LayerX Fintech事業部*1ので、ガバナンス・コンプラエンジニアリングをしている @ken5scal です。
はじめに
本ブログは、以前執筆した「SIEMの限界」から「データ基盤への道」への具体的な取り組み、いわば試行錯誤の途中経過をお伝えするものです。今後も継続的に試行錯誤や改善策をお届けしていく予定ですので、この過程に興味をお持ちの方は、ぜひフォローをお願いいたします。 tech.layerx.co.jp
「SIEMの限界」で述べた通り、当社は「メンテナンスや運用、対応策にかかるコストと工数に比して、自社の持てるコントロールや自由度が限定的」という課題を既存のSIEMに感じています。 まず、SIEMの強みとされる相関分析の効果を最大化するには、監査ログ以外にも以下のデータを相関できる必要があります。
- ユーザーやデバイス等の資産情報
- 権限
- NWトラフィック
特にNWトラフィック量は財布を圧迫しがちです。 長期間にわたる統計や分析を行うには相応のストレージ容量が求められ、これも少なくない金銭的コストになります。
データの種別に応じてサービスを使い分けたとすると、データ連携はもとより、サービス毎に異なるクエリ言語の習熟おいてツラミが発生します。 昨今ですと、生成AIによるクエリ生成がトレンドですが、別ライセンス・別課金になりがちで、結局またお金の心配に帰着します。 ※私見ですが、結局、最終的な動作確認で人的リソースを投入しなければならい実感です。
では、それだけの金銭的コストをかけて自由度をどれほど得られるかと言うと、そこまでありません。 もちろんマネージドサービスなので限定的になるのは当然ですが、より事業のリスクに隣接したい場合、カスタマイズ性は欠かせません。 複雑なユースケースに要求されるクエリは複雑になり、そうするとクエリの実行時間とメンテナンスの工数が増大していきます。 可能であれば中間データを作成したいところですが、SIEMではなかなかハードルが高いです。
連携ができないデータ管理についても困り事が付きません。手動で取得しなければならないCSV、メールでのみ送られてくるイベント等のことです。 これらの保管場所、分析方法についても他のと一貫したデータマネジメントが必要ですが、SIEMにいれる場合、そのためにイベントをSIEMにあわせた方法でAPIリクエストを作成しなければなりません。
つまるところ、当社にとっての最大の課題は、メンテナンスや運用にかかるコストと工数に比して、自社でのコントロール性や自由度が限定的であるという点でした。

このような状況から、「次世代」のセキュリティ管理を模索するため、私たちはデータエンジニアリングのアプローチを取り入れる方向に舵を切りました。具体的には、セキュリティ周りの相関分析をするにあたり、データの取り込み・変換・提供のライフサイクル、そしてその底流をAWSで完結することにしました。

そこで、まずはAmazon Security Lakeにデータを集約することから始めています。本ブログは、Amazon Security Lake を使った簡単な構成と今、見えている課題について記述します。
Amazon Security Lakeとは
セキュリティに特化した分析を効率的にするためのデータレイクサービスです。データはOSCF(Open CyberSecurity Scheema Framework)に正規化されApache Parquet形式で保管されます。分析時はOpenSearchやQucikSightを使った可視化、またはAthenaのようなクエリベースでの集計が可能です。

弊社では、これをもとに既存の構成から下図の様な構成になりました。といっても、元々アーカイブしていたS3バケットから、Security Lakeのコンポーネントを追加したぐらいの変化です。 なお、試行錯誤という言い訳のもと、構成は目まぐるしく変化しています。同時に、この自由度こそ求めていたことでもあります。

とりあえず複数のソースシステムからログを取り込み、Archive専用のS3に保存、それをObject Replicationにより分析アカウントにレプリケートしています。 続いてLambdaがデータをOCSFに変換し、Security Lakeに投げ込んでいます。 それに対し、Lambdaがシンプルな監査ユースケースを想定したジョブを日次で実行しています。
ソースシステムについては、当初と変わっていません。 AppFabricとDataDogの使い分けについては、基本的にDataDogを優先しています。 AppFabricはDataDogに連携できないソースシステムにのみ利用しています。 AppFabricは連携先のイベントをOCSF形式で自動保存してくれるのは便利ですが、課金体系が連携先のユーザーアカウント数となっており、IdPの存在を前提にした環境と相性がわるいためです($3/ユーザー)。
今回試したユースケースは次の通りです。これらをAthenaあるいは日次のLambdaから行うことでレポート・アラートをあげています。 これらをAthenaあるいは日次のLambdaから行うことでアラートをあげようとしています
- ユーザーディレクトリで暫く活動のないアカウントの集計
- サインイベントから、フィッシング耐性のない認証器でおこなっているユーザーと認証先アプリの集計
※画像はdev環境のデータを集計したものです。


