こんにちは! LayerXで機械学習エンジニアをしている伊藤 (@sbrf248) です。直近はOCRモデルの学習・評価に使うデータセット周りの改善に取り組んでいます。
今回は、データセット作成におけるアノテーションに注目し、関連する研究分野や、LayerXにおける改善にどう繋げられそうかを紹介したいと思います。
アノテーションに関する研究分野
アノテーションは、機械学習に利用する教師付きデータの正解ラベルを人間が付与する作業を指します。 高い精度のモデルを作るためには高品質かつ大量のデータセットが用意できると理想ですが、人間が作業する以上一定の時間的・金銭的コストは必要になるため、品質を高めつつ効率を上げるための工夫が必要になります。
アノテーション品質・効率を高めるための研究分野は、大きくサンプリングと品質管理と効率化の2つに分けられます。 以下では、それぞれについての代表的な手法や最新の論文をいくつか紹介したいと思います。
サンプリング
ラベルの無いデータから学習に効果的なデータを重点的にアノテーションできると、少ない労力で大きな効果が期待できます。 それを目指す手法はActive Learning(能動学習)と呼ばれており、これまで数多くの手法が提案されています。
「効果的なデータセット」の基準は、主に「不確実性」と「多様性」との2種類で計測されます。
- 不確実性: 機械学習モデルにとって予測が難しいデータほど不確実性が高い
- 多様性: 選ばれたデータの特性が互いに異なっているほど多様性が高い
以前の社内勉強会で紹介させていただいた『Human-in-the-Loop機械学習』[1] では、それぞれについて代表的な手法がいくつか紹介されていました。
不確実性に注目した手法は、例えば機械学習モデルの出力(ラベル毎の予測スコア)を使い、 ”最も大きいスコアがどれだけ小さいか” を不確実性とする「最小確信度サンプリング」があります。 多様性に注目した手法は、データをクラスタリングした上で、得られたクラスタごとにサンプリングする「クラスタベースのサンプリング」が代表的です。
加えて、よりバイアスを減らすため、最小確信度で多めにサンプリングした後クラスタベースのサンプリングで絞る、といった両者を組み合わせる方法も実践的なアプローチとして紹介されており、ユースケースによって様々な選択肢が存在しています。
最近の研究では、CVPR2023にて、事前学習済みモデルのファインチューニングを前提としたサンプリング手法である Active Finetuning が提案されました[2]。
この手法は、まずファインチューニングしたい事前学習済みモデル(論文ではtransformerベースの画像認識モデルを利用)を使って、サンプリング対象のラベル無しデータ全体をエンコードし、特徴ベクトルに変換します。得られた特徴ベクトルに対して
- データ全体の分布とサンプリングされた部分集合の分布が近くなる(KL-divergenceが小さくなる)
- サンプリングされたデータは、互いに類似度(内積)が低くなる
ようなサンプリングを最適化問題で解いているのが、大まかな方針です。
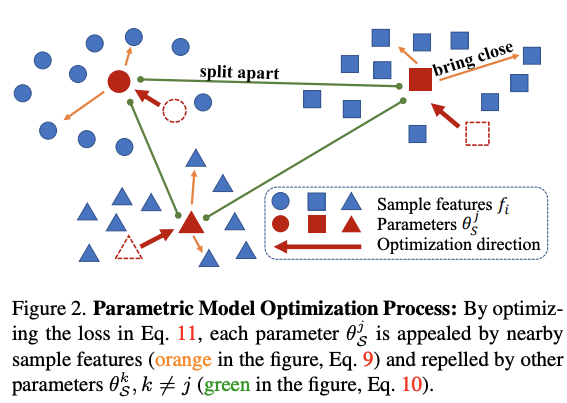
ここでは手法の詳細には入りませんが、サンプリングを選ぶ問題が離散最適化問題になってしまうところを連続最適化問題として解けるように変換している部分も、この研究の大きな貢献ポイントになっています。
品質管理と効率化
アノテーション作業は人手で行うため、同じデータでもミスや解釈の違いで誤ったラベルが付与される場合があり、品質を高める上での課題になります。 特に、セグメンテーションや物体検出のような複雑なラベルを扱うアノテーションでは、効率よく作業ができるタスクの設計も重要になります。
品質を高める観点では、主に匿名のクラウドワーカーが作業を行うクラウドソーシングの文脈で盛んに研究されてきました。 クラウドソーシングでは、1つのデータに対して複数人がアノテーションを行い、得られたラベルを集約する方法が主流です。
