こんにちは、希望あふれる優しいデジタル社会を、未来に残したいTomoakiです。
この記事は LayerXテックアドカレ28日目の記事です。前回は勤怠の苦労から全社員を救済したitkqさんによる勤怠をいい感じにする社内Slackアプリでした。次回は玉ねぎを愛し玉ねぎに愛されたおとこ、chocoyamaさんが担当します。
今回はバクラクのAI-OCR機能の性能モニタリングに仕組みについて紹介します。
バクラクのAI-OCR機能について
バクラクでは、請求書や領収書をはじめとする国税関係の書類にOCRを実行し、入力のサジェストを行うことで、お客様が書類の内容を手入力する手間を省略しています。
例えばこちらの領収書、日付、金額、支払先、登録番号を自動で読み取ってお客様にサジェストをしています。

性能モニタリングで達成したいこと
性能モニタリングの意義としては現状を正確に把握し改善に繋げることです。具体的には以下の観点でモニタリングしています。
お客様の体験の把握
現状の性能がどの程度かを知ることは非常に重要です。現状のAI-OCRの性能を理解することは、お客様の体験を理解する大きな手がかりとなります。
読み取りに失敗すると、数十秒から場合によっては分単位での修正による時間のロスになる可能性があります。これは、月末月初で時間との戦いとなる経理の方々や、経費精算などの苦手な事務作業に立ち向かおうとする現場の方々にとって、大きなダメージです。
ここで重要なのは、単純な読み取り精度をモニタリングするのではなく、お客様の体験をモニタリングするということです。
後述しますが、単純な読み取り精度が低くても、お客様の体験は損なわれていないケースもありますし、その逆の場合もあります。
正しい優先順位で次の開発タスクを検討する上でも体験が損なわれているお客様をいち早く検出することが重要です。
過去モデルの性能との比較
バクラクで使用されているAI-OCRの機械学習モデルは定期的に再学習されていますが、新しいモデルのリリースには常にリスクが伴います。
バクラクのAI-OCRは全てのお客様に同じモデルを利用いただいているため、全体の性能は良くても、一部のお客様だけ前のモデルから性能が落ちてしまうという事象は一定発生してしまいます。
リリース前の評価時にお客様ごとに大きく体験が損なわれないかの確認はしていますが、どうしても予想できない部分もあるので、常に過去のモデルと比較してモニタリングしておくことは開発で次のアクションを考える上で重要です。
時系列的な精度の推移
データの傾向は常に変化するためリリース直後は精度が良くても、データの変化に対応できず精度が一部のお客様に限って悪化する可能性があります。
また、法改正によって書類に記載すべき情報が増えた時や、年号が変わったときなども書類の内容に変化が発生しAI-OCRの性能に予期せぬ影響を与えることがあります。
このような変化を検知するために、精度の時系列的な推移を確認しておくことは重要です。
バグの発見
OCRのロジックは極めて複雑です。機械学習モデルが日付、金額、支払先など各項目の値を推論する処理だけでなく、その前後の様々な処理が施されています。
前処理・後処理はリリース前に入念にテストをしますが、万が一バグがあった場合は早期発見して改善できるかが重要です。
例えば、精度が99%出ているようなお客様でも、残りの1%がバグのような挙動をしていたら体験としては非常に悪いです。(例えば色塗り箇所と違う場所をサジェストされているなど)
もちろん明確にエラーログが吐かれるようなバグの場合は、エラーログを監視していれば容易に検知できますが、例えば文字列をパースする処理に不備がありエラーにはならないが、読み取り結果には影響が出るようなバグはモニタリングを通じて検知するしかありません。
性能モニタリングに求められる要件
バクラクは2023年12月現在、導入社数が8000社を超えており、そのほとんどのお客様がOCRを利用してくださっています。
導入者数もさることながら、毎月アップロードされる書類の枚数も爆発的に増加しており、お客様によっては万単位の書類を毎月アップロードされるケースも少なくありません。
このような状況では、OCRの性能をモニタリングするのは大変です。当然ながら、すべての帳票を目視でチェックすることは不可能です。
リアルタイムで測定可能な定量的指標
リアルタイムでモニタリングできることは非常に重要です。何か問題が発生しても、それに気づくのが1週間後だった場合、モニタリングでそれに気づくよりも先に、お客様からの問い合わせが殺到することになるでしょう。
また、すべての帳票を目視でチェックするわけにはいかないので、指標はリアルタイム性と定量性を兼ね備えていることが望ましいです。
バクラクの性能モニタリングでは、「お客様が入力した値」と「OCRがサジェストした値」を比較した正解率を重要な指標としています。
全体の精度だけでなく、お客様ごとの精度
では、この正解率さえ毎日見ていれば良いのでしょうか?
