AI・LLM事業部でLLMエンジニアとしてインターンしています竹本健悟 (@Xq7V4) です。
2025/07/21にGoogleからGemini 2.5による会話型画像セグメンテーション機能が発表されました。
Gemini 2.5 introduces conversational image segmentation for AI, enabling advanced visual understanding through object relationships, conditional logic, and in-image text. https://t.co/urfBEAwV7U
— Google AI Developers (@googleaidevs) 2025年7月21日
本記事ではこの画像セグメンテーション機能について、
- どのようなことが可能で
- どのような仕組みになっていて、
- ドキュメント処理においてどのように活用できるか
をまとめていきます。
公式実装ノートブック:Spital_understanding.ipynb
目次
1. 何ができる?
Gemini 2.5の会話型画像セグメンテーションでは、Geminiの持つ現実世界に対する知識、推論能力を活かしながら自然言語をクエリにして物体検出・マスキングを行うことができます。
Googleの出している紹介記事を元に、いくつか実例を紹介します。
オブジェクトの関係性・条件を指定した物体検出
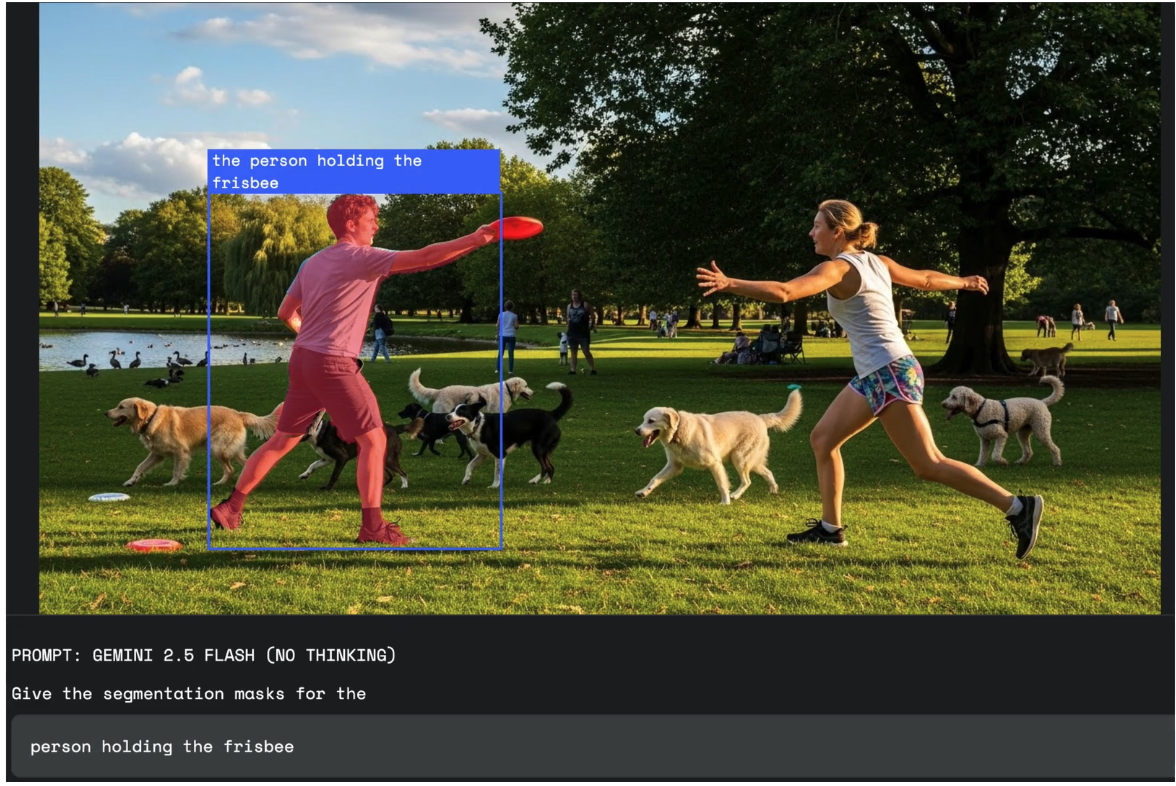
Gemini 2.5の会話型画像セグメンテーションは、Geminiの持つマルチモーダルな意味解釈性能によって、他オブジェクトの関係性や複雑な条件を指定した上での物体検出が可能です。
