機械学習エンジニアの吉田です。
この記事はLayerXテックアドカレ14日目の記事です。前回は @shnjtk による ストーリーポイントではなくアウトカムで開発速度を測る でした。次回は osuke さんが担当します。
今回はバクラクの帳票画像を使ってDALL-EのdVAE (discrete Variational AutoEncoder) を学習させた話をご紹介します。
背景
前回 バクラクのデータセットを用いたLayoutLMv3による事前学習 という記事を書きました。 tech.layerx.co.jp
この記事にあるように、 LayoutLMv3*1のMasked Image Modeling (MIM)の事前学習では画像トークナイザーとして学習済みのDALL-EのdVAEを使っていました。
しかし、オリジナルのLayoutLMv3では文書画像で事前学習されたDiT*2の画像トークナイザーを使っており、DALL-EのdVAEと比較してより鮮明に画像を再構成できたとあります。
以下の図はDiTの論文から引用した図で一番左が元画像で続いてDiT, DALL-EのdVAEで再構成した画像となっています。

そこで、DiTが文書画像を使って学習させたように、バクラクのデータセット (主に帳票) を使ってDALL-EのdVAEを学習させることによって、帳票に適した画像トークナイザーを獲得し、自前で事前学習させるLayoutLMv3の性能も高められるのではないか、というのがモチベーションになります。
DALL-E

まず、DALL-E*3とはどのようなモデルであるのか簡単に説明します。
DALL-EはWebから大量の画像とテキストを収集し、Transformerをベースとしたモデルを学習させることで従来の手法よりもはるかに高精度なtext-to-imageの性能を達成しました。
DALL-Eではテキストと画像のトークンを単一のデータストリームとして自己回帰的に系列を生成するのですが、ここで画像のピクセルをトークンとしてしまうと高解像度の画像に対して膨大なメモリが必要となるため現実的ではありません。
また、画像のピクセル間の短距離依存性を学習することにモデルのキャパシティの多くが費やされてしまい、大域的な特徴を捉えることが困難になるという問題もあります。
これらの問題に対処するためにDALL-Eでは以下の2段階の学習を行っています。
Stage 1
256 x 256のRGB画像を品質を大きく低下させることなく32 x 32の画像トークンに圧縮できるようにdVAEを学習します。
これによってコンテキストサイズを1/192に削減することができます。
Stage 2
Byte Pair Encodingでエンコードされたテキストトークン(最大256トークン)と32 x 32 = 1024の画像トークンを連結し自己回帰的にTransformerを学習させます。
今回はdVAEを学習できればよいので、Stage 1だけ行います。
dVAEの実装
公式のDALL-Eのリポジトリ*4にはエンコーダ、デコーダの実装は公開されていますが、学習用のコードは公開されていません。今回はDiTのdVAEの学習でも使用されているオープンソースのPyTorch実装*5があるのでこちらを参考にしました。