バクラクは8000社以上のお客様が利用しており、お客様によっては万単位の書類を毎月アップロードされるため、全てのお客様横断の正解率も重要ですが、お客様一人一人の体験を評価するにはこれでは不十分です。
たとえば、月に10万枚の書類をアップロードするお客様の精度が99.9%で、月に100枚をアップロードするスタートアップのお客様の正解率が30%だとすると、全体の正解率は99.9%になり問題がないように見えますが、小規模なお客様の体験の悪さは検知できません。
したがって、全体の精度だけでなく、お客様ごとの精度を追跡することが重要です。
帳票のプレビューができること
「お客様が入力した値」と「OCRがサジェストした値」の正解率という指標は信頼できるものでしょうか?
OCRによるサジェストの値と入力値が異なると、何らかの修正が発生していることを示します。しかし、それだけではお客様の体験をモニタリングするのには十分ではありません。
お客様はなんらかしらの事情で書類に書いてない値を意図的に入力する可能性があります。 例えば、業務委託の方からの請求書の請求額から源泉徴収税を引いたり、書類日付が明記されていないファイルに対して 後に検索できるようにするために何かしらの日付を入力している場合などそのパターンは色々です。
この場合、正解率は定量的には下がって見えますが、お客様の体験は損なわれているわけではありません。
定量的な精度(=正解率など)はお客様の体験を理解するための参考値として有用ですが、あくまでやりたいのは「お客様の体験」のモニタリングです。
したがって、「お客様の体験」を理解しAI-OCRの性能を把握するためには、実際の書類を確認し、分析する必要があります。そのためモニタリングの対象は帳票の画像データも含むことが重要です。
帳票単位でのデバッグに必要な情報があること
読み取れない帳票がある場合、その原因を早急に調査できることが重要です。
例えば、読み取れない帳票がある場合、文字認識がうまくいっていないのか、項目推定の推論がうまくいっていないのか、あるいは前処理や後処理に原因があるのか、原因次第で必要なアクションが変わることがあります。
毎日のモニタリングでそこまでの分析をやる...?と思う方もいるかもしれないですが、起きている事象を把握して素早く改善に繋げていくためには必要なことだと思っいます。
以上のことをまとめるとバクラクのAI-OCRの性能モニタリングの要件は以下になります
- リアルタイムで性能をモニタリングできる指標があること
- お客様全体とお客様ごと、両方の精度モニタリングできること
- 定量的な指標に加えて、具体的な書類の情報も一緒に確認できること
- ファイルのプレビューだけなく、迅速にデバッグするための情報が整っていること
性能モニタリングの具体的な方法
モニタリングは以下の方法で実施しています。
モニタリング対象のデータ
- 前日分のデータと前週分のデータ
- 対象は全てのお客様(8000+)であり、対象はOCRを利用する全てのサービス(バクラク請求書・申請・経費精算・電子帳簿保存)
モニタリングで実施していること
- 毎日朝会にて15分ほど、機械学習チーム全員参加でモニタリングの時間を設ける
- 正解率をお客様ごとに集計し、正解率が特定の閾値を下回るお客様を抽出(Looker Studio)
- 抽出したお客様の読み取りに失敗している帳票を確認し、不正解だった原因の分析