以下の例では、「フリスビーを持った人」という「フリスビー」と「人」という2つのオブジェクトの関係性をきちんと捉える必要のあるクエリに対して、適切に物体検出が出来ています。
他にも以下のようなクエリに対して適切に意味解釈を行なった上で物体検出を行うことが可能です。
- 関係理解:the person holding the umbrella
- 数え上げ:the third book from the left
- 比較:the most wilted flower in the bouquet
- 条件付け:people who are not sitting
抽象的な概念に基づいた物体検出
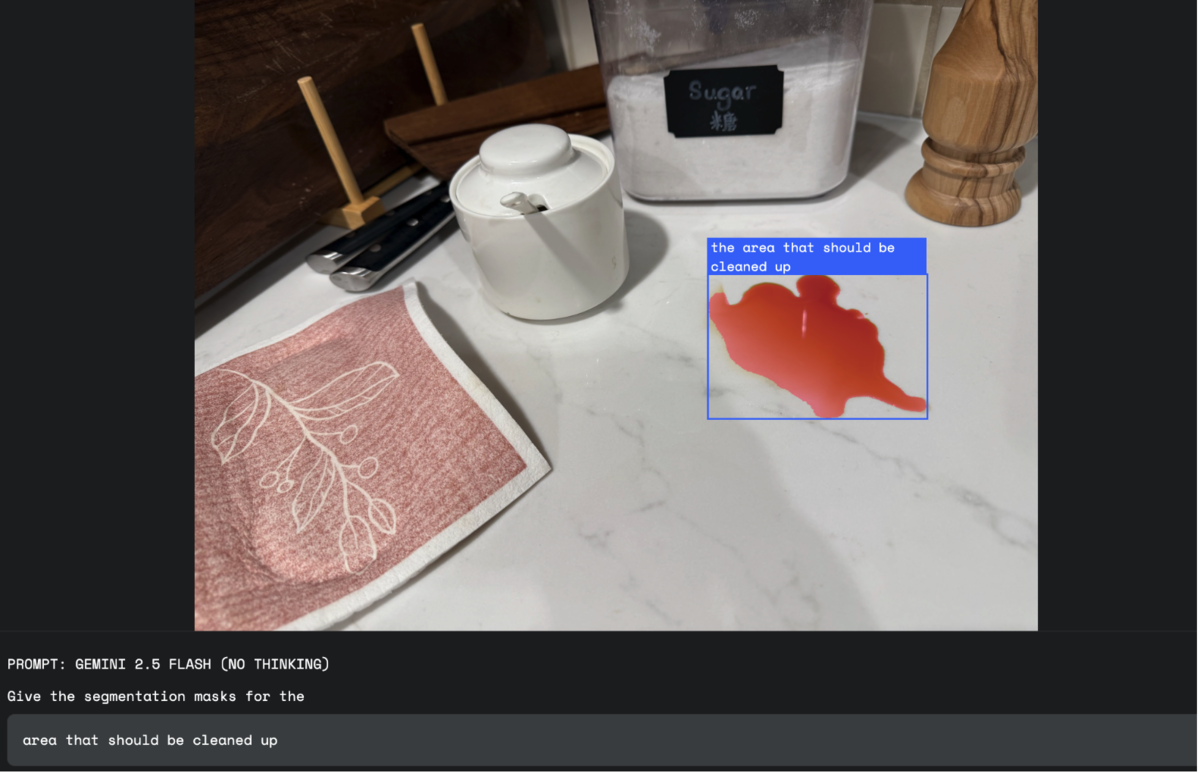
Geminiの持つ思考能力を活かすことで、固定された視覚的定義を持たない概念的なものもクエリにすることができます。これにより、直接検出したいオブジェクトを一意に定めることができないような場合でも、適切にユーザーの要望を理解し、物体検出を行うことが期待できます。
以下の例では、「綺麗にするべき箇所」という曖昧で概念的なクエリに対して、液体がこぼれて汚れている部分を適切に検出しています。
OCR機能を活用した物体検出
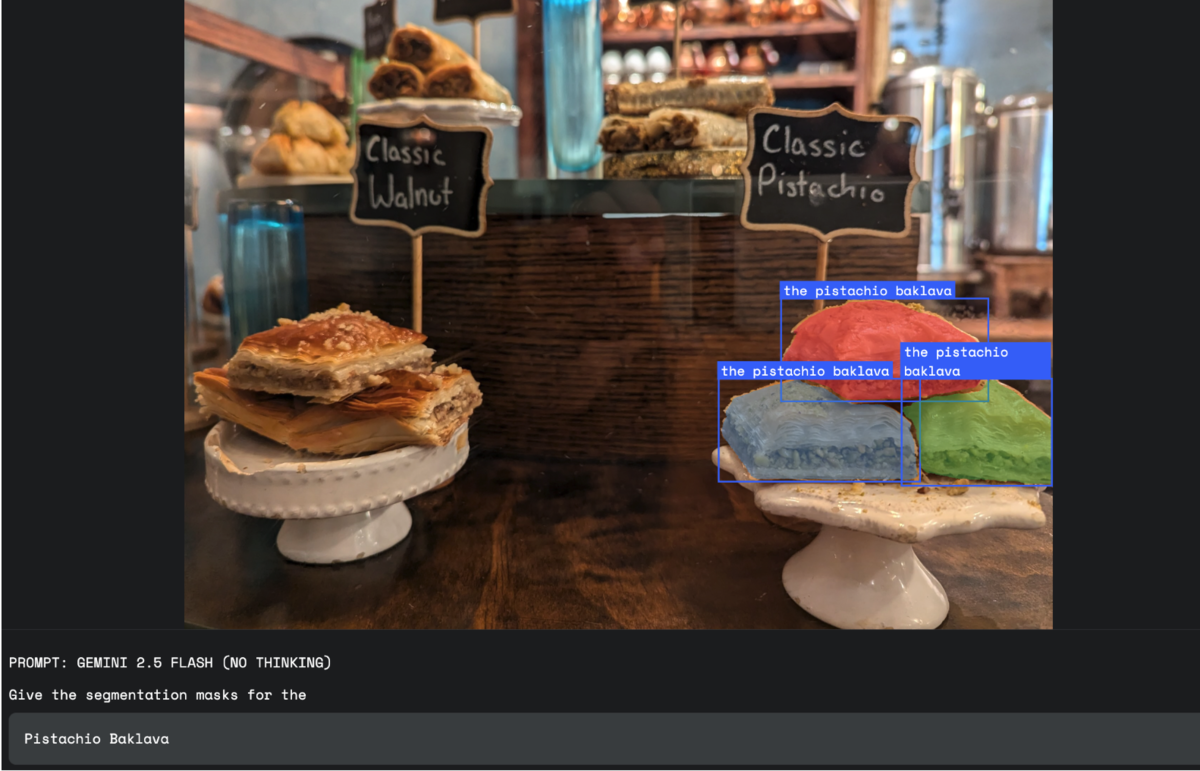
Geminiは高いOCR(光学文字認識)性能を持つことで知られています。Gemini2.5の会話型画像セグメンテーション機能では、このOCR性能を生かして画像内の文章を理解した上で、物体を検出することが可能です。
以下の例では、「Pistachio Baklava」というクエリに対して看板に書いてある「Classic Pistachio」という文字を読み取ることで、適切にお菓子の存在する領域を検出できています。
また、Geminiの言語モデルとしての多言語性能を活かすことで、クエリとラベルの言語をそれぞれ自由に指定することができます。例えば、「クエリは英語で記述するが、ラベルはフランス語でつけてほしい」というような場合でも、プロンプトで指示するだけで柔軟に対応することができます。
2. どういう仕組み?
次に、どのようにしてこの会話型画像セグメンテーション機能が実現されているのかを解説していきます。詳細な実装については公式実装ノートブックをご覧ください。
バウンディングボックスの出力
まず、物体が画像内のどこにあるのかを長方形で示すバンディングボックスの出力について解説します。
Gemini2.5のチャットAPIにおいて、以下のようにJSON形式でオブジェクトのラベルとバウンディングボックスを出力するようにシステムプロンプトを指定します。
Return bounding boxes as a JSON array with labels. Never return masks or code fencing. Limit to 25 objects. If an object is present multiple times, name them according to their unique characteristic (colors, size, position, unique characteristics, etc..).