Security Lakeのコスト
これらを通して事業リスクに隣接したセキュリティ分析に必要な自由度が手に入れられそうなイメージがわきました。 では、気になるコストですがかなり安いです。DataDog SIEM自体もそこまで高くないですが、VPC Flow logやRoute53 Query logといった大容量データを考慮すると財布に優しいです。 ※DataDog SIEMの価格にはCloudtrail連携の分も含まれます。今後、Security Lakeが正式採用された暁には連携解除できるので、より安くなるはずです。
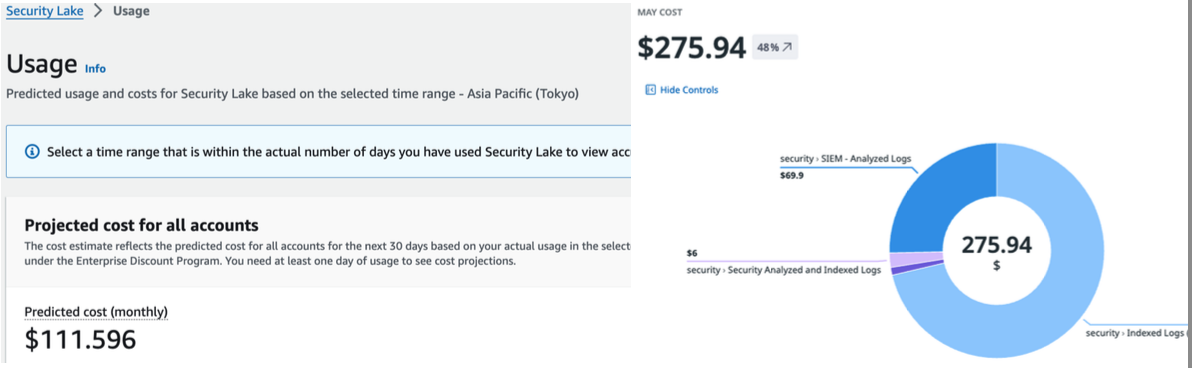
ただここに取り込みや変換をするワークロード(主にLambda)のコストはのっていません。 今のところ許容範囲ではありますが、コストとパフォーマンスチューニングのバランスについては中々苦労しそうです。*2
データ基盤としての成熟度はゼロ
これらの施行をする傍ら、当社内でバイブルと呼ばれているものを含むデータエンジニアリング・データマネジメントの本を読んでいました。
- データエンジニアリングの基礎 ―データプロジェクトで失敗しないために
- データマネジメントが30分でわかる本
- AWSの薄い本Ⅲ データ分析基盤を作ってみよう 〜設計編〜
- AWSの薄い本Ⅴ データ分析基盤を作ってみよう 〜性能測定編〜
わかったことは、何もわかってないということです。 Lambdaのデプロイ先やツール選定とっても全然たりていません。
データエンジニアリングライフサイクルについては全く意識されていません。
データカタログの導入タイミング、それらを加味した際のAWSのの構成等々。
dbt....?? ドラゴンボールの新しいシリーズですか?
また、いわゆる底流における性能測定やエラーハンドリングなどの非機能要件については、今まで自分が怠ってきた可用性まわりでの難しさを体感しています。
本ブログを書いてる最注に何度も「あれ、これは本来こうすべきでは?」だとか「要件漏れてる...」みたいな気づきが後を尽きません。
また、セキュリティというドメインでのデータエンジニアリングについてもたくさん悩んでいます。 Windows Defender for EndpointといったEDRのログをAWS側に集約となると、ある程度リアルタイム性が犠牲になるので、それをどう整理するか。 クエリの根拠とするルールのコード化において、CELとOPAの使い分け方法などなど。
まずは、「データエンジニアリングの基礎」にあるLv1「データを使い始める」に到達することが当面の目標になるでしょう。 ※それこそ撤退する判断を含め
「次世代」と言う名の温故知新
ここまで長々、読了いただいてありがとうございました。 本件ご覧の通り、まるで「次世代」ではありません。仮に当社で「次世代」だとしていて、この内容はNetflixが3000年前に通過した所です。
しかし、このYoutubeを初めて見たときの「はー、さすがNetflixだなー」といった憧憬から、 やや時間がかかったものの、その入口に片足を踏み入れられたことに、今はとてもワクワクしています。
このワクワクを現実の形に落とし込む、そのための課題を解決していきたい方々、落とし込み方法に知見がある方々、是非、ご連絡をお待ちしています。
- 応募: 【Fintech】DevOps / 株式会社LayerX
- 面談: デジタル証券と資産運用ビジネスを、一緒にDevとOpとSecしませんか?
- 雑談: https://x.com/ken5scal
