ドーモ、読者のミナ=サン、LayerX Fintech事業部(三井物産デジタル・アセットマネジメント(MDM)に出向)で、@ken5scalです。
久しぶりのAmazon SecurityLakeとログ系のブログです。セキュリティにおいても、紀元前よりサーバー、ネットワーク機器、アプリケーションなどから出力されるログを一元的に収集し、監視や分析を行うことで、インシデントの早期発見や対応が可能になることはよく知られています。その代表的なソリューションが、そう、皆様よくご存じのSIEMです。 当社では、従来のSIEM(DataDog SIEM)に加え、データエンジニアリング的なアプローチにチャレンジ、より強力なデータ基盤を用いた検知エンジンを目指しデータレイクハウスであるAWS SecurityLakeを採用しました。
こういった従来のSIEMにおける課題や経緯については、下記のブログをご参照ください。
- ログ一元管理の本質とSIEMの限界 - データ基盤への道 - LayerX エンジニアブログ
- SIEMからデータ基盤へ - Amazon Security Lakeを試してる話 - LayerX エンジニアブログ
クエリエンジンどうする?
さて、このデータレイクハウスに対して、採用しやすいクエリエンジンはAthenaでしょう。実際に当社でもAthenaのクエリをもとにした検知・監査の仕組みがあります。
Athena自体は素晴らしいサービスに疑いようはありません。しかし、どうしてもAWSコンソール上でのレイテンシを避けられません。特に、データを試行錯誤しながら検知ロジックを開発するには必ずしも最適な体験とは言い難いです。 特に、緊急のフォレンジック調査や新しい検知ロジックのプロトタイピングといった、即時性が求められるアドホックな分析タスクにおいては、これを感じることが多いです。
そこで、試験採用しているクエリエンジンが今回紹介する「DuckDB」です。 本記事では、このDuckDBがいかにして軽量かつ強力な検知エンジンの基盤となりうるか、その具体的な方法と試行錯誤の過程を共有したいと思います。 *1
DuckDBについて簡単に紹介
DuckDBは、カラム指向なストレージに対してSQLクエリを実行可能なオンライン分析処理(OLAP)に秀でたデータベースです。その特色としては次の通りです。
- シングルバイナリ: ローカルでインストールするだけcliとして動作するだけでなく、アプリケーションにライブラリとして直接組み込めます。サーバーのセットアップが不要です。
- 豊富なデータ拡張: さまざまな拡張機能があり、ファイルフォーマットの直接的な処理、クラウドストレージとの連携、Apache Icebergのサポートを可能とする拡張機能が豊富です。
- インメモリ: メモリ上で処理するので、チューニングにおいて物理的にケアを必要とするポイントが少ないです。
これにより、AWS SecurityLake(などのApache Icebergをサポートしたデータレイクと、実際のデータを保管するクラウドストレージ)に対するクエリエンジンとして、DuckDBがイケているポイントが次の通りです。
圧倒的な手軽さとローカル完結性
SIEM基盤の構築・運用・保守といえば、ウェブコンソール上のネットワーク遅延を許容しなければならなかったが、DuckDBであればエンジニアが手元のノートPC、すぐにログ分析や検知ロジックのプロトタイピングを始められます 。この「やってみよう」と思える手軽さが、まず素晴らしい。昨今ではClaude CLIやGemini CLIとも相性がよいです。また、ローカルで作ったクエリをLambda等のワークロードにそのまま転用できる点も嬉しい。
ローカルマシンの性能をフルに利活用
会社のPCは安くありません。その贅沢なリソースを割り振られた高価なマシンスペックを使い、処理を高速化できます(コストの説明にもなる...)