Google AI Studio上でのデモでは、以上とは少し違うシステムプロンプトを用いていますが、おおむね1.バウンディングボックスとラベルを出力する事、2.JSON形式で出力する事の2点が内容として含まれていれば正常に動作すると考えられます。
次に、ユーザープロンプトで何の物体を検出するのかを指定します。
Show me the positions of the socks with the face
以上のメッセージでリクエストを送ると、以下のような出力が返ってきます。
[ {"box_2d": [53, 248, 386, 526], "label": "the socks with the face"}, {"box_2d": [237, 661, 650, 861], "label": "the socks with the face"} ]
このbox_2dが長方形の左上・右下の座標をそれぞれを表しているので、Pillow(PIL)のような画像処理ライブラリを用いて、元画像と出力されたbox_2dを元にした矩形を重ねて表示すれば、物体検出を行うことができます。

セグメンテーションマスクの出力
次に検出した物体のマスキングを行うためのセグメンテーションマスクの出力について解説します。
Gemini2.5のチャットAPIにおいて以下のようなプロンプトで、JSON形式でオブジェクトのラベルとバウンディングボックス、バウンディングボックス内でのマスクの画像をbase64形式でエンコードしたものをまとめて出力するよう指示します。
Give the segmentation masks for the metal, wooden and glass small items (ignore the table). Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key \"box_2d\", the segmentation mask in key \"mask\", and the text label in the key \"label\". Use descriptive labels.
このプロンプトでリクエストを送ると、以下のような出力が返ってきます。 (base64エンコードされたマスクについては長すぎるので省略しています。)
[ {"box_2d": [316, 479, 417, 606], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSU...", "label": "glass small items"}, {"box_2d": [260, 703, 431, 810], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSU...", "label": "glass small items"}, {"box_2d": [200, 252, 340, 381], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSU...", "label": "metal"}, {"box_2d": [50, 320, 210, 398], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSU...", "label": "wooden"}, {"box_2d": [0, 370, 166, 458], "mask": "data:image/png;base64,iVBORw0KGgoAAAANSU...", "label": "wooden"}, ]
この出力において、base64形式でエンコードされたマスク画像をデコードすると以下の様に、バウンディングボックス内で物体の存在する部分を白色で、それ以外を黒色で表示した画像になります。
このマスク画像を、バウンディングボックスの座標情報を基準として元画像と色をつけて重ね合わせることで検出した物体のマスキングを行うことが出来ます。


この処理を検出された物体1つ1つに対して行うことで検出した物体のセグメンテーションマスクを実現することができます。
3. 他モデルで同じことができる?
上記の仕組みは単にプロンプトでの指示と出力形式を指定してチャットAPIを実行しているだけなので、Gemini2.5以外の任意の画像入力に対応しているLLMでも同様のことが実現できる可能性があります。
そこで、今回はOpenAIのGPT系のモデルのAPIで同様の会話型画像セグメンテーションが実現可能なのかを検証していきます。
具体的には、Gemini 2.5 Flash、GPT-4o、GPT-4.1、o3に対して同様の画像、クエリで画像セグメンテーションを実行し、その精度を比較しました。
- 入力プロンプト:「Show me the position of the socks with the face」
結果は以下の通りです。




これを見ると、GPT-4o、GPT-4.1、o3の順に出力結果が良くなっていますが、Gemini 2.5 Flashのセグメンテーション精度が最も精度良くセグメンテーションできていることがわかります。
この結果は、Gemini 2.5の高い画像理解能力が高精度な画像セグメンテーションを可能にしていることを示唆しています。Gemini 2.5のテクニカルレポートの情報では、マルチモーダルな推論能力を評価するMMMUベンチマークのスコアは以下のようになっており、Gemini 2.5が他モデルと比べて高い画像理解能力を持っていることがわかります。
| モデル | MMMUスコア |
|---|---|
| GPT-4o | 69.1% |
| GPT-4.1 | 75% |
| o3 high | 82.9% |
| o4-mini high | 81.6% |
| Claude 4 Sonnet | 74.4% |
| Claude 4 Opus | 76.5% |
| Gemini 1.5 Flash | 58.3% |
| Gemini 1.5 Pro | 67.7% |
| Gemini 2.0 Flash | 69.3% |
| Gemini 2.5 Flash | 79.7% |
| Gemini 2.5 Pro | 82.0% |
マスキング画像の出力については、GPT系のモデルではbase64でエンコードさせた画像を出力することはできませんでした。通常チャットAPIにおけるこのようなbase64形式での画像出力はセキュリティの観点から禁止されている場合が多いので、圧倒的な精度の高さも含めて考えるとGemini 2.5では画像セグメンテーション用途に特別なInstruction Tuningを施しているのではないかと考えられます。
4. スライドからの情報抽出での使用例
これまで、Gemini 2.5の会話型画像セグメンテーション機能で何ができるのか・どういう仕組みなのかをまとめてきました。 公式の出している実行例では、写真のような非構造的な実写画像を対象としているケースが多いです。
しかし、我々の開発しているAi Workforceのようなドキュメントワークに特化したプロダクトでは、処理対象となるのはスライドのような構造的な複雑性を持ったドキュメントである場合がほとんどです。このようなドキュメント処理にGemini 2.5の会話型画像セグメンテーション機能を活用するにはどうしたら良いでしょうか?
