こんにちは!バクラク事業部 機械学習・データ部 データチームの@TrsNiumです。
我々のデータ基盤では、データカタログソリューションとしてOpenMetadataを導入し、データのビジネス的な意味(ビジネスメタデータ)、運用状況や品質情報(オペレーショナルメタデータ)、技術的な属性や構造(テクニカルメタデータ)を一元的に管理しています。OpenMetadataの導入により、多様なデータベース、BI、CRMとの連携が実現し、データ管理の効率化と利用統計の可視化が可能となりました。さらに、データの検索性が大幅に向上し、データガバナンスの強化にも寄与しています。
OpenMetadataは、データカタログソリューションとしての要件を十分に満たすツールです。しかし、そのインフラストラクチャ(以下、インフラ)にかかる金銭的コストが高いという課題がありました。
本記事では、OpenMetadataの標準的なインフラストラクチャと我々のデータ基盤のインフラを比較します。なぜその構成を選択したのか、実際にどのような効果があったのか、そしてデメリットについても紹介します。
OpenMetadataの活用事例として、データカタログへのLookerStudioレポート情報の取り込みや、導入背景を紹介したスライドなども公開しています。これらの資料も併せてご覧いただくと、より理解が深まるかもしれません。
OpenMetadataの標準的なインフラ構成
OpenMetadataの標準的なインフラ構成と我々のデータ基盤のインフラ構成を比較する前に、それぞれのインフラ構成について紹介します。まずは、OpenMetadataの標準的なインフラ構成を紹介します。OpenMetadataの標準的なインフラストラクチャの構成は以下の図のようになります。
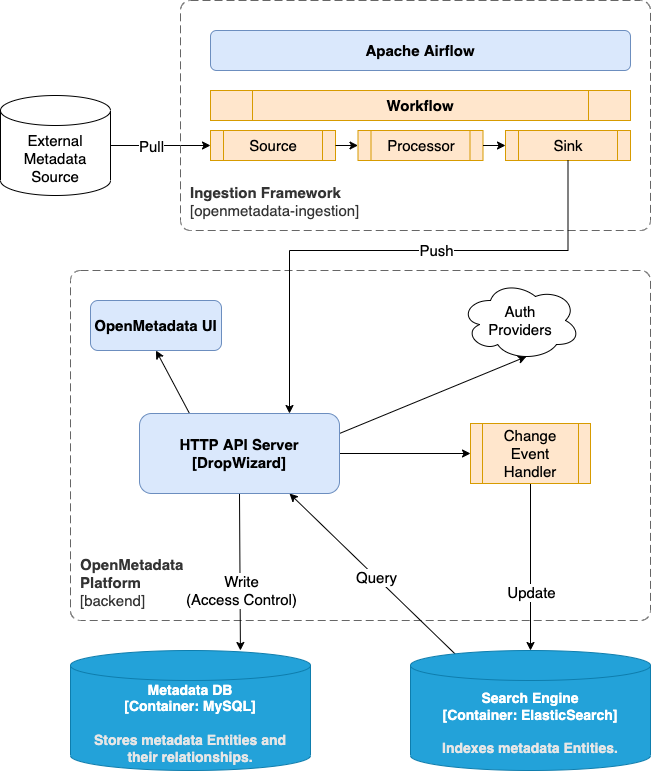
https://docs.open-metadata.org/v1.4.x/developers/architecture より引用
おもな構成要素は主に以下の4つです。
・ HTTP API Server
・ Metadata DB(MySQL, PostgreSQL)
・ Search Engine(Elasticsearch, OpenSearch)
・ Apache Airflow
それぞれ次のような役割をします。
HTTP API Server
Webフロントエンドの静的リソース配信とWeb APIの提供を担当します。ユーザーからのリクエストやメタデータ取り込みバッチからの要求に応じて、後述するMetadata DBとSearch Engineに新しいレコードやインデックスを追加します。
Metadata DB (MySQL, PostgreSQL)
OpenMetadata上のメタデータや設定値を含む全てのデータを格納するデータベースです。API Serverからのリクエストに応じてメタデータや設定値を更新します。
Search Engine(Elasticsearch, OpenSearch)
ユーザーからのリクエストを高速に処理するための検索エンジンです。HTTP Serverからのリクエストに基づいて検索インデックスの読み取りや更新を行います。また、検索エンジンの検索インデックスは、Metadata DBを基に定期的に再構築されます。
Apache Airflow
OpenMetadataへのメタデータ取り込みのためのバッチ実行基盤です。メタデータ、テーブルプロファイル、データ系譜、クエリログ、メタデータの統計情報などを取り込みます。
LayerXにおけるOpenMetadataのインフラ構成
次に、弊社におけるOpenMetadataのインフラ構成を紹介します。我々のデータ基盤では、OpenMetadataをAWS上に構築しています。以下の図が構成図です。