- 改善タスクの起票
- モデルの改善
- 前処理・後処理の改善
- お客様へサービスの設定の案内
- モデルの切り替え検討
- etc…
工夫した点
内製しているアノテーション基盤の活用
Looker Studioで構築したダッシュボードを活用しつつ、読み取りが失敗したファイルに関しては、内製しているアノテーション基盤へのリンクをダッシュボード内に表示することで瞬時にファイルの分析を可能にしました。
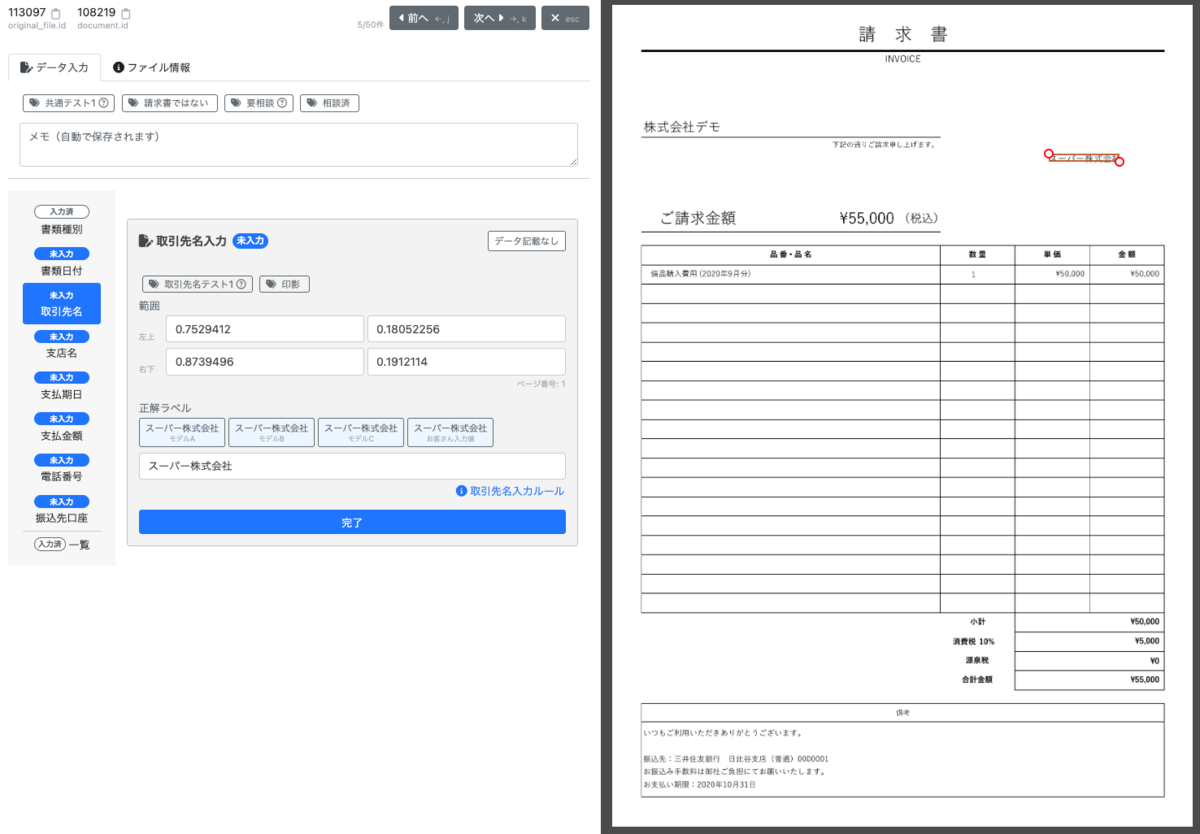
このアノテーション基盤では、ワンクリックでファイルをプレビューでき、OCRの前処理や後処理で作成された中間生成ファイルのプレビューも可能です。
以前は都度ファイルのURLを取得してAWSにアクセスする必要があり非常に手間になっていましたが、大幅な作業時間削減につながりました。
アノテーション作業に特化する場合、アノテーションツールを自作する必要はないかもしれません。しかし、このような分析作業でも利用できることを考えると、自前でアノテーションツールを作成する意義は大いにあると思います。
dbtの活用
全プロダクトに散らばったデータを一つのダッシュボードに集約するとクエリは相当複雑になります。 また、集約したい期間などクエリは随時アップデートされる可能性があったり、ダッシュボードないで同じクエリを使い回したいケースも多いです。
このように可読性・保守性の高いモニタリングダッシュボードのためにdbtを活用してクエリを細分化しています。
例えば、複数のサービスでAI-OCRを実行しているため、お客様の入力値は各サービスのデータベースに散らばっています。しかし、サービス単位で正解率を集計した上で、ダッシュボードでは全てのサービス横断で問題のありそうなお客様を抽出するために、dbtを活用して階層的にデータを作成しています。
モニタリングのナレッジの蓄積
数ヶ月この運用で続けた結果、閾値を下回るお客様でも、実際に帳票を確認してみると体験はそこまで損なわれていないケースがかなり多いことがわかりました。
例えば、書類に特定の項目の値が書いてないケースなどがあります。このようなケースでは、OCRとしては情報が記載されていないので特段何も読み取れないことが望ましいですが、お客様は何らかの値を入力しているので、定量的な精度は低く出てしまいすが、実際は体験はさほど損なわれてないはずです。
そして、お客様の帳票の傾向はすぐにコロコロ変わるものではないので、頻繁に同じお客様が閾値を下回り分析対象に入ってくるということが発生しました。
記憶力のよい人が、前回このお客様はこういう傾向があったと覚えていてくれれば良いのですが、人間は忘れる生き物なので、一度分析したお客様のファイルを再度分析するという事態が頻繁に起こってしまいます。
また、新メンバーが入ってきた時に過去のモニタリングで得られた知見が人間の記憶頼りだとうまくナレッジの共有ができません。

この課題を解決するためにアノテーション基盤にお客様ごとのモニタリングのログを蓄積できるようにしました。
同じお客様がモニタリングの対象になったとしても、お客様単位でログを蓄積しているので、「あ、このお客様は前回はこの理由で閾値を下回ったのだ」と知ることができ、モニタリングの効率が向上しました。
担当者による事前分析
