LayerX Fintech事業部*1で、セキュリティ、インフラ、情シス、ヘルプデスク、ガバナンス・コンプラエンジニアリングなど色々やってる @ken5scal です。
ログ一元管理の本質とSIEMの限界 - データ基盤への道 - LayerX エンジニアブログ SIEMからデータ基盤へ - Amazon Security Lakeを試してる話 - LayerX エンジニアブログ
現在は、当社の方針に基づき採択したAWS Security Lakeを前提にしたセキュリティ監視基盤をもとに、 当社事業年度における2Qの目標ということで、実際のユースケースに取り組むこととしました。
シナリオ選び
なにはともあれ、最終的には採用ヘッドカウントやスキルセットも含め体制化を念頭に入れて、継続的に取り組む必要があります。 その際に、当部の「セキュリティ基盤」にのみを意識をしてしまっては、一度承認されたとしても、内外の環境の変化をトリガーとした 再構成で見直しが必要になることもあります。 Googleが「Autonomic Security Operation*2」でいみじくも、「Don’t miss the oppounity to modernize relationship with the business」と言ってる通り、サステナブルな施策にするには、事業並びに顧客(投資家)に影響を与え、結びつきを強化できるような形にすべきと考えました。 ※「セキュリティ基盤への取り込みと自動化」の文脈でのターゲットを示しています。
そこで、全社インシデント訓練のシナリオとして何度か採用している「顧客の資産流失」を採用しました。 本訓練には、過去3年にわたり訓練しているリスクシナリオであり、また、代表取締役も参加しているものになります。 したがって、経営レベルでの関心事項、まさしく「Crown Jewel」に対するリスクといっていいでしょう。
脅威モデリングの結果、リスクが顕在化する複数の経路があることがわかりました。 そのうちの1つに、内部オペレーションという経路による資金流出というのがあります。 ただ、本オペレーション自体は、1) 支払手続きをワークフローで済ませつつ 2) 実際の口座上での手続き承認を必要とし、3) 手続き及び承認はVDI環境に限定されるため、ある程度、予防施策はできています。
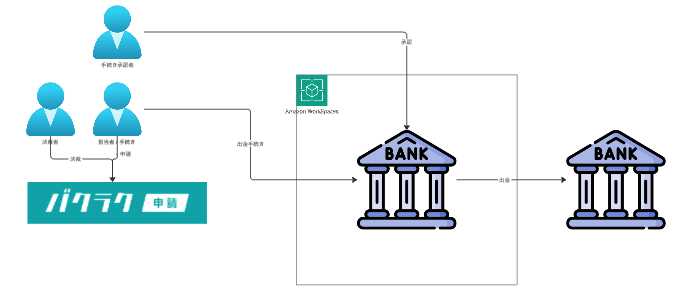
そこでより監査性の効率化や出金イベントの正当性におけるAssuranceを高めるといった方向性でも実装しています(※)。 ※ 当社ではガバナンス・コンプライアンスエンジニアリングなどと呼称しています。
プラン
出金手続きをとるためには、稟議システムで決裁が必要になります。 意思決定に基づいた出金や出金先が特定日数内にあれば正常となります。 したがって稟議システムのワークフローデータと、銀行口座の入出金履歴を突合し、 その結果を監査担当に送れば、(経営に近い)意思決定から実際のオペレーションまでの 追跡を実現できます。これがリアタイでできればとても格好いいです。
プランからの工夫が必要だったこと
正直、課題しかなかったのですが、いくつかピックアップします。
データソースの仕様
リアタイできればとても格好いいとかきましたが、つまるところ稟議システムも銀行入出金も外部のデータソースであり、 その仕様が制限になります。その制限とは、手動によるCSV出力でしかデータソースがサポートしていないことです。これ自体は、そもそものオペレーションが1ヶ月に数件しかないためクリティカルではないものの、月次のマニュアルオペレーションを与儀なくされます。 もともとログの永続化の目的でこのマニュアオペレーション自体はしていたのですが、自動化となると厳Cさを感じます。
また、ワークフロー自体が自然言語入力になっていました。
人間がレビューし決裁する、そして、人間が監査するのであれば、高度な認知機能を活かせるので問題ありません。しかし、機械処理にはそれは難しい。不可能ではないですが、追加の技術要素を実装しなければならないでしょう。幸いにもワークフローを管理できる体制にありましたので(というより、これを見越してしておいた)、当該オペレーション担当者と協力し、機械が読みやすく、人間が入力しやすいフォーマットにアップデートすることができました。