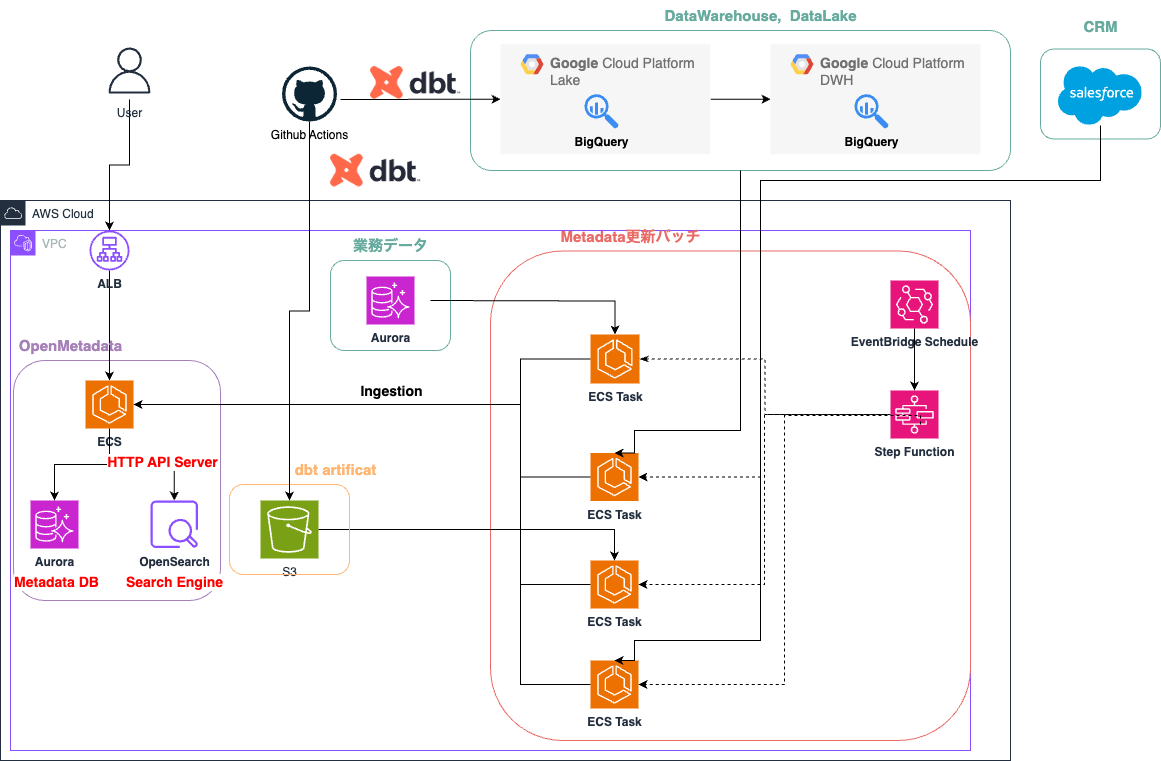
OpenMetadataのインフラ構成は図に示すとおりです。HTTP API ServerはAmazon ECS上で、Metadata DBはAmazon Aurora Serverless上で、そしてSearch EngineはAmazon OpenSearch Service上でそれぞれホスティングしています。
Apache Airflowに関しては、我々のデータ基盤では利用しておらず、標準的な構成から少し逸脱するため、詳細に説明します。OpenMetadataの標準構成では、メタデータ取得等のバッチ実行基盤としてApache Airflowを利用しています。しかし、我々のデータ基盤ではApache Airflowを構築せずにOpenMetadataを運用しています。OpenMetadataはApache Airflowで実行しているメタデータ取り込み等の処理を、コマンドラインインターフェースで実行するためのopenmetadata-ingestionというパッケージをPyPIで公開しています。このパッケージが提供する metadata コマンドを実行することで Apache Airflow を構築せずともメタデータ取り込み等の処理を実行することができるようになります。我々のデータ基盤ではこの metadata コマンドを Amazon ECS の Task として実行できるようにし、Amazon EventBridge Scheduler と AWS Step Functionsによってオーケストレーションしています。具体的には、EventBridge Scheduler から Step Functions を起動し、最終的に ECS Task 上で metadata コマンドを実行しています。これにより、各種メタデータをOpenMetadataへ取り込んでいます。
このような構成にした背景は、Apache Airflowを運用するコストが高いと判断したためです。もともと我々のデータ基盤ではApache Airflowの運用実績がなく、新たに構築・運用する必要がありました。Apache Airflowの構築・運用はそれぞれ、マネージドサービスであるAmazon Managed Workflows for Apache Airflowを使った場合は金銭的なコストが、Amazon ECSやAmazon Elasticache等で構築した場合は運用コストがかかります。これらのコストと比較して、metadata コマンドを利用したワークフローを構築するほうが、我々のチーム構成や技術スタックを鑑みた時にコストが低いと判断しました。
LayerXのOpenMetadataインフラ構成における課題
ここまで、弊社におけるOpenMetadataの構成について詳細に紹介してきました。この構成は、弊社の環境に合わせて構築されていましたが、同時にいくつかの課題がわかりました。
最も大きな課題は、インフラ構成における金銭的コストの高さです。特に、費用の内訳をみると、Amazon Aurora ServerlessとAmazon OpenSearch Serviceが大きな割合を占めていることが分かりました。この課題に対処するため、いくつかの対策を行いました。
まず、Amazon Aurora Serverlessのコスト最適化に取り組みました。具体的には、各種情報の取り込みバッチの頻度を見直し、Amazon Aurora Serverlessの最大Capacity値を引き下げました。これらの対策により、情報の鮮度は若干低下しましたが、費用は約3分の1の削減を実現できました。