今回は不動産の物件情報を掲載したスライドからの情報抽出を例として、Gemini2.5の会話型画像セグメンテーション機能のドキュメント処理への活用方法を紹介していきます。
問題設定
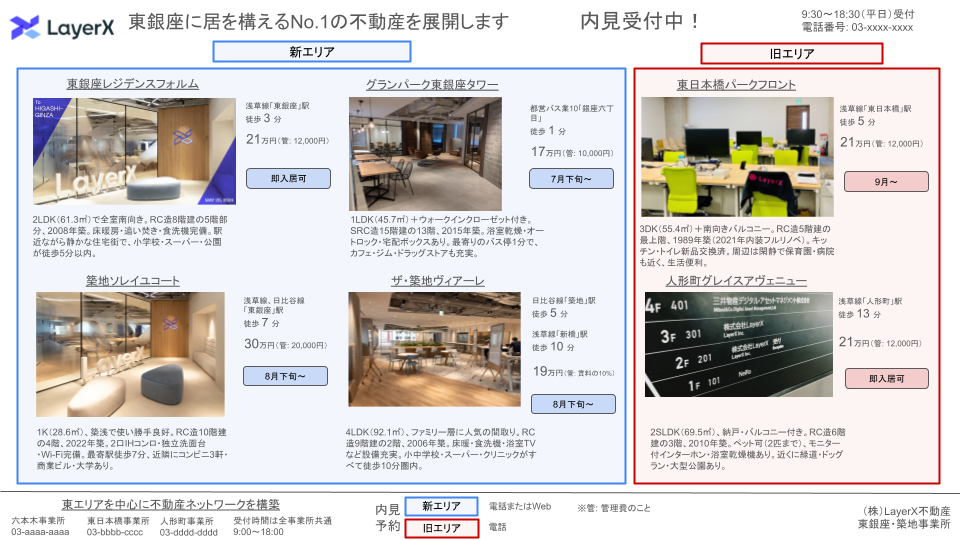
不動産の物件情報を掲載したサンプルスライドから以下の情報を抽出するタスクを考えます。
- 物件情報(6物件)
- 物件名
- 電車路線・最寄り駅
- 駅徒歩
- 最寄りのバス
- バス徒歩
- 賃料
- 管理費
- 入居可能日
- 間取り
- 平米
- 築年数
- 物件の特徴
- 会社
- 会社名
- 事業所情報(4事業所)
- 事業所名
- 電話番号
- 営業時間
- エリア(新 / 旧)
- エリア名
- 内見予約
このタスクの難しい点としては以下が挙げられます。
- 6つの物件それぞれの詳細情報を取り違えなく抽出する必要がある
- 新エリアと旧エリアの分類
- それぞれの物件の詳細情報が何を表しているのかが明記されていない
- 路線が1つの物件に対して複数存在する
- 管理費は具体的な数値として示されている場合と「賃料の〜%」と示されている場合がある
- 事業者情報がスライド内の離れた箇所に分散して存在している
従来のドキュメント処理の問題点
ドキュメントからの情報抽出の手段として、まずはAzure AI Document Intelligenceのようなテキスト抽出ライブラリを使用することが考えられます。しかし、単純なテキスト抽出では、「ある"21万円"というテキストが何を意味していて、どの物件に関する情報なのか」というようなドキュメントに含まれる構造性に関する情報が抜け落ちてしまいます。
Azure AI Document Intelligenceでは文章ごとの画像における座標情報が取れるので、これを用いてクラスタリングを行い、各物件についての情報ごとにひとまとめにするという選択肢もありますが、実装が煩雑な割には誤分類が怖く、ロバスト性に欠けます。
そこで考えられるのが、GeminiのようなマルチモーダルLLMを用いて情報抽出を行うという選択肢です。この場合は自然言語でクエリを指定し、意味解釈を含めた上での情報抽出を行うことが可能です。しかし、今回の例のような複雑なドキュメントから1度に全ての情報を正しく抽出するのは難易度が高く、抽出精度に懸念が残ります。
実際に今回のスライド画像をGemini 2.5 Flashに入力し、フォーマットを指定して情報の構造化を行うよう指示したところ、物件ごとの情報の取り違いや・OCRのエラーが発生してしまうことが確認できました。
Gemini 2.5 Flashに1度で処理させた結果
物件情報
| 物件名 | 電車路線・最寄り駅 | 駅徒歩 | 最寄りのバス | バス徒歩 | 賃料 | 管理費 | 入居可能日 | 間取り | 平米 | 築年数 | エリア | 物件の特徴 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 東銀座レジデンスフォルム | 浅草線「東銀座」駅 | 3 | — | — | 210,000円 | 12,000円 | 即入居可 | 2LDK | 61.3㎡ | 2006年築 | 新エリア | 全室南向き、RC造5階建の5階部分。2006年築。床暖房・追い焚き・食洗機完備。駅近ながら静かな住宅街で、小学校・スーパー・公園が徒歩5分以内。 |
| グランパーク東銀座タワー | 浅草線「東銀座」駅 | 1 | 都営バス「銀座四丁目」 | 1 | 170,000円 | 10,000円 | 7月下旬~ | 1LDK | 45.7㎡ | 築 | 新エリア | オートロック・宅配ボックスあり。最寄りのバス停1分で、カフェ・ジム・ドラッグストアも充実。 |
| 東日本橋パークフロント | 浅草線「東日本橋」駅 | 5 | — | — | 210,000円 | 12,000円 | 9月~ | 3DK | 55.4㎡ | 1989年築 | 旧エリア | 南向きバルコニー、RC造5階建の最上階。1989年築(2021年内装フルリノベ)。キッチン・トイレ新品交換済。周辺は隣接て保育園・病院も近く、生活便利。 |
