LayerX Fintech事業部(三井物産デジタル・アセットマネジメント(MDM)に出向)で、セキュリティ、インフラ、情シス、ヘルプデスク、ガバナンス・コンプライアンスエンジニアリングなどを担当している @ken5scal です。
本件はLayerXが主催するコーポレートエンジニアリング・情シスに関するコミュニティイベント「CorpEn Night #1」で発表した内容をまとめたものです。
Fintech事業部では、サイバーセキュリティ管理の検出・監視基盤として、一般的なSIEM製品ではなくAWS Security Lakeを採用しました。これにより、セキュリティイベントだけでなく情報資産も含めた包括的なデータの取り込み、保存、提供が可能となり、まだまだ途上ではありますが、一定の成果を感じています。しかし、現実は予想外の問題が連続しており、日々課題が生じています。本日は、コスト関連の一部についてお伝えしたいと思います。
意思決定に基づくはずのオペレーションを追跡し、監査を効率化する話 - LayerX エンジニアブログ
SIEMからデータ基盤へ - Amazon Security Lakeを試してる話 - LayerX エンジニアブログ
ログ一元管理の本質とSIEMの限界 - データ基盤への道 - LayerX エンジニアブログ
Security Lakeで発生するコスト
Security Lakeでは主に自動生成されるリソース及びそれにかかるコストです。 次の図の通り、Security Lakeはそれ単体で成り立つサービスではなく複数のAWSサービスをsuiteとして提供しています。
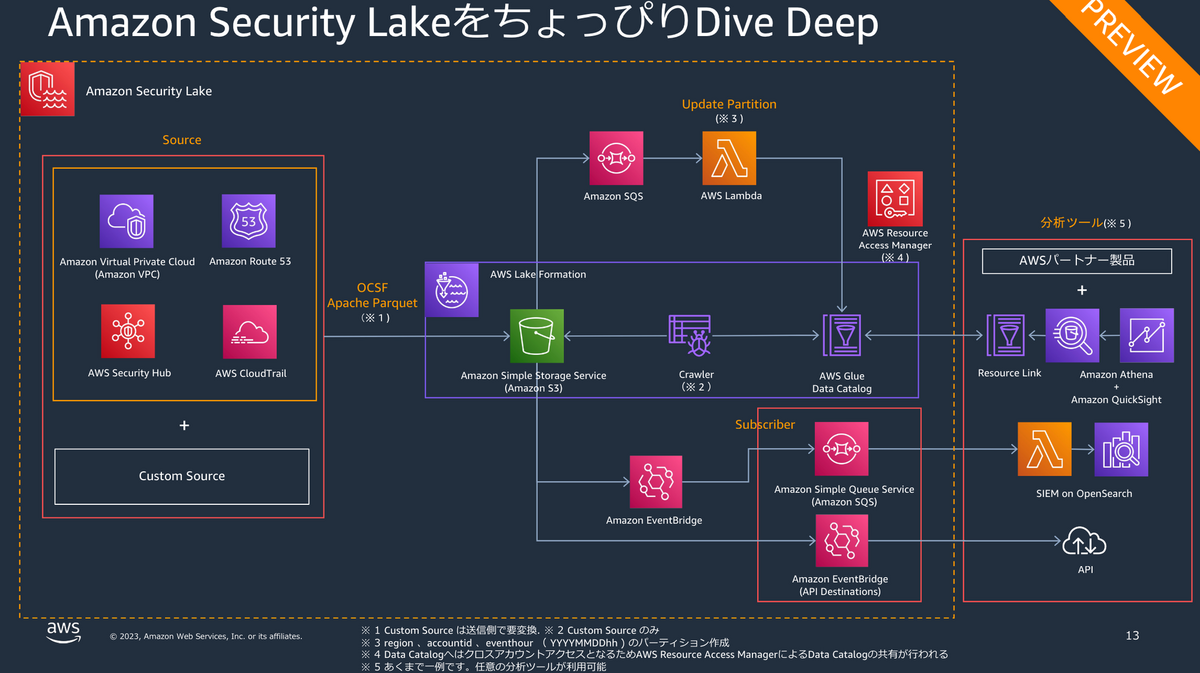
したがって、付随して作成されるS3, Lambda, EventBridge, SQS, Glueにおけるコストも勘案しなければなりません 。逆にいえば、Security Lakeに表示される価格は、これらを含みません。
