こんにちは、全ての経済活動をデジタル化したいTomoakiです。 今回はバクラクで内製しているアノテーション基盤を紹介します。
バクラクのOCR
バクラクでは請求書や領収書をはじめ、国税関係書類に対してOCRを実行し入力のサジェストを行うことで、ユーザーが書類の内容を手入力する手間を省いています。例えばこちらの領収書、日付、金額、支払先を自動で読み取ってユーザーにサジェストをしています。

なぜアノテーション基盤が必要なのか
バクラクのOCRでは自前で機械学習モデルを作成しているため、学習用・検証用のデータセットが必要になります。
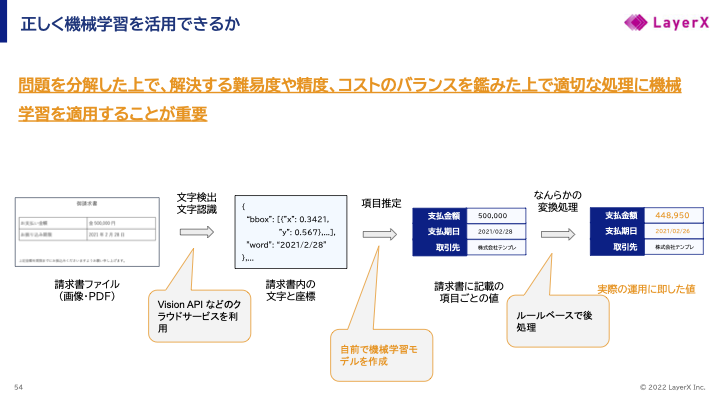
OCRに必要なこれらのデータセットはどのようにして作るのが良いでしょうか。
お客様が最終的に入力した値を正解ラベルとするのはどうでしょうか? 例えば冒頭のレシートの場合、私は7010円として経費精算を申請したので、7010円をそのまま正解ラベルとするといった具合です。