エンコーダは複数の畳み込み層と残差ブロックから構成されており、公式のDALL-Eのエンコーダの実装*6と比較するとMax Poolingは使われておらず、層の数が少なくシンプルなアーキテクチャとなっています。
エンコーダの最後の畳み込み層からは32 x 32 x 8192の特徴マップが出力されます。ここで8192は潜在変数 (画像トークン) の取りうる値の数であり、潜在変数をK=8192のカテゴリ分布と仮定しています。
そして潜在変数の数だけ埋め込みベクトルを用意します。この埋め込みベクトルはコードブックと呼ばれ、参考実装ではベクトルの次元を512としていました。
出力された特徴マップから適切な埋め込みベクトルにマッピングするのですが、学習時の問題として、エンコーダから出力されたロジットのargmaxでコードブックを選択してしまうと、微分することができず勾配を計算することができなくなってしまいます。そこでDALL-EではGumbel-Softmaxという手法を用いることで微分可能としています。
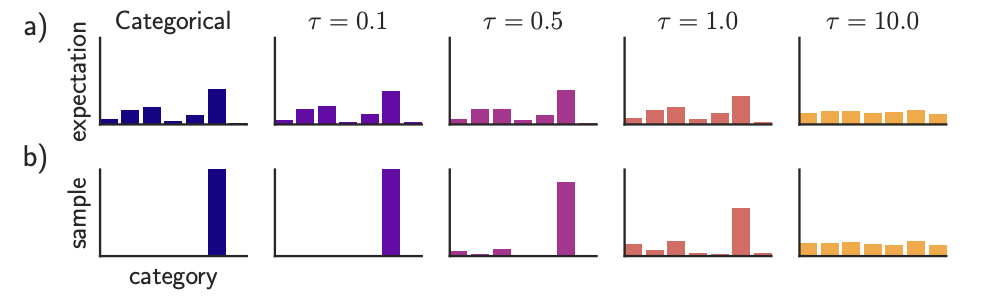
Gumbel-Softmaxは温度パラメータτが0のときはカテゴリ分布となり大きくしていくと一様分布に近づくように分布が変動します。
以下の図*7は温度パラメータτを変えたときの期待値とサンプルとなります。温度パラメータが低いと期待値はカテゴリ分布に近づき、サンプルはone-hotなベクトルに近づくことが分かります。
学習の初期は温度パラメータを大きくし徐々に小さくすることで安定して学習することができるようになり、最終的にカテゴリ分布に近づくように学習を行うことができるようになります。
また、潜在変数の事前分布を一様カテゴリ分布とし、エンコーダが生成した事後分布を近づけるためにKLダイバージェンスを損失に追加しています。このKLダイバージェンスの損失の重みを学習時に徐々に上げていくと最終的な再構成誤差が小さくなったと論文にはあります。
以上の学習コードは train_vae.py *8 に実装されています。
検証
バクラクの帳票画像を約50万枚用意し、画像サイズを256 x 256、バッチサイズ4で1epoch、V100で4時間程度で学習しました。それ以外のハイパーパラメータは参考実装の初期値をそのまま使っています。
KLダイバージェンスを損失に追加するとうまく学習させることができなかったため再構成誤差だけで学習しています。 (KLダイバージェンスがうまく機能しない件についてはissue*9でも同様の報告がありました)
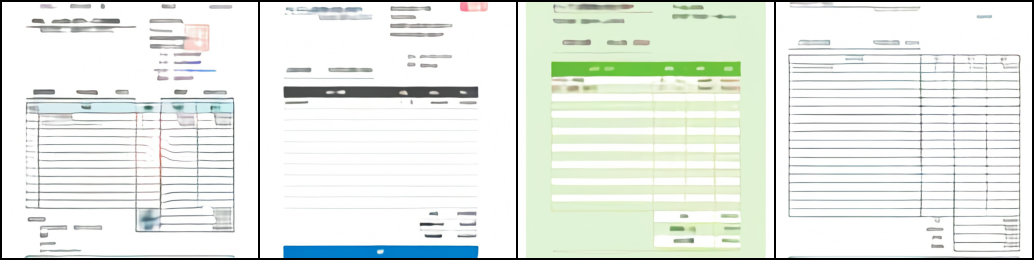
学習過程の可視化
検証用に学習データセットに含まれていない画像を4枚用意し、100step毎に学習途中のモデルを使って検証用の画像を再構成しました。 以下にそのうちの何枚かピックアップしていますが学習が進むにつれて画像の線や文字、色が鮮明になっていく様子がわかります。 50000step以上は目視では違いがあまり分かりませんでした。
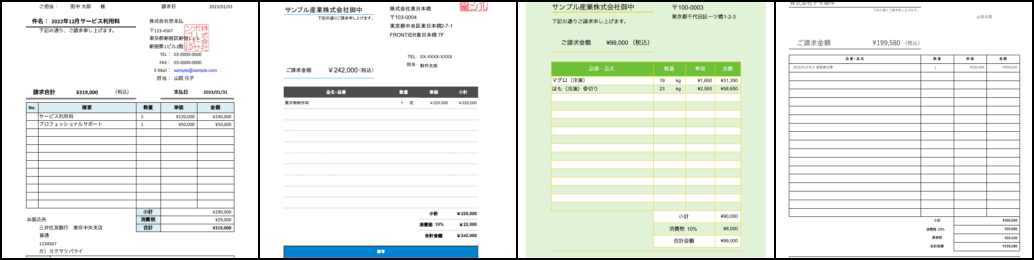