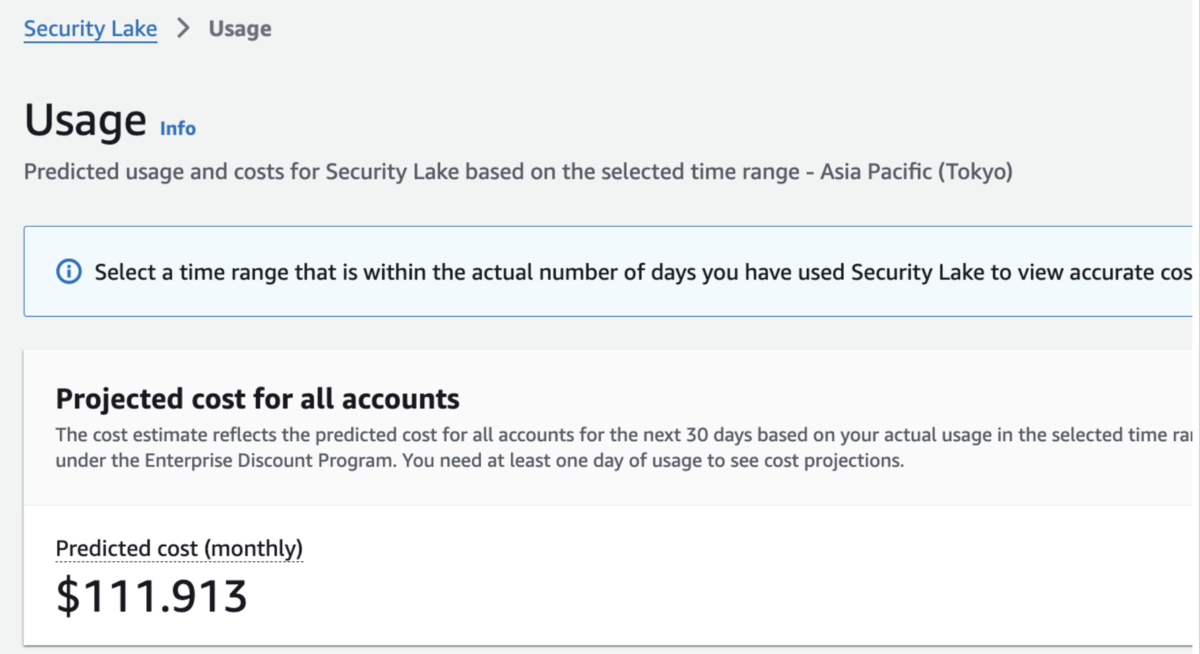
当然、ある程度のログ量は事前に計算してはいるのですが、LambdaやS3において想定外のコストが見られました。
※赤線がLambda、青線がS3です

Lambdaでのコスト増
対象のLambdaはSecurity Lakeに AmazonSecurityLakeMetastoreManager という名前で作成されます。このLambdaは公式のユーザーガイドによると、OCSF形式でS3にアップロードされたデータをもとにAWS Glueのパーティションを作成します。ただ、実際の挙動を見るとメタデータの更新もしているようです。
このLambdaはSQSからメッセージを受け取りますが、ご覧の通りInvocationが多く、またdurationが短いために多くの頭打ちが発生していました。初期値のdurationが10秒であったため、retryが多発していたようです。そこで、シンプルにdurationを5分に設定したところ、実行状況及びコストが落ち着きました。
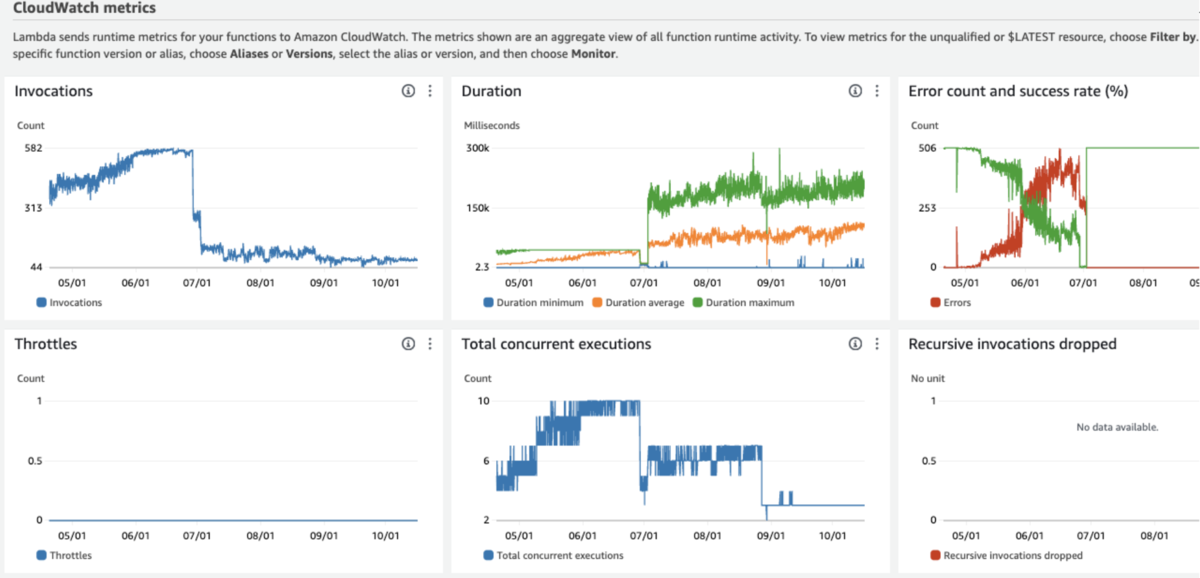
現時点でコストは落ち着いていますが、ログ量や種別の増加に伴い、より高メモリ、長durationになるでしょう。お金をかけて対処することはチューニング完了までの一時的な手段となるので((https://speakerdeck.com/fujiwara3/hack-at-delta-24-dot-10))、Lambdaのコードをチューニングしたいところです。しかし、コードはコンパイルされたJavaで公開されていません。これをどうチューニングしていくかが、今後の課題の一つになりそうです。
S3