しかし、国税関係書類に対するOCRの難しいところは、お客様の入力値が必ずしも実施に請求書に書いてある値と一致するわけではないということです。 例えば、請求書には支払金額5000円と書いてあっても、お客様の都合で金額を変更する場合があります。これは、前月の繰越分を差し引いたり、源泉徴収税を差し引いたりと理由もさまざまあります。
よって、OCRというタスクおいてはお客様の入力値をそのまま正解ラベルとして扱うことはできません。もちろん最終的に、お客様が欲しい値を推薦するタスクは別途必要ですが、ここはあくまでOCRという書いてある情報をそのまま読み取る(文字認識→項目推定)タスクのみを考えます。
お客様の入力値が必ずしも請求書に書いてある値と一致しない例は、決してレアケースではなくお客様によってはほぼ全ての書類に対して記載されていない値を入力する場合もあります。詳しくはこちらをご覧ください。 tech.layerx.co.jp
また、LayoutLMといったマルチモーダルなモデルを利用する場合、テキスト情報とその位置情報が必要になりますが、お客様の入力した値を利用する場合、その値の座標の取得が困難です。例えば、お客様が1000円と入力したとして、帳票に1000円と書いてある箇所を探してその座標を正解ラベルとする、といった方法も考えれますが、1000円という文字列が複数あった場合、どちらの1000円の座標を正解とすべきか判断することができないので限界があります。
したがって、OCRに必要なデータセットを作るにはアノテーション作業が必要になります。
バクラクのアノテーション基盤(通称:バクラクデータ管理)
アノテーション基盤とは一般に画像やテキストなどのデータに対して、人間が付与するタグやラベル、注釈などの情報を管理するプラットフォームです。 今回我々が作成したバクラクデータ管理では、帳票の金額・日付など10種類以上の項目に対して以下の値をアノテーションしています。
- バウンディングボックス(座標)
- ラベル情報(文字列・数字など)
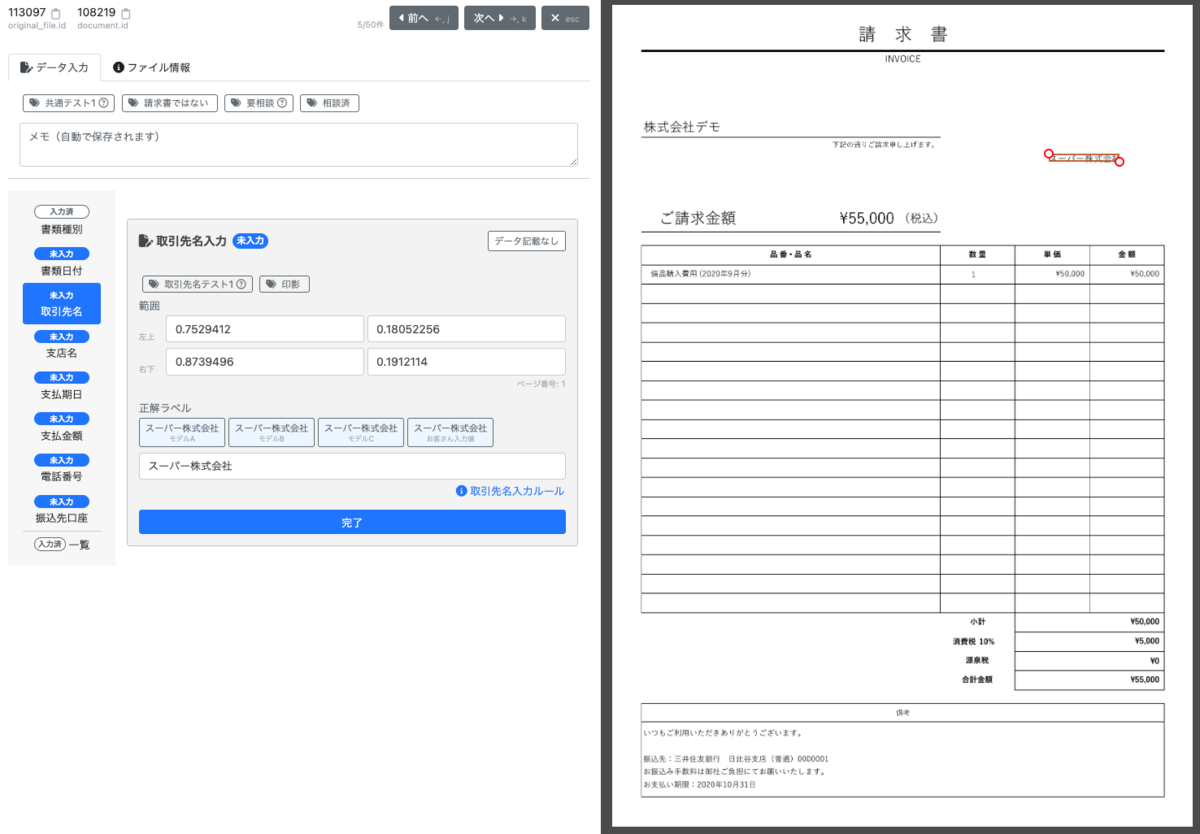
アノテーション作業は想像以上に大変です。全ての項目を手入力していると一枚あたり数分、情報量が多い時は10分近くかかってしまうことも少なくありません。 社内用のアノテーションツールもプロダクトであり、目指すは手入力ゼロ、バクラクな体験を目指しました。
