Gunicorn/Uvicorn, FastAPIで実装し、PyTorchモデルをGPUで推論する構成となっており、SageMaker Endpointを使ってサービングしています。
バクラクの推論APIはこのような構成でリリース以降特に問題なく稼働してきていますが、ご利用いただくお客様が増えるにつれてリクエストも増加してきており、よりスケーラブルなシステムを構築する必要がでてきています。
また、本番で稼働する機械学習モデルも増えてきており、現状ではモデル毎にSageMaker Endpointでインスタンスを立てて運用していますが、今後も増えていくことを考えると効率的な運用が求められます。
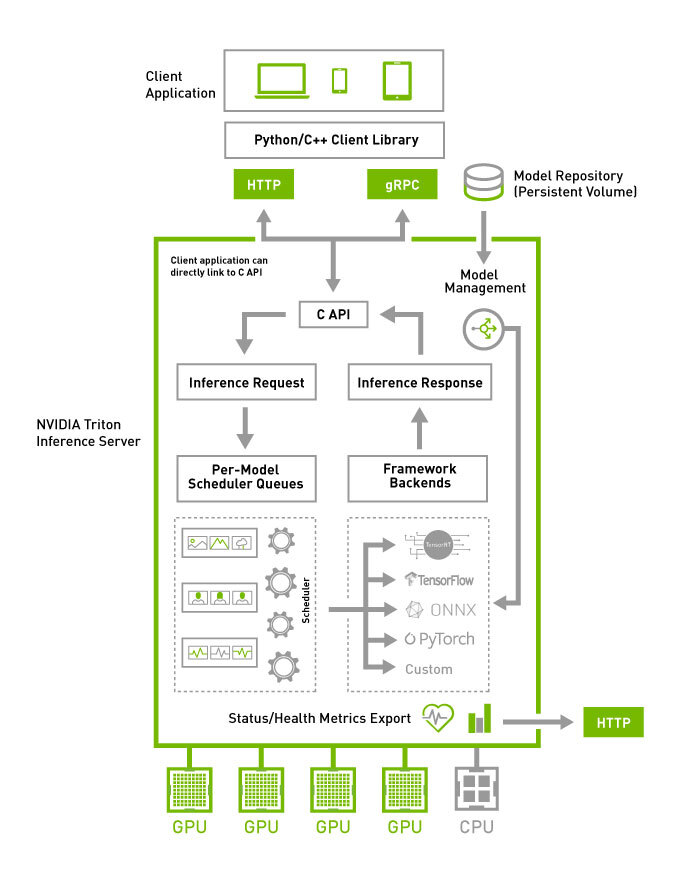
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server (以下 Triton) は、NVIDIAが提供するオープンソースの推論サーバで、PyTorch, TensorFlow, ONNX, TensorRTなどあらゆる機械学習フレームワークやライブラリで作成したモデルに対応しています。
TritonにはGPU/CPUの利用率を最大化しながら大量のリクエストを処理するためにリクエストキューを使った動的バッチ処理 (Dynamic batching) や、複数モデルの並列処理など高速な推論を実現するための機能が多く備わっています。
Tritonを推論サーバとして採用することで、スケーラビリティや効率性を向上させることができます。また、SageMaker Endpointへのデプロイも行うことができるため、現在の構成を大きく変更することなく導入することができるといったメリットもあります。
実験
Tritonの性能を検証するために以下のような実験を行いました。
概要
モデル
- ベースとなるPyTorchモデルは最大系列長512のRoBERTa largeを用いた分類モデル
- ONNXモデルはバッチサイズが可変で系列長256, 512の2通りのモデルをPyTorchモデルから変換
- TensorRTモデルはバッチサイズが1から8まで可変で系列長256, 512の2通りのモデルをONNXモデルから変換
実験環境