単純な集約方法は多数決(一番多く付与されたラベルを選ぶ)ですが、1つのデータに割り当てられるアノテーターの人数が少ないと、間違ったラベルの影響を受ける確率が高くなってしまう課題があります。
その課題に対する手法として、事前に推定された能力(正解率)の高いアノテーターに高い重みをつけて多数決をとる方法[3]や、アノテーターの能力と真のラベルを同時に推定する方法[4]などが提案されています。特に後者の手法は、アノテーターの能力の推定が難しいクラウドソーシングの文脈では主流なアプローチの1つで、タスクの難易度を取り入れた手法[5]など、様々な派生モデルが提案されています([6]では様々な関連手法が紹介されています)。
HCOMP2023では、医療画像のセグメンテーションに関するアノテーション手法が提案されていました[7]。胸部CT画像のような医療画像は、セグメンテーションしたい領域の境界線が曖昧なことが多く、アノテーターによるブレが多く発生してしまう課題があります。
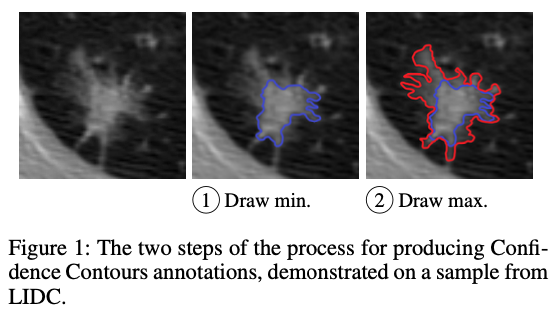
この研究では、「これより内側は確実に対象が含まれているmin境界」と「これより外側は確実に対象が含まれていないmax境界」の2種類をアノテーションする、境界の曖昧さを直接表現できる手法を提案しています。アノテーションする境界の個数が増えたため、1枚あたりの時間はやや増加(境界線1つあたりにすると減少)する結果となっていますが、アノテーター間の境界線の一貫性は改善が見られ、またデータの解釈性も向上したと報告されています。
アノテーション効率を高めるという観点では、EMNLP2023でLLMを用いたフレームワーク CoAnnotation が提案されています[8]。CoAnnotation は、最初にLLMを使ったアノテーションの不確実性を判定するステップを挟み、不確実性の低い一部のデータのみLLMでアノテーション、残りを人間がアノテーションする、といった構成になっています。
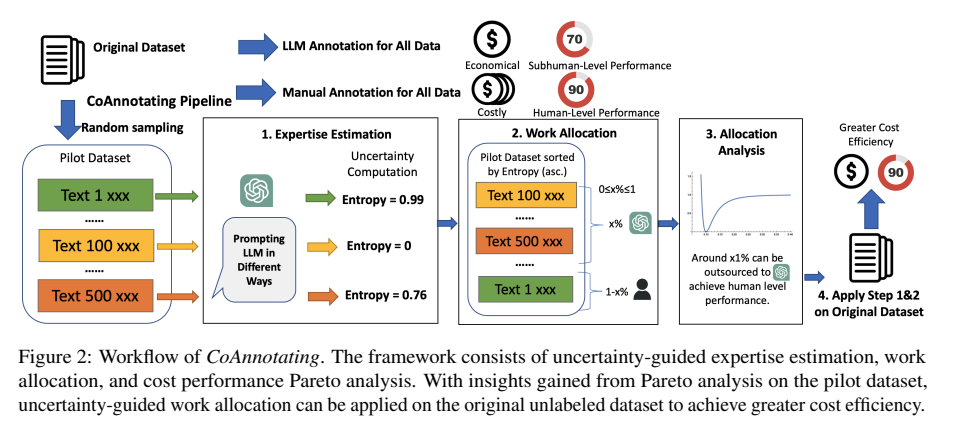
LLMによるアノテーションの不確実性はk個のプロンプトによる出力がどの程度変化するかで計測され、変化の少ないデータであればLLMでも比較的高い精度でアノテーションできると考えられるため、人間 vs. LLM の比率を適切に選べばコスト対効果を最大化できることが実験的に示されています。
LayerXにおけるアノテーション改善の方向性
ここまで紹介したアノテーションに関する研究分野を踏まえて、LayerXにおけるアノテーション改善の方向性を考えていきたいと思います。
アノテーションの現状
現在、アノテーションデータの作成は内製ツールを利用しており、社内アノテーターの方々を中心に日々アノテーション作業を行なっています。
私も実際に内製ツールを使ってアノテーション作業を行なってみましたが、記事で紹介されている通り、OCRによる事前アノテーションや入力補完機能、座標・文字抽出機能によって、想像していたよりもはるかに手軽にアノテーションが実施できました。とはいえ、アノテーションデータの選択や作業の質・効率を高める工夫の観点からはまだまだ改善点はあると考えています。
サンプリング
バクラクにはお客様からアップロードいただいた書類が数多く蓄積されていますが、アノテーション対象となる書類はアップロード日時といった粗い単位で選ばれており、不確実性や多様性といった観点はまだ入れられていないのが現状です。
書類データの場合、例えば過去の推論結果を利用した不確実性サンプリング、書類のフォーマット (書類の種別や言語、レイアウトなど)が極力ばらつくような多様性サンプリングなどが、方向性として考えられそうです。
また、OCRモデルはRoBERTaをファインチューニングしたものを使っているため、Active Finetuning のような手法も適用可能かもしれません。