| 築地ソレイユコート | 浅草線、日比谷線「東銀座」駅 | 7 | — | — | 300,000円 | 20,000円 | 8月下旬~ | 1K | 28.6㎡ | 2022年築 | 新エリア | 築浅で使い勝手良好、RC造10階建の4階。2022年築。2口IHコンロ・独立洗面台・Wi-Fi完備。最新築浅物件。近隣にコンビニ3軒・商業ビル・大学あり。 |
| ザ・築地ヴィアーレ | 日比谷線「築地」駅 | 5 | 浅草線「東銀座」駅 | 10 | 190,000円 | 10,000円 | 8月下旬~ | 4LDK | 92.1㎡ | 2006年築 | 新エリア | ファミリー層に人気の間取り。RC造9階建の2階。2006年築。床暖・食洗機・浴室TVなど設備充実。小中学校・スーパークリニックがすべて徒歩10分圏内。 |
| 人形町グレイシアヴェニュー | 浅草線「人形町」駅 | 13 | — | — | 210,000円 | 12,000円 | 即入居可 | 2SLDK | 69.5㎡ | 2010年築 | 旧エリア | 納戸・バルコニー付き、RC造6階建の3階。2010年築。ペット(2匹まで)・モニター付インターホン・温水洗浄機あり。近くに銭湯・ドッグラン・大型公園あり。 |
事業者情報
| 会社名 | 事業所名 | 電話番号 | 営業時間 |
|---|---|---|---|
| LayerX不動産 | 東銀座・築地事業所 | 03-xxxx-xxxx | 抽出されず |
| LayerX不動産 | 六本木事業所 | 03-aaaa-aaaa | 抽出されず |
| LayerX不動産 | 東日本橋事業所 | 03-bbbb-cccc | 抽出されず |
| LayerX不動産 | 人形町事業所 | 03-dddd-dddd | 抽出されず |
エリア(新 / 旧)
| エリア名 | 内見予約 |
|---|---|
| 新エリア | 内見予約 |
| 旧エリア | 電話またはWeb |
会話型画像セグメンテーションを活用した実装例
以上の問題を解決するため、今回はGemini2.5の会話型画像セグメンテーションを用いて、以下のようなステップでドキュメントを処理する実装を行いました。
Gemini 2.5 Flashを用いて大域的な情報を抽出
会話型画像セグメンテーション機能を用いて、各物件についての情報が記載してある領域の座標を検出
元画像を2.で検出した各物件情報の領域の座標を元にクリッピングを行う
3.でクリッピングして得られた各物件ごとの画像を、Gemini 2.5 Flashに画像入力して物件ごとの詳細情報を抽出
1.で取得した大域的な情報と4.で取得した各物件の詳細情報をマージして最終的な出力を得る
以下で各ステップについて詳しく説明していきます。
1. Gemini 2.5 Flashを用いて大域的な情報を抽出
まず、以下のようなプロンプトで事業所の情報や物件の新エリア/旧エリアの判断等、画像全体から判断しなければならない情報を抽出します。
あなたは、不動産業者のウェブサイトのデザインを分析するエージェントです。 この画像から以下の項目を全て見逃しなく抽出し、json形式で出力してください。 取得項目 building:list[dict] (物件) - name: str (物件名) - area: str (新/旧エリア) company: list[dict] (会社)) - name: str (会社) - office: list[dict] (事業所) - name: str (事業所名) - phone_number: str (電話番号) - opening_hours: str (受付時間) area:list[dict] (新/旧エリア) - name: str (エリア名) - contact_method: str (連絡手段)