- 今回はGPUの推論処理に焦点を当てるため、input_ids, attention_maskをREST APIで受け取り、推論結果を返すだけのAPIサーバをSageMaker Endpointで構築
- SageMaker Endpointのインスタンスタイプは ml.g4dn.xlarge (NVIDIA T4, 4vCPU, 16GB) を使用
- ベースラインはNginx, Gunicorn/Uvicorn, FastAPIでAPIサーバを構築し、PyTorchモデルで推論
- TritonはONNX, TensorRTモデルで推論
- 今回のモデルにおいてPyTorchよりもONNX, TensorRTの方が低レイテンシであることは別途実験済みであったことからONNX, TensorRTのみ実験
- ベースラインとの比較においては、Tritonのサーバとしての性能差だけでなく、PyTorchとONNX, TensorRTのモデルの性能差も含まれることになります
実験方法
- モデルに入力する系列長によってレイテンシが大きく変わるため、(1, 256), (1, 512), (2, 512) の3通りの入力サイズで実験
- 性能指標はスループット (Requests Per Second, RPS) とし、Locustを使用して手元のPCから負荷をかけ、RPSが頭打ちにになったときのRPSとレイテンシ(ms)を記録
実験結果
1. 順次処理
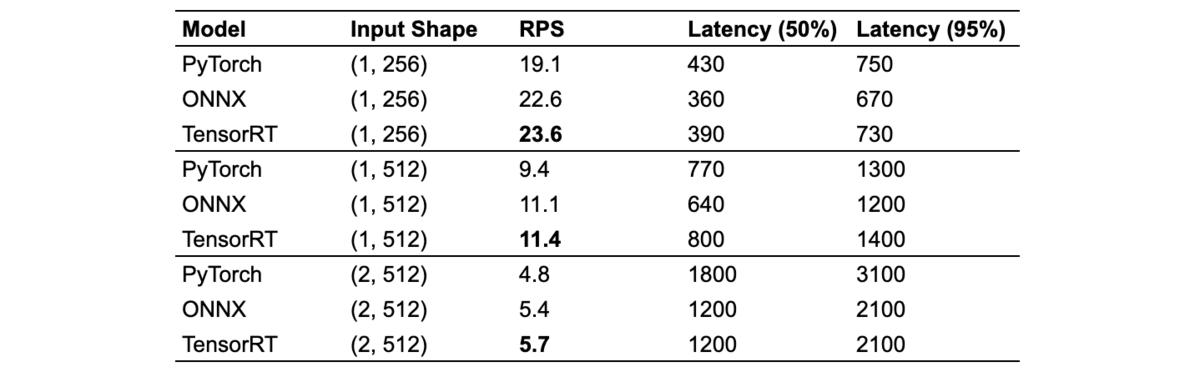
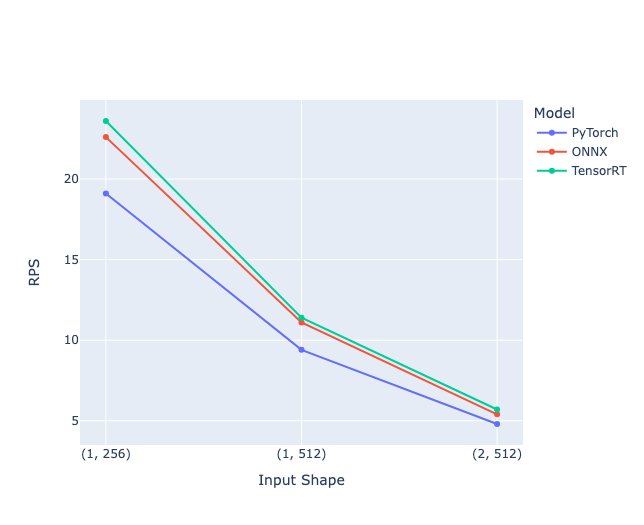
まず、動的バッチ処理を使わずにリクエストを1件ずつ順次処理する場合の実験です。PyTorchはFastAPIサーバ、ONNX, TensorRTはTritonサーバで推論を行っています。
- 当然ではありますが、どの入力サイズもONNX, TensorRTはPyTorchと比較してRPSが改善され、TensorRTが最も改善されています
- 入力サイズが小さいほど改善幅が大きく、(1, 256) におけるTensorRTのRPSはPyTorchの1.24倍、(2, 512) は1.19倍となりました
- スループットの改善だけでなく、ピーク時のレイテンシに関してもONNX, TensorRTはPyTorchと比較して同程度か小さい結果となり、入力サイズが (2, 512) の場合はPyTorchの2/3程度のレイテンシになっています