朝会におけるモニタリングは目標は15分、長くても30分で終わらせたいところでしたが、30分を超えてしまう日が結構ありました。また、開発時間の確保や朝の長い会議による疲労が無視できない負担となっていました。
モニタリングは週に一回や月に一回にしてしまえば解決できると言えばできるのですが、お客様の体験にこだわる・爆速でアップデートするを体現する上で毎日deep diveしたモニタリングは重要な要素なので諦めたくはありません。
そのため、週替わりで担当者を決め、事前に閾値を下回る要注意のお客様のリストアップと読み取りエラーの分析を終え、朝の会議は共有とアクションのディスカッションの場にすることで、クオリティを維持したまま、会議時間の削減を図りました。
モニタリングの成果
毎日何かしらの改善点を発見
粒度は大小様々ですが、毎日の深掘りしたモニタリングにより、多くの発見があります。 バックログのタスクのほとんどはモニタリングの時間で作られていると言っても過言でもありません。
軽微な前処理・後処理のバグなどはすぐに修正してリリースして改善のサイクルを回しています。
課題に関して毎日同期的に話すことで、課題に対する理解と解像度が深まる
読み取れてない帳票があるときに、要因が明確であることは多くありません。 必然的に「なぜ読み取れてないのか」、「改善するにはどういうアプローチがあるか」といったディスカッションが自然と行われます。
これは、課題に対する理解と解像度を深めるという点で非常に有益であり、新メンバーがキャッチアップする上でも大きな意義があると思います。
エンジニアのドメイン知識の獲得
世の中には多様な書体、書式、言語、レイアウトの書類が存在し、100社あればそれぞれ独自の書類があります。私も3年近く様々な帳票を見てきましたが、毎日新たな発見があります。
多くの帳票を見ることは、エンジニアがドメインの理解を深める大きな助けとなります。エンジニアのドメイン知識の獲得は、最終的に改善のサイクルを早めることにつながり、非常に重要だと思います。
今後の課題
アノテーション対象の作成までの自動化
モニタリングで性能の低下を検知した場合、すぐにアノテーションを行い、改善につなげる仕組みはまだまだ整っていません。
バクラクには専門のアノテーションチームがありますが、アノテーションの対象は人間の判断でピックアップしています。
ピックアップの作業は大きな負担ですし、何より選定の判断基準が最終的には属人的になってしまうため自動化をしていきたいと考えています。
また、どのようなデータを優先的にアノテーションすれば性能向上に効率的に寄与できるかの分析もまだまだできていない部分が大きく課題に感じています。
さらなるデータ増加に備えたモニタリングの仕組み
データが爆発的に増加しているため、現状のモニタリングが1年後も同じ運用で回るとは思っていません。
今は毎日15分程度でモニタリングは完結していますが、データが10倍、100倍になっていったときどのようにしてモニタリングしていいかは悩ましいです。
最後に
今回はバクラクのAI-OCRの性能モニタリングについて紹介しました!
モニタリングはお客様の体験にこだわる・爆速でアップデートするを体現する上で非常に重要ですが、課題もいろいろあります。
LayerXではバクラクな体験を届けワクワクする働き方を提供したいエンジニアを大募集しています!
気になった方はぜひカジュアル面談しましょう!