2. 会話型画像セグメンテーション機能を用いて、各物件についての情報が記載してある領域の座標を検出
次に、Gemini 2.5 Flashで以下のようなプロンプトによって画像セグメンテーションを行います。
(プロンプト内のbuilding_numは1. の抽出結果を用いています。)
Please show the approximate {building_num} regions describingding one building's features in the image.

3. 元画像を2.で検出した各物件情報の領域の座標を元にクリッピングを行う
2.で得られた物件ごとのバウンディングボックスの座標を元に、上下左右にマージンを持たせて元画像をクリッピングします。
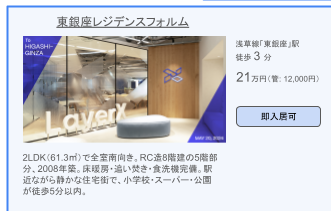
4. 3.でクリッピングして得られた各物件ごとの画像を、Gemini 2.5 Flashに画像入力して物件ごとの詳細情報を抽出
クリッピングされた画像から、以下のようなプロンプトで物件ごとの詳細情報を抽出します。 この処理を全物件の画像に対して行います。
あなたは、不動産業者のウェブサイトのデザインを分析するエージェントです。 この画像から以下の項目を抽出し、json形式で出力してください。 取得項目 - name: str (物件名) - train_line: str[]? (最寄りの駅名:1つの駅に複数の路線がある場合は、まとめて一つの駅名として出力 ex. 都営三田線、都営新宿線「神保町」駅) - train_access_time: int[]? (駅徒歩[分]) - bus_line: str[]? (最寄りのバス路線) - bus_access_time: int[]? (バス徒歩[分]) - rent: int (賃料) - management_fee: int (管理費) - available_date: str (入居可能日) - floor_plan: str (間取り) - floor_area: float (平米[m^2]) - age: str (築年月) - expression: str (物件の特徴)
5. 1.で取得した大域的な情報と4.で取得した各物件の詳細情報をマージして最終的な出力を得る
1.で出力されたJSON内のbuilding内に、4.の出力結果を埋め込むことで全項目が含まれたJSONへと成形します。
今回のスライド画像において、各物件ごとに情報が集まっている領域は分かれています。 人間がスライドを見る際も、同様に情報の領域を意識して画像を分析することで各物件ごとの情報を得ているはずです。
そこで、2. においてGemini 2.5の会話型画像セグメンテーションを使用して各物件ごとの情報の領域を検出し、その領域で切り抜いた画像を後段でのLLMを用いた情報抽出に用いています。 そうすることで、LLMが処理しなければならない情報を必要十分な量に抑え、物件ごとの情報の取り違いを防ぐことで、確実に情報抽出を行うことができます。
以上の処理フローを実行することで、全ての情報を正しく抽出できることが確認できました。
今回作成したワークフローによる情報抽出結果
物件情報
| 物件名 | 電車路線・最寄り駅 | 駅徒歩 | 最寄りのバス | バス徒歩 | 賃料 | 管理費 | 入居可能日 | 間取り | 平米 | 築年数 | エリア | 物件の特徴 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 東銀座レジデンスフォルム | 浅草線「東銀座」駅 | 3 | — | — | 210,000円 | 12,000円 | 即入居可 | 2LDK | 61.3 | 2008年築 | 新エリア | 全室南向き。RC造8階建の5階部分。床暖房・追い焚き・食洗機完備。駅近ながら静かな住宅街で、小学校・スーパー・公園が徒歩5分以内。 |