2. 動的バッチ処理
次にONNXモデルで動的バッチ処理の検証を行いました。動的バッチ処理はTritonの設定ファイルである config.pbtxt に以下のような設定を追加することで有効になります。
max_batch_size: 8 dynamic_batching: { max_queue_delay_microseconds: 150000 }
max_batch_size は処理可能な最大バッチサイズで、max_queue_delay_microseconds はリクエストをキューに入れておく最大遅延時間を指定します。 複数のリクエストが同時に来た場合、max_queue_delay_microseconds で指定した時間内にリクエストをまとめて処理することで、リクエストの処理効率を向上させることができます。 あまりにも遅延時間が長いとリクエストの処理が遅れるため、適切な値を設定する必要があります。
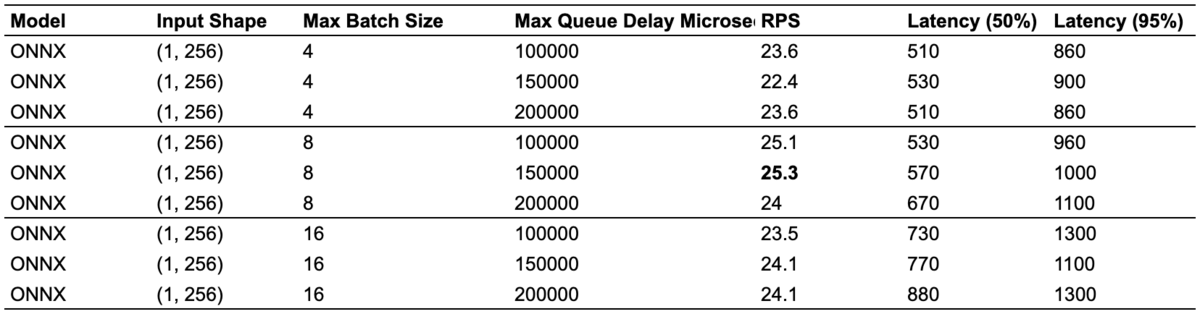
実験は、max_batch_size: 4, 8, 16 の3通りと max_queue_delay_microseconds: 100000, 150000, 200000 の3通りの全9通りの組み合わせで行いました。
- max_batch_size が大きくなるほどレイテンシは大きくなり、4 -> 8 ではRPSが改善しますが、8 -> 16 ではRPSが悪化しています
- ONNXモデルの場合、max_batch_size: 8, max_queue_delay_microseconds: 150000 が最もRPSが大きい結果となりました
負荷をかけた状況と実際の本番環境ではトラフィックが大きく異なるため、上記の結果が本番環境で有効かどうかは改めて検証が必要です。
3. 最終結果
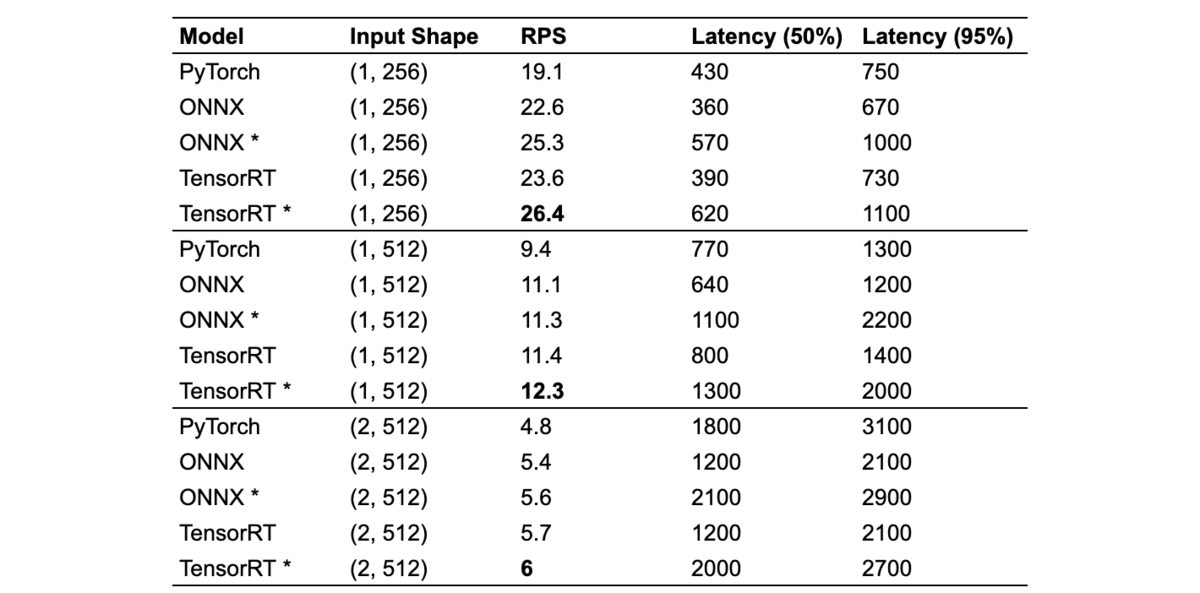
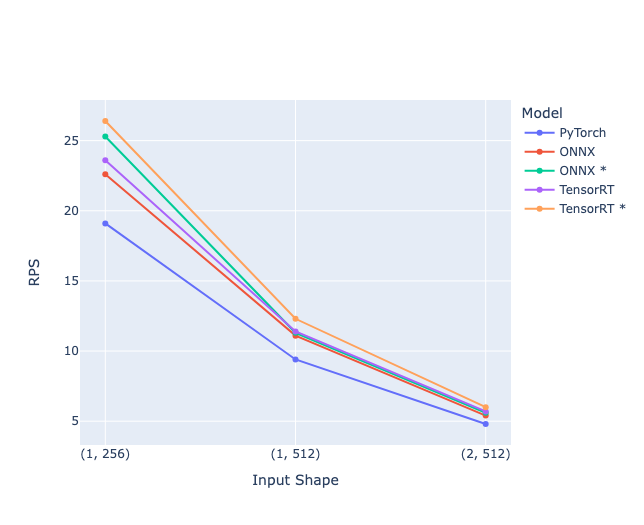
