機械学習エンジニアの吉田です。前回は NVIDIA Triton Inference Server の性能を検証した話を書きましたが今回はその続編となります。
前回の記事以降も継続してTriton Inference Serverの検証を重ねた結果、推論サーバの性能を大幅に改善することができ、無事本番に導入することができました。 この記事では本番導入までにどのような改善や検証を行ったのか書きたいと思います。
はじめに
背景
バクラクでは請求書OCRなどの機械学習モデルを開発しており、リアルタイムで推論結果を返す必要があります。 推論APIはNginx、Gunicorn w/ Uvicorn、FastAPIで実装され、PyTorchモデルをGPUで推論、SageMaker Endpointでサービングしており、 リリース以降問題なく稼働してきましたが、お客様の増加やユースケースの多様化に伴いよりスケーラブルなシステムや効率的な運用が求められるようになりました。
課題
具体的な課題としては以下のようなものがありました。
1. 推論処理に時間がかかりタイムアウトする
- 文字数の多い帳票が一括でアップロードされた場合に発生
- GPUでの推論処理がボトルネック
2. スケールアウトが困難
- CPUバウンドな前処理/後処理とGPUバウンドな推論処理をひとつのサーバで処理しており、ボトルネックに応じてスケールアウトすることができない
- 推論にはGPUが必要なため、前処理/後処理のスループットを上げるためだけにGPUインスタンスを増やすのはコストに見合わない
- ナイーブにFastAPIでPyTorchモデルを読み込んでいたため、スループットを上げようとUvicorn workerの数を増やすとVRAMが枯渇する
3. モデル毎にリソースが分散し非効率
- 複数のモデルをサービングするためにそれぞれ異なるSageMaker Endpointにデプロイしていたが、常に一定のリクエストが来るわけではないためリソースが無駄にアイドル状態になることがある
- 特定のエンドポイントにリクエストが集中した場合、そのエンドポイントだけが負荷を受けるため、スパイクの対応に柔軟性が欠ける
改善点
上記の課題を解決するために、主に以下の3つの改善を行いました。
- TensorRT FP16 による推論レイテンシの改善
- マルチモデルエンドポイントの活用
- 前処理/後処理と推論処理の分離
TensorRT FP16 による推論レイテンシの改善
TensorRTでは推論時の演算をFP16やINT8の低精度にすることができ、通常のFP32での推論と比較して推論速度やメモリ効率の大幅な向上が期待できます。
デメリットとしてはモデルの推論結果が変わり、タスクによっては精度が悪化する可能性があります。
TensorRTをFP16で変換したモデルの性能を以下の条件で検証しました。
実験
モデル
- ベースとなるPyTorchモデルは最大系列長512のRoBERTa largeを用いた分類モデル
- PyTorchモデルからONNXモデルに変換
- 入力するinput_idsとattention_maskは可変長とする
- opset_versionは18を指定
- ONNXモデルからtrtexecを使ってTensorRTモデルに変換
- FP32とFP16の2つの精度で変換
- 入力するinput_idsとattention_maskは以下の通り 1 x 1 ~ 7 x 512 で可変長とする
trtexec --onnx={onnx_model_path} --saveEngine={tensorrt_model_path} \
--minShapes=input_ids:1x1,attention_mask:1x1 \
--optShapes=input_ids:2x512,attention_mask:2x512 \
--maxShapes=input_ids:7x512,attention_mask:7x512
実験環境
- input_ids, attention_maskをREST APIで受け取り、推論結果を返すだけのAPIサーバをSageMaker Endpointで構築
- SageMaker Endpointのインスタンスタイプは ml.g4dn.xlarge (NVIDIA T4, 4vCPU, 16GB) を使用
- ベースラインはNginx, Gunicorn w/ Uvicorn, FastAPIでAPIサーバを構築し、PyTorchモデルで推論
- TensorRTはTriton Inference Serverで推論
実験方法
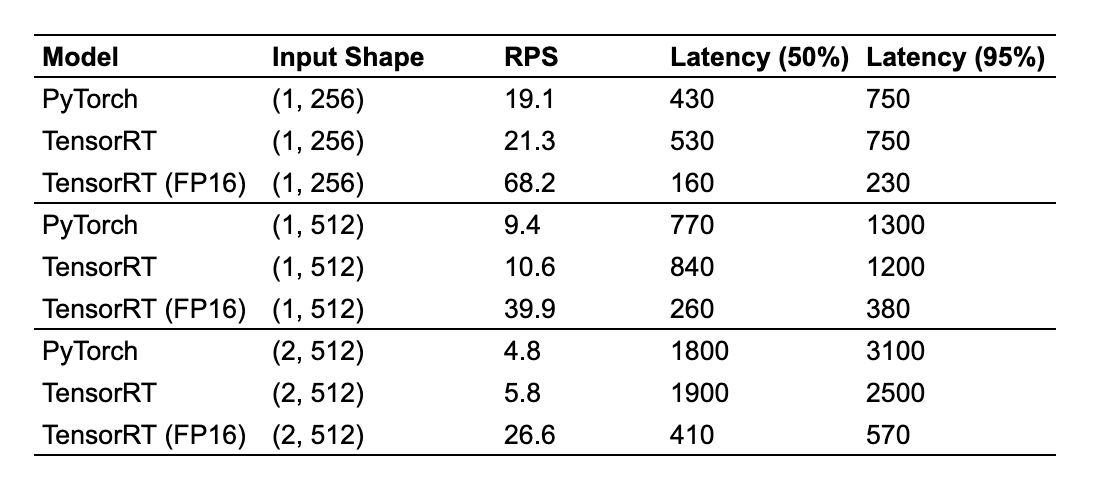
- モデルに入力する系列長によってレイテンシが大きく変わるため、(1, 256), (1, 512), (2, 512) の3通りの入力サイズで実験
- 性能指標はスループット (Requests Per Second, RPS) とし、Locustを使用して手元のPCから負荷をかけ、RPSが頭打ちにになったときのRPSとレイテンシ(ms)を記録
- 精度評価に関しては、約10万件のテストデータセットに対して、PyTorchモデルとTensorRT(FP16)で比較
実験結果
- TensorRT(FP16)は、95パーセンタイルレイテンシを見ると3 ~ 5倍高速化し、結果スループット(RPS)も他のモデルの3倍以上と大きく改善した
- 入力サイズが大きくなるほどその差は顕著で (2, 512) ではPyTorchモデルと比較して5.54倍、TensorRTと比較しても4.58倍のRPSとなった
- 精度に関しては、約10万件のテストデータセットに対して ±0.05pt と大きな劣化はみられなかった