クエリの金銭的コスト:
Athenaはクエリやその処理におけるデータ転送などにS3のコストがかかります。duckdbはクエリそのものにコストはかかりませんし、データベースをつくることでS3からのデータ転送は一度のみに限定することが可能です。もちろんクエリ実行を自動化する場合、Lambdaなどのワークロードコストはかかりますが、もとより安いのに加え、Saving Plansの活用によりコスト最適化も容易になります。
S3などクラウドストレージとのシームレスな連携:
- 多くのログはS3のようなクラウドストレージに保存されています。DuckDBはaws/ httpfs拡張機能を使えば、S3上のファイルをダウンロードせずに直接クエリできます 。データレイクとしてS3を使っている環境に、DuckDBを後付けするだけで、低コストかつ強力な分析基盤が手に入ります。AWS SSOのアクセストークンを環境変数にしたり、Profileにしておけば、それを読みこんでくれるため、リスクも低いです
活発なApache Iceberg拡張機能の開発:
最近はApache Iceberg Extentionも進化しているため、簡単にデータをスキャンできるだけでなく、メタデータやスナップショットをチェックできます。当社のデータ基盤であるAWS SecurityLakeはApache Iceberg形式なので相性もよいです。また、S3Tableなど特定ソリューションのサポートも素早く、メタデータ管理において課題のあるSecurityLakeからの乗り換えも比較的容易そうであることから、逆説的に安心してSecurityLakeを利用できます。
当社での実践
例えば、当社のような証券会社では特定口座を開設していただいてる投資家・お客様の売買における所得税・住民税を御本人にかわって源泉徴収し納付しています。この際にはマイナンバーを取り扱うことになるわけですが、マイナンバーのような特定個人情報の取扱には様々な厳密な要件があります。その1つとして事務取扱担当者の明確化があり、担当者以外のアクセスがないようしっかり管理する必要があります。そのために安全管理措置の1つとして「利用状況のログ分析」があります。 そこでプログラムが特定時期に作成する納付データの保管されたS3バケットのデータイベントをチェックする仕組みを、DuckDBで構築しているのが次の例です ※ただし応用が非常に効くので、必ずしも本業務要件にのみつかっているわけではありません。
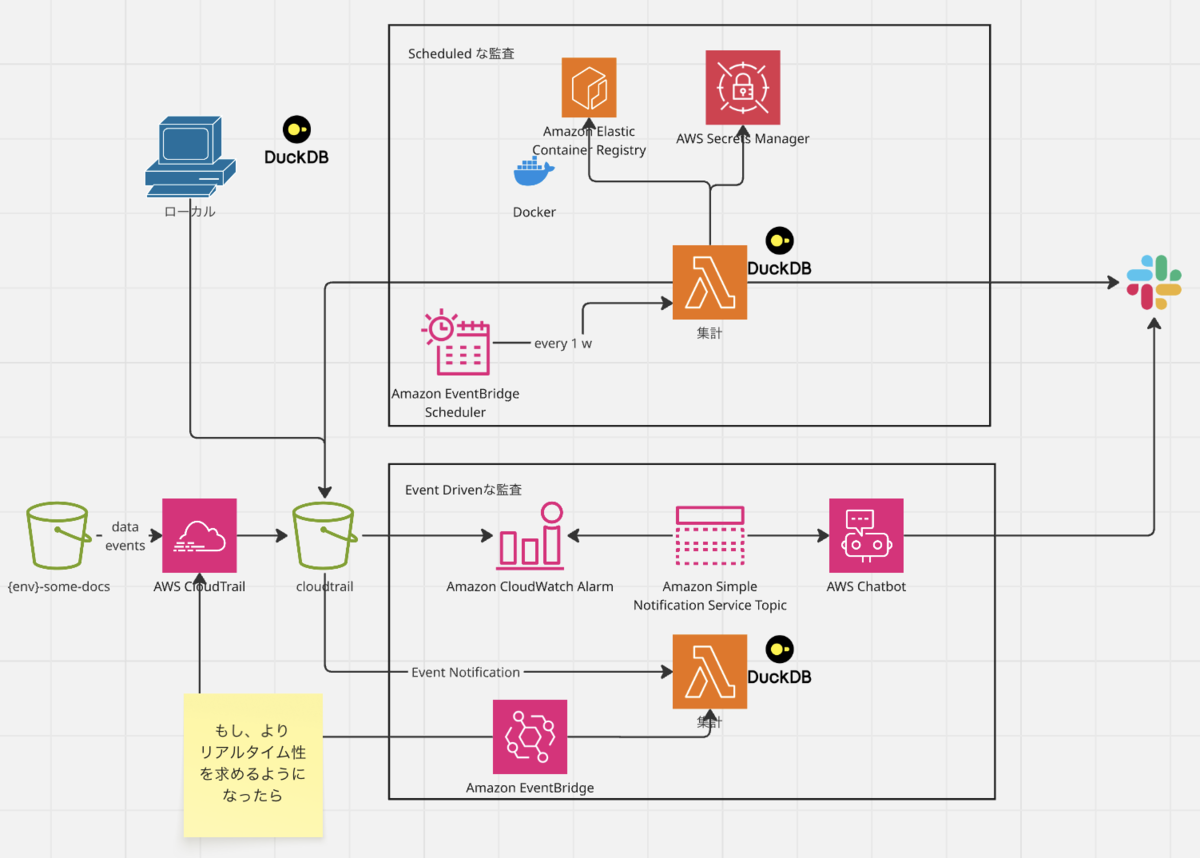
流れとしてはdev/stg環境のデータイベントから、DuckDB cliを用いたクエリ作成をします。 もし毎回、duckdb cliセッションごとにS3にfetchさせたくないのであれば、テーブル化すればいつでも永続化が可能ですし、そのデータベースをチーム間共有することもできます。 初回ロードこそ時間はかかりますが、それ以降はローカルのインメモリなので爆速です。 また、元データがparquet形式であろうがavro形式であろうがcsv形式であろうがjson形式であろうが、初回ファイル読み込み以降はそれを意識する必要がなく、すべてSQLクエリライクに処理可能です。
$ duckdb test.db D CREATE OR REPLACE TABLE hoge AS ( SELECT unnest(Records, max_depth := 2) FROM read_json_auto(s3://データイベントが入ってるバケット, maximum_object_size=500001600, union_by_name=true) ) D describe hoge; D SELECT CASE userIdentity.type WHEN 'AssumedRole' THEN COALESCE(userIdentity.sessionContext.sessionIssuer.userName, 'Unknown Role') ELSE 'Other-' || userIdentity.type END AS user_name, eventName as event_name, COALESCE(resources[2].ARN) as resource_arn, errorCode, COUNT(*) AS event_count FROM hoge WHERE eventSource = 's3.amazonaws.com' AND event_name LIKE '%Object%' AND resources[1].ARN = 'arn:aws:s3:::{{監査対象にしたいバケット名}}' GROUP BY user_name, event_name, resource_arn ORDER BY event_count DESC;
わたしはCursorでターミナルを立ち上げ、その隣にClaude CLIを走らせクエリを一緒に作成し、エラーが出たらCursorのAgent(Gemini 2.5 Pro)でデバッグしていました。