これまでにある程度のデータ量や変化量を見積もっていたため、S3のコスト増加はかなりの驚きでした。自前で作成したカスタムログソースが原因かと思い、各オブジェクトのパスを確認したところ、実際にはVPCフロー、CloudTrail、Lambda実行、Route53のメタデータが大幅に増えていました。それぞれのメタデータが8.7TB、5.8TB、3.7TB、2.7TBにも達していたのです。
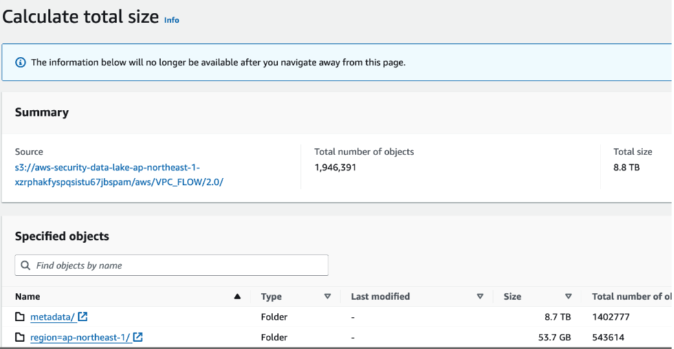
対策自体は簡単でLifeCycleを設定すればいいだけです。 Security LakeはregionごとにLifecyclceを設定できますが、adwaysさんの名ブログ「AWSでの法令に則ったログ設計及び実装/分析」にもある通り、ログ要件に従いたいところです。例えば、トラフィックログは実際のアプリログに比べて短期間でアーカイブしていいはずです。 本来、柔軟なコントロールを求めて通常のSIEMからSecurity Lakeにしたのですから、今後はデータの種別ごとにオブジェクトパスをきっていく予定です。
一方、生成されるメタデータの妥当性自体については悩ましいです。
正直データエンジニアリングに疎く、このメタデータの増大量がテラバイトレベルになることが一般的なのか判断つきません。それを調べようにも、先に述べた通り当メタデータを生成しいるであろうSecurity Lakeまたは AmazonSecurityLakeMetastoreManager Lambda はブラックボックスであり、チューニングが困難です。
生データは保持しているのでなんとかなると思いつつ、保管料残すとをどうするかは来年度にもちこし予定です。
終わりに
このように、LayerX Fitench事業部の出向先であるMDM コーポレートシステム部では、データエンジニアリングに日々、四苦八苦しています。同じような課題に挑戦したい方や、経験を活かしたいとお考えの方は、ぜひお話を聞かせてください。カジュアル面談の申し込みをお待ちしております!