マルチモデルエンドポイントの活用
SageMakerには単一のエンドポイントで複数の機械学習モデルをサービングすることができるマルチモデルエンドポイントという機能があり、エンドポイントを呼び出す際にターゲットモデルのパスをパラメータで指定することで、推論するモデルを切り替えることができます。
 画像引用元
画像引用元
マルチモデルエンドポイントを活用し、複数モデルのエンドポイントを集約することでリソースの無駄なアイドルを減らすことができます。
また、モデル毎にサーバを用意するのではなく、共通化したサーバを複数台並べることで特定モデルに対する突発的なスパイクリクエストへも対応しやすくなります。
懸念点としては、リソースが不足した場合にモデルが動的にアンロードされる点でした。
この場合、次回リクエスト時にモデルのロードが走ることで高レイテンシとなってしまうので負荷試験でリソースに余裕があることを確認しました。
前処理/後処理と推論処理の分離
CPUバウンドな前処理/後処理とGPUバウンドな推論処理を分離するために、以下のように推論処理だけをTriton Inference Serverに切り出し、前処理/後処理はいままで通りFastAPIで処理するようにアーキテクチャを変更しました。

Triton Inference Serverはマルチモデルエンドポイントを活用することで、複数モデルでエンドポイントを共通化します。
前処理/後処理を行うFastAPIサーバはGPUが不要となるのでCPUインスタンスを使うことでコストを下げることができます。
モデルをロードする必要もなくなり、低コストでCPUコア数を増やすことができるのでUvicorn workerを増やし、スループットを上げることが可能になります。
FastAPIサーバは、推論対象のモデルを指定するパラメータの追加だけなので、リリース時はクライアントの実装は大きく変更することなく切り替えができます。
スケーラビリティ検証
最後に推論処理だけではなく、前処理/後処理も含めた全パイプラインでの新旧アーキテクチャでの性能と、サーバの台数を増やした場合にどの程度スケールするのか検証を行いました。
実験方法
- モデルに入力する系列長は (1, 203) と (7, 512) の2通り
- 性能指標はスループット (Requests Per Second, RPS) とし、Locustを使用して手元のPCから負荷をかけ、RPSが頭打ちにになったときのRPSとレイテンシ(ms)を記録
- 新アーキテクチャではFastAPIとTriton Inference Serverの台数を変えた場合の性能の比較も行う
- 参考までにその構成の場合のコスト($/hour) も併記
- ml.g4dn.xlarge は $0.994/hour, ml.c6i.2xlarge は $0.5136/hour で計算 (2024/6/19 現在)
実験結果
- 推論処理をTriton Inference Serverに分離することでRPSが約4~5倍、レイテンシは約半分に改善 (No.1, 2)
- 入力サイズが小さい場合 (1, 203) は、CPUがボトルネックとなり、FastAPIサーバを1台増やすことで25RPS増加する (No.2, 3, 6)
- 入力サイズが大きい場合 (7, 512) は、FastAPIサーバが2台以上でGPUがボトルネックとなりTriton Inference Serverの増強が必要となる (No.3, 5, 6)

本番リリース
最終的に本番環境ではFastAPIサーバ、Triton Inference Serverそれぞれ2台の構成で、2つのモデルをマルチモデルエンドポイントでデプロイしました。
Triton Inference Serverは、本番リリース後の状況をみてチューニングすることを考えていたので前回の記事で検証していた動的バッチ処理は使いませんでした。
以下は推論APIの99パーセンタイルのレイテンシ(API呼び出し元のクライアントからみたレイテンシ, sec)になります (色の違いはモデルの違い)
本番リリース以降、99パーセンタイルレイテンシの平均値で約55%、最大値で約80%減少させることができました。

また、マルチモデルエンドポイントで懸念していたモデルのアンロードも発生せず、稀に発生していたタイムアウトもリリース以降無くなりました。 リソースもかなり余裕があるのでしばらくはパフォーマンスについては悩まなくてよさそうで最高です!
課題
TensorRTを使うことで、今回のケースでは精度への影響は小さかったものの、推論結果が変わってしまうことや動かせるハードウェアが制限されてしまいます。 本番とまったく同じ結果を得ようと思うと、開発環境でも本番と同じ環境を用意する必要があり、コストの増加や評価が難しくなるといった課題が残ります。
機械学習チームでは、このような課題を解決するための、ロバストで効率的な機械学習パイプラインを一緒に構築していくMLOpsエンジニアを募集しています! 興味を持たれた方は是非カジュアル面談からでもお気軽にどうぞ!