┌──────────────────────────────────────────────────────────────┬──────────────────────────────────┬────────────────────────────────────────────────────┬─────────────┐ │ user_name │ event_name │ resource_arn │ event_count │ │ varchar │ varchar │ varchar │ int64 │ ├──────────────────────────────────────────────────────────────┼──────────────────────────────────┼────────────────────────────────────────────────────┼─────────────┤ │ workload-role │ PutObject │ arn:aws:s3:::監査対象のバケット │ 1319 │ │ AWSReservedSSO_op │ ListObjects │ arn:aws:s3:::監査対象のバケット│ 207 │ │ AWSReservedSSO_op │ GetObject │ arn:aws:s3:::監査対象のバケット │ 53 │ │ Other-AWSAccount │ GetObject │ arn:aws:s3:::監査対象のバケット │ 53 │ │ batch-workload-role │ PutObject │ arn:aws:s3:::監査対象のバケット│ 38 │ │ AWSConfigMgtRole │ GetBucketObjectLockConfiguration │ arn:aws:s3:::監査対象のバケット│ 24 │ │ AWSReservedSSO_op │ HeadObject │ arn:aws:s3:::監査対象のバケット│ 18 │ │ AWSReservedSSO_dev │ ListObjects │ arn:aws:s3:::監査対象のバケット│ 17 │ │ AWSReservedSSO_op │ GetBucketObjectLockConfiguration │ arn:aws:s3:::監査対象のバケット│ 7 │ │ AWSReservedSSO_op │ GetObjectTagging │ arn:aws:s3:::監査対象のバケット│ 6 │ │ AWSReservedSSO_dev │ ListObjects │ arn:aws:s3:::監査対象のバケット│ 4 │ │ AWSReservedSSO_dev │ GetBucketObjectLockConfiguration │ arn:aws:s3:::監査対象のバケット│ 2 │ │ AWSReservedSSO_JSDAAntiSocialRecordOperator_cd7f14b721b9879a │ ListObjects │ arn:aws:s3:::監査対象のバケット│ 1 │ ├──────────────────────────────────────────────────────────────┴──────────────────────────────────┴────────────────────────────────────────────────────┴─────────────┤ │ 13 rows 4 columns │ └────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
ローカルでクエリができたので、今度はLambda用のプログラムを構成します。 とはいえ実施タイミングや対象バケットは実行環境によって変えたいので、検知構成ファイルを準備し、それをプログラム内でパースし、プレイスホルダを置換するようにしています。ここらへんのノウハウやymlはRipplingの事例をかなり参考にしています。
CreationDate: 2025-06-18
ModifiedDate: 2025-06-23
Author: k.suzuki
Identifier: ZENI-0000-0000 #適当です
Severity: Sev0
Enabled: True
Environment:
- dev,stg,prod
Period: 1d
OutputFormat: blocks # Slack-friendly rich formatting
Name: 特定個人情報のあるリソースに対するアクセス解析
Description: >
次のデータに対するアクセスを解析する
- "{{ENV}}-hogehoge"バケットへのアクセス
RequiredLogSources:
- CLOUDTRAIL.DATA_EVENT
Tags:
- Intrusion
- PolicyViolation
ScheduleTime: '0 23 * * 0' # 日本時間(月曜8時)UTCで日曜23時
MitreTactics:
- Defense Evasion