品質管理と効率化
内製ツールのおかげである程度手軽にアノテーションができる状態にはなっていますが、まだまだ改善できる部分は残られています。
例えば、日付や取引先名が複数書かれているケースなどでは、どれを選ぶべきかの判断に迷うケースがあります。 現在は都度メンバーと連携して判断しつつ、必要であればマニュアルに追加する運用になっていますが、過去の似たようなアノテーション済み書類を元にサジェストされる機能であったり、部分的にLLMを使って予測するといった、アノテーターの負担を減らすような機能が考えられそうです。
他にも、連続でアノテーションを行う場合に似たレイアウトのものを連続して表示させるとアノテーターがラベルを判断しやすくなり認知負荷が下がる、といった観点での改善案も考えられると面白そうだと感じています。
最後に
最後になりましたが、機械学習チームでは一緒に働く機械学習エンジニア・MLOpsエンジニア・ソフトウェアエンジニアを積極採用中です! 今回紹介したアノテーションやデータセットの品質に関する分野に少しでも興味を持っていただけたら、是非お話ししましょう!
参考文献
- [1] Robert (Munro) Monarch 著, 上田 隼也 訳, 角野 為耶 訳, 伊藤 寛祥 訳: Human-in-the-Loop機械学習, 共立出版 (2023)
- [2] Xie, Y., Lu, H., Yan, J., Yang, X., Tomizuka, M., Zhan, W.: Active Finetuning: Exploiting Annotation Budget in the Pretraining-Finetuning Paradigm, CVPR (2023)
- [3] Snow, R., O’Connor, B., Jurafsky, D. and Ng, A.: Cheap and fast ─ But is it good? Evaluating non-expert annotations for natural language tasks, EMNLP(2008)
- [4] Dawid, A. P. and Skene, A. M.: Maximum likelihood estimation of observer error-rates using the EM algorithm, J. Royal Statistical Society, Series C(Applied Statics),Vol. 28, No.1, pp. 20-28(1979)
- [5] Whitehill, J., Ruvolo, P., Wu, T., Bergsma, J. and Movellan, J.: Whose vote should count more: Optimal integration of labels from labelers of unknown expertise, NIPS 22(2009)
- [6] 小山聡, ヒューマンコンピュテーションの品質管理(<特集>ヒューマンコンピュテーションとクラウドソーシング), 人工知能, 2014, 29 巻, 1 号, p. 27-33
- [7] Ye, A., Chen, Q. Z., Zhang, A.: Confidence Contours: Uncertainty-Aware Annotation for Medical Semantic Segmentation, HCOMP (2023)
- [8] Li, M., Shi, T., Ziems, C., Kan, M.-Y., Chen, N., Liu, Z., Yang, D.: CoAnnotating: Uncertainty-Guided Work Allocation between Human and Large Language Models for Data Annotation, EMNLP (2023)