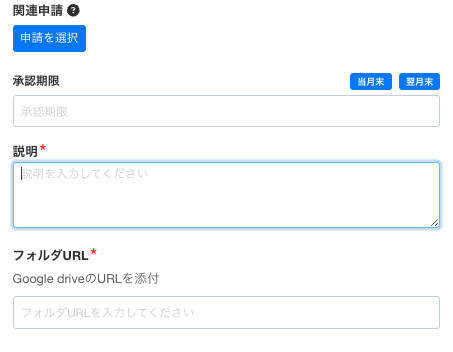
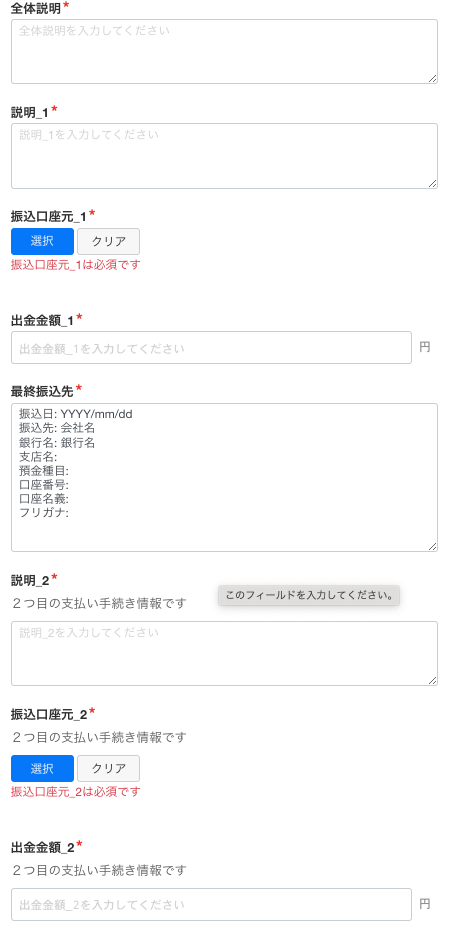
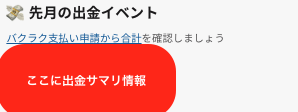
残念ながら、先述した通り、そもそものオペレーション発生頻度が低いので、「実際の出金情報と決裁済みの出金情報」の照合まではできていません。まあ、そのうちあるので機会をゆるりと待ち、現時点では当月における出金額をSlack通知しております
元データのフォーマット
各口座の出金履歴はそれぞれデータフォーマットがユニークでした。 中には詳細情報が全て1つのカラムにいれられたり、セパレータが統一されてないなどがありました。 他にも日付フォーマットが独自だったりするなど、正しく多様性を感じさせるようなものでした。 また、他のデータとの照合を楽にするために、OCSF(Open Cybersecurity Schema Framework)フォーマット に整理するなどを実施ました。思えば、データソースや元データと格闘する時間が多かった気がします...fivetranとかを入れたいモチベが良くわかりました。
クエリについては、GUIからでもできるようにAthenaクエリをTerraformで定義し、そのリソースIDを監査クエリの環境変数に読み込ませています。
resource "aws_athena_named_query" "audit" {
query = <<EOF
SELECT * FROM HOGE
EOF
}
resource "aws_lambda_function" "audit" {
environment {
variables = {
ATHENA_SAVED_QUERY_ID = aws_athena_named_query.entra_stale_users_auditor.id
}
}
}
監査クエリを定期的に実行するGoでは、以下のようにクエリIDからクエリを取得し実行しています。
aClient, err := newAwsClient(context.Background())
if err != nil {
return errors.Wrap(err, "failed to create aws client")
}
log.Printf("[INFO]: get query string: %s", athenaSavedQueryId)
today := time.Now()
yesterDay := today.AddDate(0, 0, -1)
q, err := aClient.formQueryString(athenaSavedQueryId, yesterDay.Format("20060102"), time.Now().Format("20060102"))
if err != nil {
return errors.Wrap(err, "failed to get named query")
}
log.Printf("[INFO]: execute query: %s", *q)
o, err := aClient.executeQuery(*q, glueDbName, AthenaQueryResultS3Bucket)
if err != nil {
return errors.Wrap(err, "failed to execute query")
}
log.Printf("[INFO]: get query result: %s", *o.QueryExecutionId)
body, err := aClient.getQueryResult(*o.QueryExecutionId)
現時点では次の様な構成になっています。
Eventually Detection Engineeringへ