- Privilege Escalation
- Initial Access
MitreTechniques:
- T1078.004
AlertCategory: Unauthorized Access
EventSource:
- AWS-CloudTrail
SQL: > # 使ってます
SET preserve_insertion_order = false;
SET memory_limit = '5GB';
WITH raw_data AS MATERIALIZED (
SELECT unnest(Records, max_depth := 2) FROM read_json_auto({{DATE_RANGE}}, maximum_object_size=500001600, union_by_name=true)
)
SELECT
CASE userIdentity.type
WHEN 'AssumedRole' THEN COALESCE(userIdentity.sessionContext.sessionIssuer.userName, 'Unknown Role')
ELSE 'Other-' || userIdentity.type
END AS user,
eventName,
resources[1].ARN as resourceArn,
errorCode,
COUNT(*) AS eventCount
FROM raw_data
WHERE
eventSource = 's3.amazonaws.com'
AND eventName LIKE '%Object%'
AND resourceArn = 'arn:aws:s3:::{{ENV}}-{{BUCKET NAME}}'
GROUP BY user, eventName, resourceArn, errorCode
ORDER BY eventCount DESC;
package main
import (
//色々略
"database/sql"
_ "github.com/marcboeker/go-duckdb/v2" //公式です
"gopkg.in/yaml.v3"
)
func handler(ctx context.Context) error {
// Get environment variables
bucketName := fmt.Sprintf("%s", os.Getenv("BUCKET_NAME"))
// Fetch Slack webhook URL from AWS Secrets Manager
fmt.Println("Fetching Slack webhook URL")
slackWebhookSecretName := fmt.Sprintf("%s", os.Getenv("SLACK_WEBHOOK_SECRET_NAME"))
slackWebhookURL, err := fetchSecrets(ctx, slackWebhookSecretName)
if err != nil {
return fmt.Errorf("failed to fetch Slack webhook URL: %w", err)
}
// Initialize DuckDB
fmt.Println("Opening DuckDB")
db, err := sql.Open("duckdb", "")
if err != nil {
return fmt.Errorf("failed to open DuckDB: %w", err)
}
defer db.Close()
if err := db.Ping(); err != nil {
return fmt.Errorf("failed to ping DuckDB: %w", err)
}
fmt.Println("✓ DuckDB connected")
fmt.Println("Loading secret")
_, err = db.Exec(`
CREATE OR REPLACE SECRET secret (
TYPE s3,
PROVIDER credential_chain,
CHAIN 'env;config',
REGION 'ap-northeast-1'
);
`)
if err != nil {
return fmt.Errorf("failed to create secret: %w", err)
}
fmt.Println("✓ Secret loaded")
// Load detection config from YAML
detectionConfig, err := loadDetectionConfig("config.yaml")
if err != nil {
return fmt.Errorf("failed to load detection config: %w", err)
}
fmt.Printf("✓ Loaded detection config: %s\n", detectionConfig.Name)