工夫した点
徹底的に手入力をなくす
①:事前アノテーション
事前にOCRをかけておき、OCRが読み取った座標とラベルを事前に入力しておくことで、OCRが間違えている場合のみ修正するだけで作業が完結するようにしています。この時点でアノテーション作業は格段に減少します。OCRの精度が100%であれば何も変更することなく、作業が終了します。
②:入力補完機能
①で事前アノテーションした値が間違っていた場合修正が必要になります。ここで修正の候補として、他のモデルの推論結果やお客様の入力値を表示します。 バクラクのOCRでは毎回複数のモデルで推論を行なっているため、仮に①で事前アノテーションに利用されたモデルが間違っていたとしても他のモデルの値を候補に出し、ワンクリックで切り替え可能にすることで、入力の負担が大幅に減ります。

③:座標・文字抽出機能
座標抽出
画像に対して四角い枠線で囲むと自動で、その座標が入力されます。レイアウトを考慮したモデルを作成する際には座標の情報が重要になるので簡単に座標を入力できる仕組みを開発しました。
動画の左側の座標入力画面をご覧ください。最初は0で埋められていますが、右側の請求書に対してアノテーションしたい箇所を赤枠で囲むと自動で座標が算出され入力がされます。
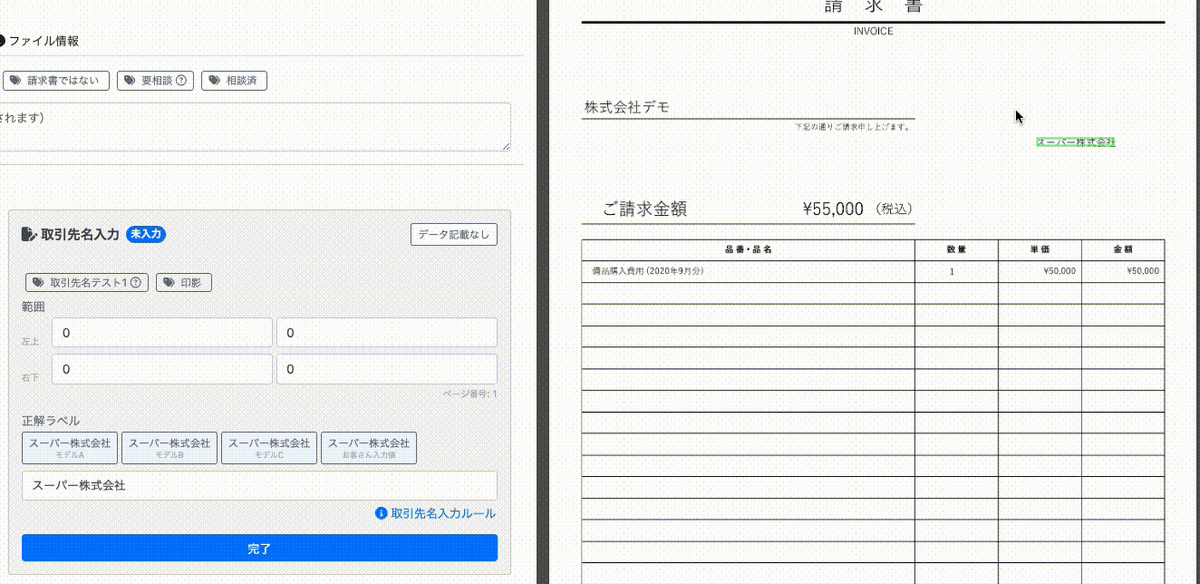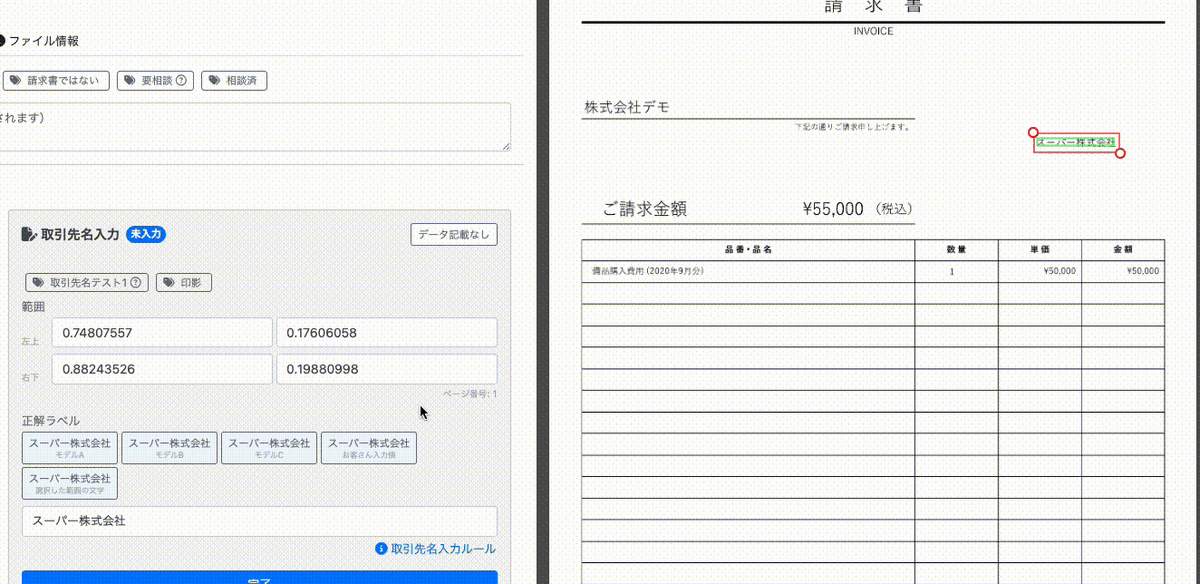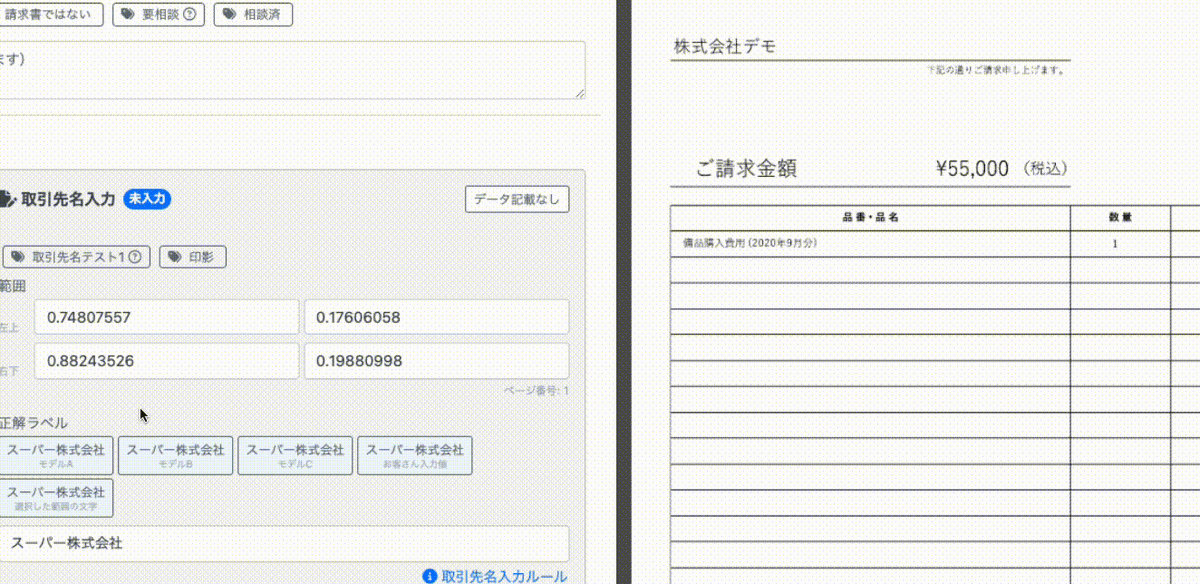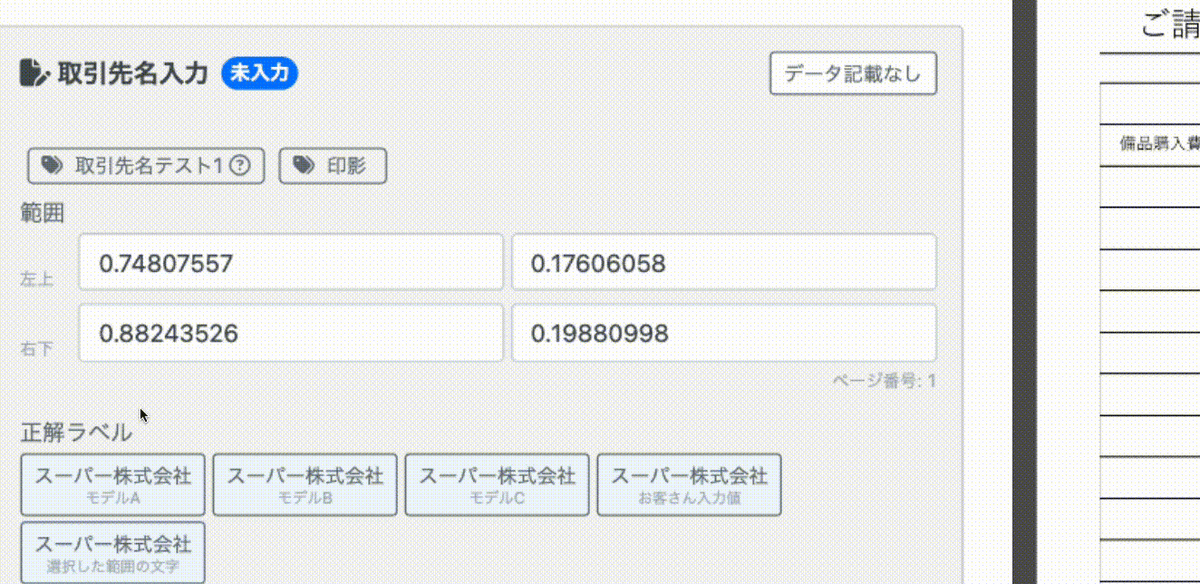
文字抽出
選択した座標内にある文字を自動で計算し、入力においてサジェストをすることで手入力の負担を軽減しています。
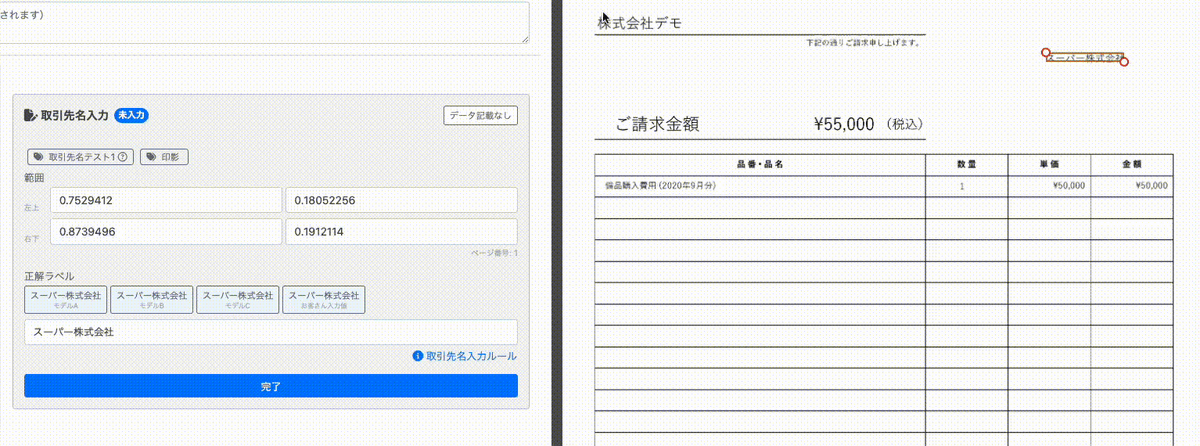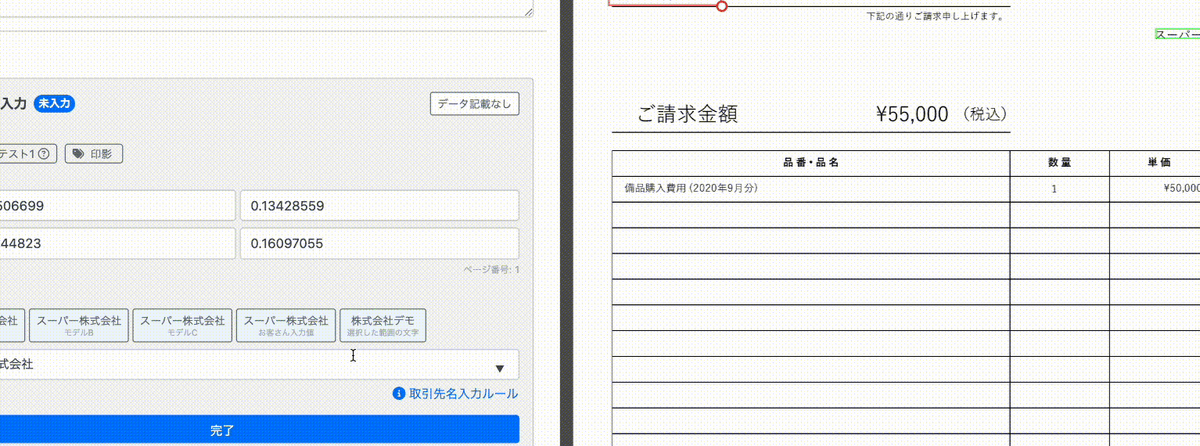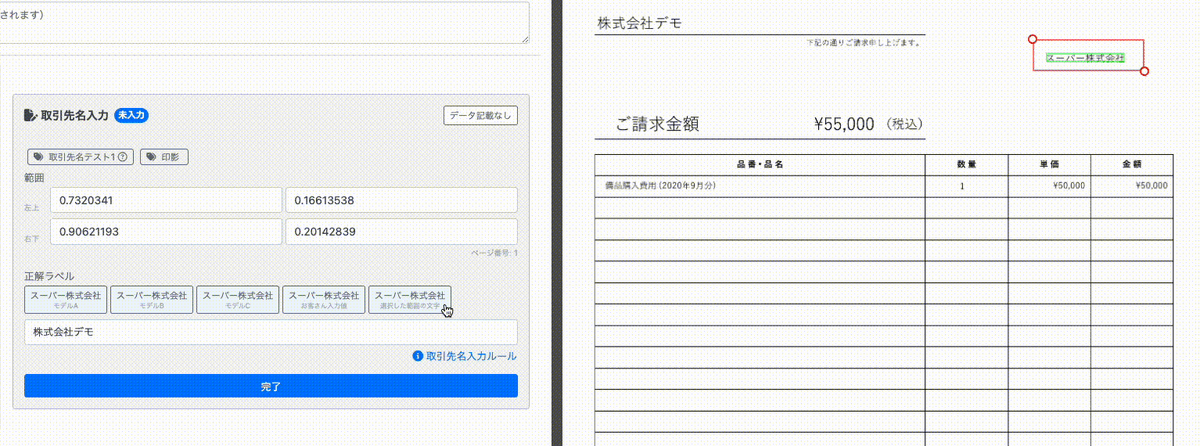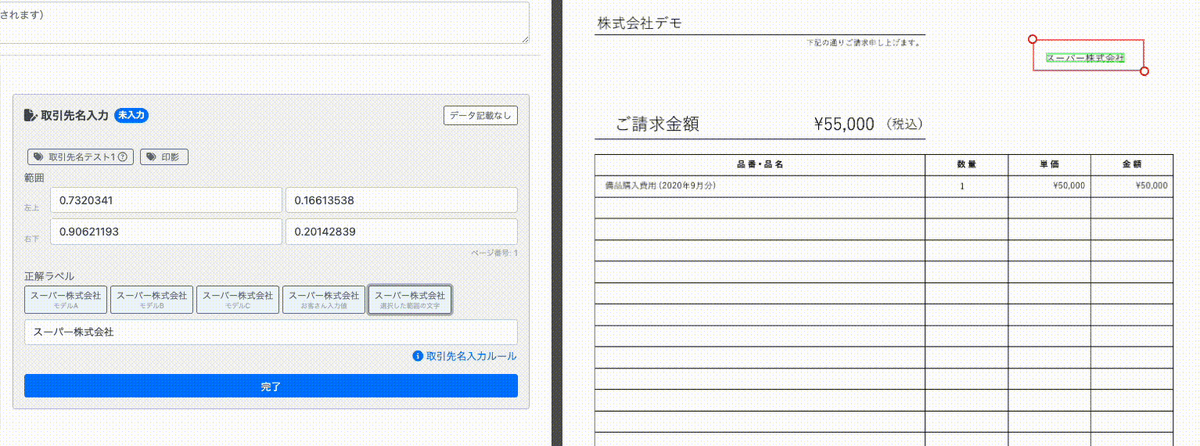
動画の左側の正解ラベルの入力画面をご覧ください。右側の請求書の「デモ株式会社」と記載されている箇所を赤枠で囲むと「デモ株式会社」とサジェストがされ、 それをクリックするとそれがそのまま入力に利用できます。