一方、Amazon OpenSearch Serviceのコスト削減には、より根本的なアプローチが必要でした。なぜなら、Amazon OpenSearch Serviceの構成を見直すだけでは微量の費用削減効果しか見込めなかったためです。大幅な費用削減効果を生むために、いくつかの案を検討した結果、Amazon OpenSearch Serviceの利用を辞め、Amazon ECS上にホスティングすることを決めました。次のセクションでは、なぜAmazon OpenSearch ServiceをAmazon ECSに置き換えることにした理由と、その方法について説明します。
新・OpenMetadataのインフラ構成
コストを削減した新しいOpenMetadataのインフラストラクチャの構成図は次の通りになります。
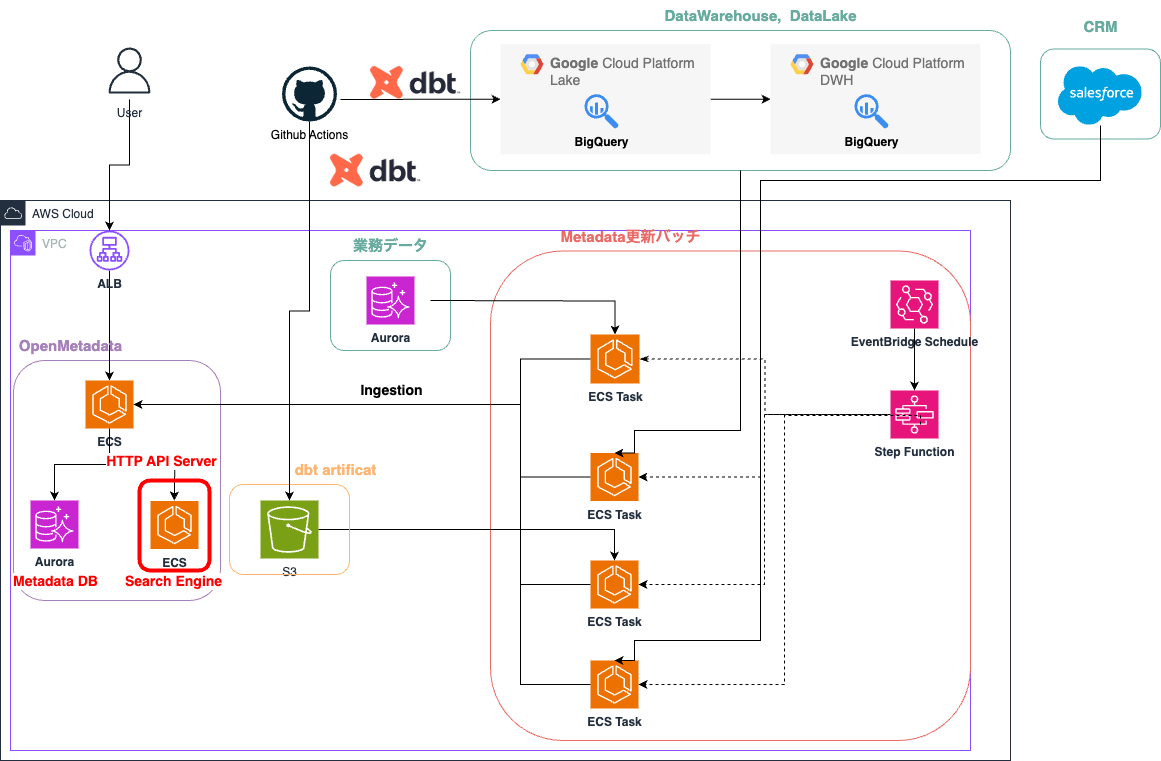
違いは、Amazon OpenSearch Serviceを、Amazon ECS上にホスティングしたOpenSearchと置き換えた点です。Amazon OpenSearch ServiceからAmazon ECS上のOpenSearchに変更したことで、金銭的なコストは大幅に下がりました。一方で、マネージドサービスから自前ホスティングに変更したことで運用コストが上がっています。この運用コストについて、どういった見込みで変更を行ったかについて記載します。
まず、運用面で一番の懸念事項は、OpenSearchに格納したデータの消失リスクでした。OpenSearchのコンテナがダウンしたとき、データを永続化していなければデータが消失してしまいます。我々はこのデータ消失リスクに対して、データ消失を許容することにしました。なぜなら、OpenSearchに格納される検索インデックスは、Metadata DBから復旧可能であるためです。加えて、復旧に要する時間は我々のデータ量の場合は約10分でしたが、この復旧時間に関しても許容することにしています。これは、現在のOpenMetadataの利用用途から、障害発生から復旧までのリードタイムが長くても許容できると判断したためです。許容できない要件が入ってきた場合はAmazon EFS等を使用した永続化を検討しようと考えています。
また、これまでのOpenMetadataの運用実績から、OpenSearchに対して急激な負荷上昇などの予測不能なワークロードの変化は発生しないことが分かっていました。そのため、継続的にメトリクスのモニタリングさえ行えていれば、計画的な再起動を行うことで運用コストを大幅に下げられることが見込めていました。
以上の点から、運用コストの増加はコントロール可能なレベルに低減できることが見込めたため、OpenSearchをマネージドサービスから自前ホスティングに変更することを決定しました。 この変更により、OpenSearchのインフラにかかるコストが約3分の1になり、大幅なコスト削減を実現できました。
新・OpenSearchインフラ構成におけるデプロイ
最後に、OpenSearchをAmazon ECS上にホスティングする際に行ったデプロイ時の工夫について説明します。OpenSearch上の検索インデックスの永続化を行わない構成にしたため、OpenSearchコンテナの起動直後に検索インデックスを作成する必要があります。これは以下のコマンドで行います。
$ sh openmetadata-ops.sh reindex
OpenMetadataでは、openmetadata-opsというスクリプトが提供されています。このスクリプトは、OpenMetadataのバージョンアップ時にMetadata DBのスキーマやSearch Indexのインデックスをマイグレーションする機能や、今回のようにMetadata DBからSearch Indexへデータを再インデックスする機能を備えています。openmetadata-opsスクリプトの詳細については、以下のドキュメントをご参照ください。