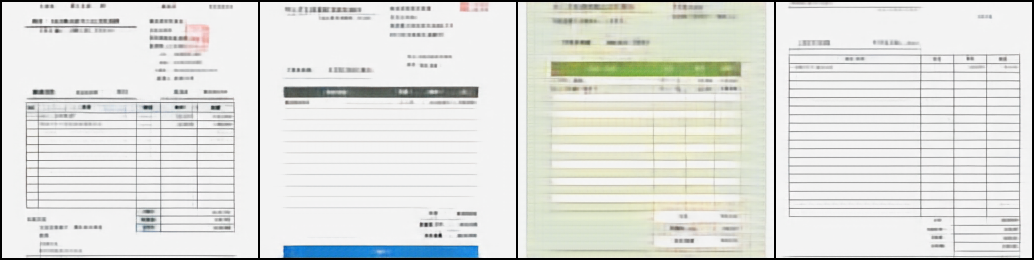
DALL-Eとの比較
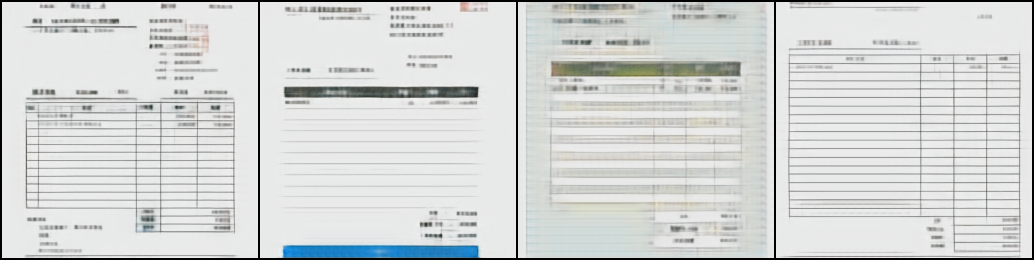
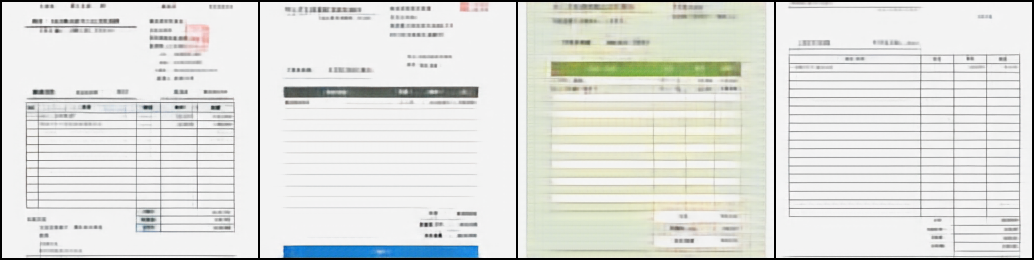
上から元画像、DALL-Eの学習済みdVAE、バクラクのデータセットで学習させたdVAEの結果を並べたものになります。
DALL-Eの結果はコントラストが高く色味はよく再現できていますが、罫線が歪んだりかすんだりしてしまっています。また、文字も潰れてひとつづきとなってしまっています。
一方でバクラクのデータセットで学習させたdVAEは罫線が歪んだりせずにはっきりしており、またひとつひとつの文字もある程度分離できています。
失敗例
上に挙げたのは成功例なのですが、ハイパーパラメータを変更すると学習に失敗することが多かったです。
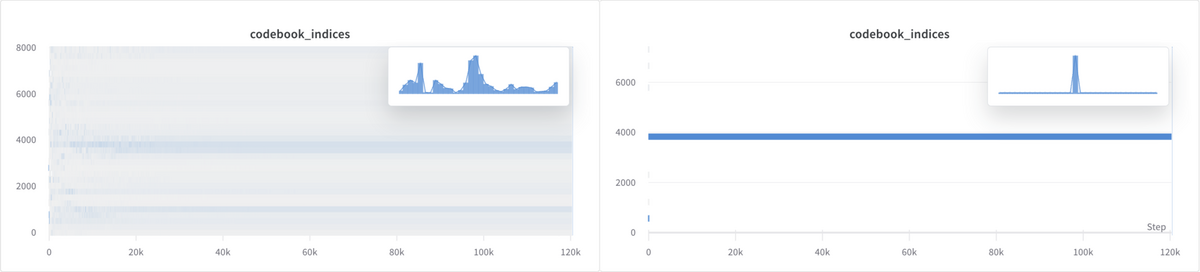
学習がうまくいかないケースとして多かったのが、次第に取りうるコードブックの多様性がなくなり、単一のコードブックに収束してしまうパターンです。
下図は横軸が学習のstep数で縦軸がコードブックのヒストグラムとなっており、左側が正常に学習が進んでいるときの分布で右側が学習に失敗しているときの分布です。
このような状態になると復帰することができなくなり、画像も復元できずに真っ黒な画像になってしまいます。
論文にあるようにKLダイバージェンスの損失を加えるとコードブックの多様性は促進されるのですが、それはそれで学習がうまくいきませんでした。
まとめ
本記事ではバクラクの帳票画像を使ってdVAEを学習させた話をご紹介しました。
実際に試してみるとうまく学習できないときも多くロバストに学習させるのが難しかったですが、特定のドメインに特化したデータセットであれば大規模でなくともdVAEを学習させることができることが分かりました。
次は実際に学習したdVAEを使ってLayoutLMv3の事前学習を改めて検証したいと思います。
最後に
機械学習チームでは機械学習エンジニアやMLOpsエンジニア、ソフトウェアエンジニア、インターン生を積極採用中です! 興味を持たれた方は是非カジュアル面談からでもお気軽にどうぞ!
jobs.layerx.co.jp jobs.layerx.co.jp
*1:https://arxiv.org/abs/2204.08387
*2:https://arxiv.org/abs/2203.02378
*3:https://arxiv.org/abs/2102.12092
*4:https://github.com/openai/DALL-E
*5:https://github.com/lucidrains/DALLE-pytorch
*6:https://github.com/openai/DALL-E/blob/master/dall_e/encoder.py
*7:https://arxiv.org/abs/1611.01144
*8:https://github.com/lucidrains/DALLE-pytorch/blob/main/train_vae.py