// Also replace placeholders in Description if needed
detectionConfig.Description = strings.ReplaceAll(detectionConfig.Description, "{{ENV}}", env)
// Parse period and generate date range
now := time.Now()
period := detectionConfig.Period
if period == "" {
period = "1d" // default to 1 day
}
// Parse period to get UTC time range for S3 paths
startUTC, endUTC, err := parsePeriod(period, now)
if err != nil {
return fmt.Errorf("failed to parse period %s: %w", period, err)
}
// Generate S3 paths for the time range
region := "ap-northeast-1"
s3Paths := generateS3Paths(bucketName, accountID, region, startUTC, endUTC)
// Replace placeholders in SQL
sql := replaceSQLPlaceholders(detectionConfig.SQL, s3Paths, env, accountID)
fmt.Printf("Executing SQL query for period %s (%d S3 paths)\n", period, len(s3Paths))
rows, err := db.Query(sql)
if err != nil {
return fmt.Errorf("failed to execute query: %w", err)
}
defer rows.Close()
columns, err := rows.Columns()
if err != nil {
return fmt.Errorf("failed to get columns: %w", err)
}
// Collect all rows
var allRows [][]interface{}
for rows.Next() {
// allRowsにデータを入れる
}
// Get output format from config (default to blocks)
outputFormat := detectionConfig.OutputFormat
if outputFormat == "" {
outputFormat = "blocks"
}
// Format results using the specified format
formattedResults := formatResults(columns, allRows, outputFormat)
// Create Slack message
message := formatSlackMessage(env, formattedResults)
err = sendToSlack(slackWebhookURL, message)
if err != nil {
return fmt.Errorf("failed to send to Slack: %w", err)
}
return nil
}
これにより、特定期間の間を分析し、その結果を監査に使ったり、想定以外のアクセスがあった場合はアラートをあげるなどしています。前者の結果については、監査証跡のためになんとかレポートファイルにしたいところです。
まとめ:結局、DuckDBはいいぞ
ここまで見てきたように、DuckDBは、特に以下のようなユースケースにおいて、セキュリティログ分析・検知の強力な選択肢となります。
- 検知ルールのプロトタイピング
- 小〜中規模環境でのログ分析基盤
- データレイク(S3など)に保存されたログの直接分析
- インシデントレスポンス時のアドホックな調査
1つ難点があるとすればインメモリでLambdaを使いたい場合、チューニングが必要になります...この点についてはもうちょっと設計を詰めたほうです。
もちろん、これは「次世代」の技術というより、巨人が3000年前に通過した道かもしれません 。しかし、SIEMの限界を感じ、データ基盤への道を歩み始めた我々にとって、DuckDBは非常に強力な武器となります。このワクワクする技術を現実の形に落とし込み、課題を一つ一つ解決していくことに興味がある方、ぜひ一緒に挑戦しましょう。
*1:Athenaがサポートしている前PrestoSQL 現「Trino」も考えましたが、少人数でインフラも見る必要があるのでセットアップやメンテが容易そうなDuckDBを選びました。 反面、分散処理は苦手で、大規模な分析は諦めています。ただ分析対象の特性でサイズが100GBをこえることはまずないので、まあいいのかな、と思っています。