docs.open-metadata.org
このコマンドをOpenSearchコンテナの起動直後に実行するために、ECSタスク内で別のコンテナとして設定し、依存関係(dependsOn)を持たせて起動しています。以下は、ECSタスク定義の抜粋です。
{ // 省略 "containerDefinitions": [ { "name": "opensearch-app", "image": "opensearchproject/opensearch:2.7.0", "essential": true, "portMappings": [ { "containerPort": 9000, "hostPort": 9000, "protocol": "tcp", "name": "tcp9000" } ], "environment": [ { "name": "OPENSEARCH_JAVA_OPTS", "value": "-Xms4096m -Xmx8192m" }, { "name": "discovery.type", "value": "single-node" }, { "name": "http.port", "value": "9000" }, { "name": "plugins.security.ssl.http.enabled", "value": "false" } ], "healthCheck": { "command": [ "CMD-SHELL", "curl --silent --fail localhost:9000/_cluster/health || exit 1" ], "interval": 15, "timeout": 10, "retries": 10 } }, { "name": "opensearch-load-index", "image": "docker.getcollate.io/openmetadata/server:1.4.1", "essential": false, "command": [ "bootstrap/openmetadata-ops.sh", "reindex" ], "environment": [ // 省略:RDSの接続情報などを環境変数に設定 // ref. https://docs.open-metadata.org/latest/deployment/bare-metal ], "dependsOn": [ { "containerName": "opensearch-app", "condition": "HEALTHY" } ] } ], "cpu": "2048", "memory": "8192", "volumes": [], "placementConstraints": [] }
opensearch-load-index コンテナは、opensearch-app のヘルスチェックが成功した後に起動するように dependsOn を設定しています。これにより、OpenSearchが正常に起動した後で検索インデックスの再構築が行われます。
まとめ
本記事では、弊社におけるOpenMetadataのインフラストラクチャ構成とその最適化について詳細に解説しました。標準的な構成からの変更点、そのような変更を行った理由、そして実際に得られた効果について説明しました。特に、コスト削減を目的としたAmazon OpenSearch ServiceからAmazon ECSへの移行に焦点を当て、その過程で直面した課題と変更、そして結果として得られたメリットとデメリットを紹介しました。OpenMetadataを導入する際の参考になれば幸いです。