その後、「スーパー株式会社」と記載されている箇所を赤枠で囲むと「スーパー株式会社」と入力のサジェストが出ます。
これは、あらかじめ画像に対して文字とその座標を取得しておいて、囲い込みがされるたびに囲まれた部分の文字を計算することで実現しています。
ここまでくると、手入力が必要なケースはほとんどなくなります。殴り書きの手書き文字や、印刷がかすれていて文字認識自体がうまくいってないという場合に多少修正するくらいです。
情報共有しやすくする
書類に対してメモやタグをつけることでアノテーター間で情報共有したり、後から見返したい帳票を簡単に保存することができます。 アノテーションでは判断に迷うケースも多いです。迷ったポイントをメモに書いておき、後から熟練したアノテーターやエンジニアが確認するといったことを行っています。

分析しやすくする
アノテーションの作業の効率化はもちろんですが、エンジニアがデータを分析する際にも大きく役立っており重宝しています。
従来のよくあるアノテーション基盤では、単純に項目のラベリングだけできるものはありますが、自社で開発したことでアノテーション時にお客様の入力値を表示したり、動かしている複数のモデルの結果をそれぞれ表示したりすることで、うまく読み取れなかったファイルに対する分析も容易にしています。
例えば、各モデルのOCRの実行結果、アノテーター入力値、ユーザー入力値、各種中間生成ファイルなど散らばったデータを統合してあげることで一覧性を高めています。 クラウド上においてある各生成ファイルもsigned URLを発行してあげることで簡単ににアクセスできるようになっています。
これによりエラー分析やデバッグのスピードが格段にあがりました。
さいごに
バクラクではアノテーション作業もバクラクにすることでMLに必要なデータセットを爆速で作成しています。 たくさんデータ用意してお待ちしているので、MLエンジニアの方ぜひ最高のモデルを作りにきていください!!!
色々紹介しましたが、ML Opsも課題がまだまだたくさんあります! 一緒に圧倒的に使いやすいプロダクトを届けてくれるML・ML Opsエンジニアを大募集しているので気軽にお話ししましょう!