当初は意識していなかったのですが、ふと気づくとDetection Engineeringっぽくなっていました。 Detection Engineeringについては、Googleの「Autonomic Security Operation *1 」をきりくちとして、様々な解説がありますが、その中でもMercari社が「Detection Engineering and SOAR at Mercari by Mercari *3」定義するDetection Engineeringの機能を参照しましょう。
The core idea of detection engineering is to approach threat detection in the same way we approach developing software. This means writing detection rules and processes in a programming language, adopting test-driven development, utilizing a version control system, peer-review of changes, and automation of deployments using a CI/CD workflow.
一方、昨今のDetection Engineeringはリスク・脅威ベースでの趣が強い気がします。 個人的にはそれでは不十分と思っておりまして、こちらのエントリ*4であるように「リスクベースが発散しないためにまずベースライン」も必要なはずです。リスクベースとベースラインは相互に補完するはずで、片方しかないデータ基盤では、データ連携にまた追加のエネルギーが必要になってしまいます。AWS Security Lakeの機能をみても、おそらく、クラウド構成におけるmisconfigや、各種エンドポイントのOS・ミドルウェアの脆弱性情報も1つのデータレイクに入れ、相関的に分析していくことが重要なのではないでhそうか。そういったわけで、個人的にはDetection Engineeringの範囲に、ベースライン対応も入れていきたいと考えています。
最後に
といった具合の話を、Issue Huntさんのイベントではお話させてたいただきました。 スライドもまとめてあるのでご覧ください。
IssueHunt Lounge#6 LayerX社の事例から学ぶDetection Engineering | IssueHunt
とにかく、一区切りを迎えましたが、まだまだ改善ポイントがあります。ぱっと思いつくだけでもスキーマの更新方法だとか、LambdaのCICDパイプラインの改善などむしろ改善ポイントしかありません。そういったところの改善も一つ一つ書いていきたいと思いますので、今後ともご愛読お願いいたします。
当社のセキュリティ基盤や、コーポレートシステムならではのデータエンジニアリング等に興味ある方は、是非、ご連絡をお待ちしております。
- 応募: 【Fintech】DevOps / 株式会社LayerX
- 面談: デジタル証券と資産運用ビジネスを、一緒にDevとOpとSecしませんか?
- 雑談: https://x.com/ken5scal
*1:三井物産デジタル・アセットマネジメントに出向
*2:https://services.google.com/fh/files/misc/googlecloud_autonomicsecurityoperations_soc10x.pdf
*3:https://engineering.mercari.com/en/blog/entry/20220513-detection-engineering-and-soar-at-mercari/
*4:https://scrapbox.io/shinobe179-public/%E3%83%AA%E3%82%B9%E3%82%AF%E3%83%99%E3%83%BC%E3%82%B9%E3%81%8C%E7%99%BA%E6%95%A3%E3%81%97%E3%81%AA%E3%81%84%E3%81%9F%E3%82%81%E3%81%AB%E3%81%BE%E3%81%9A%E3%83%99%E3%83%BC%E3%82%B9%E3%83%A9%E3%82%A4%E3%83%B3%E3%81%8C%E5%BF%85%E8%A6%81