| グランパーク東銀座タワー | — | — | 都営バス業10「銀座六丁目」 | 1 | 170,000円 | 10,000円 | 7月下旬 | 1LDK | 45.7 | 2015年築 | 新エリア | ウォークインクローゼット付き。SRC造15階建の13階。浴室乾燥機・オートロック・宅配ボックスあり。最寄りのバス停1分で、カフェ・ジム・ドラッグストアも充実。 |
| 東日本橋パークフロント | 浅草線「東日本橋」駅 | 5 | — | — | 210,000円 | 12,000円 | 9月~ | 3DK | 55.4 | 1989年築(2021年内装フルリノベ) | 旧エリア | 南向きバルコニー。RC造5階建の最上階。キッチン・トイレ新品交換済。周辺は閑静で保育園・病院も近く、生活便利。 |
| 築地ソレイユコート | 浅草線/日比谷線「東銀座」駅 | 7 | — | — | 300,000円 | 20,000円 | 8月下旬 | 1K | 28.6 | 2022年築 | 新エリア | 築浅で使い勝手良好。RC造10階建の4階。2口IHコンロ・独立洗面台・Wi-Fi完備。最寄駅徒歩7分。近隣にコンビニ3軒・商業ビル・大学あり。 |
| ザ・築地ヴィアーレ | 日比谷線「築地」駅 浅草線「新橋」駅 |
5 10 |
— | — | 190,000円 | 19,000円 | 8月下旬 | 4LDK | 92.1 | 2006年築 | 新エリア | ファミリー層に人気の間取り。RC造9階建の2階、2006年築。床暖・食洗機・浴室TVなど設備充実。小中学校・スーパー・クリニックがすべて徒歩10分圏内。 |
| 人形町グレイスアヴェニュー | 浅草線「人形町」駅 | 13 | — | — | 210,000円 | 12,000円 | 即入居可 | 2SLDK | 69.5 | 2010年築 | 旧エリア | 納戸・バルコニー付き。RC造6階建の3階。ペット可(2匹まで)、モニター付インターホン・浴室乾燥機あり。近くに緑道・ドッグラン・大型公園あり。 |
事業所情報
| 会社名 | 事業所名 | 電話番号 | 営業時間 |
|---|---|---|---|
| (株)LayerX不動産 | 東銀座・築地事業所 | 03-XXXX-XXXX | 9:30~18:30 (平日)受付 |
| (株)LayerX不動産 | 六本木事業所 | 03-aaaa-aaaa | 9:00~18:00 |
| (株)LayerX不動産 | 東日本橋事業所 | 03-bbbb-cccc | 9:00~18:00 |
| (株)LayerX不動産 | 人形町事業所 | 03-dddd-dddd | 9:00~18:00 |
エリア(新 / 旧)
| エリア名 | 内見予約 |
|---|---|
| 新エリア | 電話またはWeb |
| 旧エリア | 電話 |
5. まとめ
本記事では、Gemini 2.5の会話型画像セグメンテーションについて、できる事と実装方法・他モデルとの比較について公式情報を元に解説した後、スライドからの情報抽出を例としてドキュメント処理への活用例を紹介しました。
複雑なドキュメントを人間が読むのと同じような形で情報抽出するには、従来のOCRライブラリによる処理ではドキュメントの構造性への対応が不十分な場合が多いです。
このような場合に、GeminiのようなマルチモーダルLLMは自然言語で抽出したい情報を指定できるため、OCRライブラリの代替として非常に有用な選択肢の一つになります。
また、複雑なドキュメントに立ち向かうにはいかに情報の粒度を細かく分け、内容を解きほぐしていくかが重要になるので、Gemini 2.5の会話型セグメンテーションはある情報の存在する領域を特定し、絞り込みを行うための手段として大きな価値を発揮するでしょう。
今回紹介した画像セグメンテーションのドキュメント処理への活用方法はあくまで一例に過ぎません。Gemini 2.5の会話型画像セグメンテーションをドキュメントに合わせて様々な使い方で適用することで、これまではできなかった複雑なドキュメント処理が可能になるかもしれません。