最終的な結果をまとめると以下のようになります。 モデル名の末尾にアスタリスク (*) がついているものは動的バッチ処理を有効にした結果です。 動的バッチ処理は前の実験を踏まえ一律 max_batch_size: 8, max_queue_delay_microseconds: 150000 に設定しています。 ONNXとTensorRTによるモデルの違いや入力サイズの違いでレイテンシが異なるため最適な動的バッチ処理の設定も異なる可能性がありますが、今回はある程度動的バッチ処理の効果がみれればよかったので一律同じ設定で検証しました。
- 動的バッチ処理を有効にすることで、ONNX, TensorRTのどちらのモデルにおいても、RPSが改善
- ONNX, TensorRTのどちらのモデルも (1, 256) では動的バッチ処理により約1.12倍のRPS改善がみられますが、 (1, 512), (2, 512) においては1.02 ~ 1.05倍の改善となっており、これはバッチサイズが増えることによる効率性よりもレイテンシ悪化の影響の方が大きいためと考えられます
- PyTorchと比較して最も改善が大きかったのは、TensorRT (1, 256) でRPSが 19.1 -> 26.4 と約1.38倍となりました
まとめ
ベースラインと比較してTritonではONNX, TensorRTモデルのどちらもRPSが改善され、特にTensorRTモデルは入力サイズ (1, 256) において最大で1.38倍RPSが改善しました。ただし、これはTritonのサーバとしての性能だけによるものだけではなく、PyTorchとONNX, TensorRTのモデルの性能差によるところもあることは補足しておきます。多様な形式のモデルを容易に切り替えることができるのはTritonの大きなメリットです。
実験結果には入れませんでしたが、Tritonにはリクエストを並行処理するためのインスタンスグループという機能もあり、こちらも試してみましたがスループットは改善しませんでした。 今回はGPUの推論処理のみで元からGPUの使用率が高く並行処理の効果はなかったものと考えられます。
また、Tritonには推論だけでなく前処理や後処理をPyThonで実装し、パイプラインを組むこともできるため、この場合の性能評価も行ってみたいと考えています。
さいごに
機械学習チームでは機械学習エンジニアやMLOpsエンジニア、ソフトウェアエンジニア、インターン生を積極採用中です! 興味を持たれた方は是非カジュアル面談からでもお気軽にどうぞ!