こんにちは!バクラク事業部 機械学習・データ部 データチームの@TrsNiumです。
弊社ではBigQueryとSnowflake上にデータ基盤を構築しています。データチームは、このデータ基盤上に集積したデータを集計し、データコンポーネント化して、分析や機械学習の用途に利用しやすい形で提供しています。この過程で、データの集計やデータコンポーネントの作成には、dbt(data build tool)を活用しています。
データの集計やデータコンポーネントの編集・作成は慎重に行う必要があります。集計方法の誤りは、業務ダッシュボードの数値ズレや機械学習モデルの推論精度低下につながる可能性があるためです。このリスクを回避するため、データに対するテストの実施が不可欠です。
しかし、弊社のデータ基盤における開発環境やステージング環境のデータ量は少なく、存在するデータもSaaS間で整合性が取れていません。そのため、dbtの変更を本番環境にデプロイしてから初めてテストの失敗に気づくという状況が頻発していました。この課題を解決するには、本番環境と同じデータを扱えるテスト環境を別途構築する必要がありました。
この課題解決のため、以前BigQueryで本番同様のデータを扱えるdbtテスト環境について紹介しました。
本番同様のデータを扱えるdbtテスト環境をBigQueryで構築する方法 #ベッテク月間 - LayerX エンジニアブログ
当記事では、Snowflakeでも同じように本番同様のデータを安全扱えるdbtテスト環境を構築する方法について紹介をします。
テスト環境について
以下の図は、GitHub Actionsを利用して本番環境とテスト環境のデータ管理を行う仕組みを示しています。Snwoflakeでは、本番のデータベースをクローンし、クローンしたデータベースのデータを用いてdbtテストを実施しています。
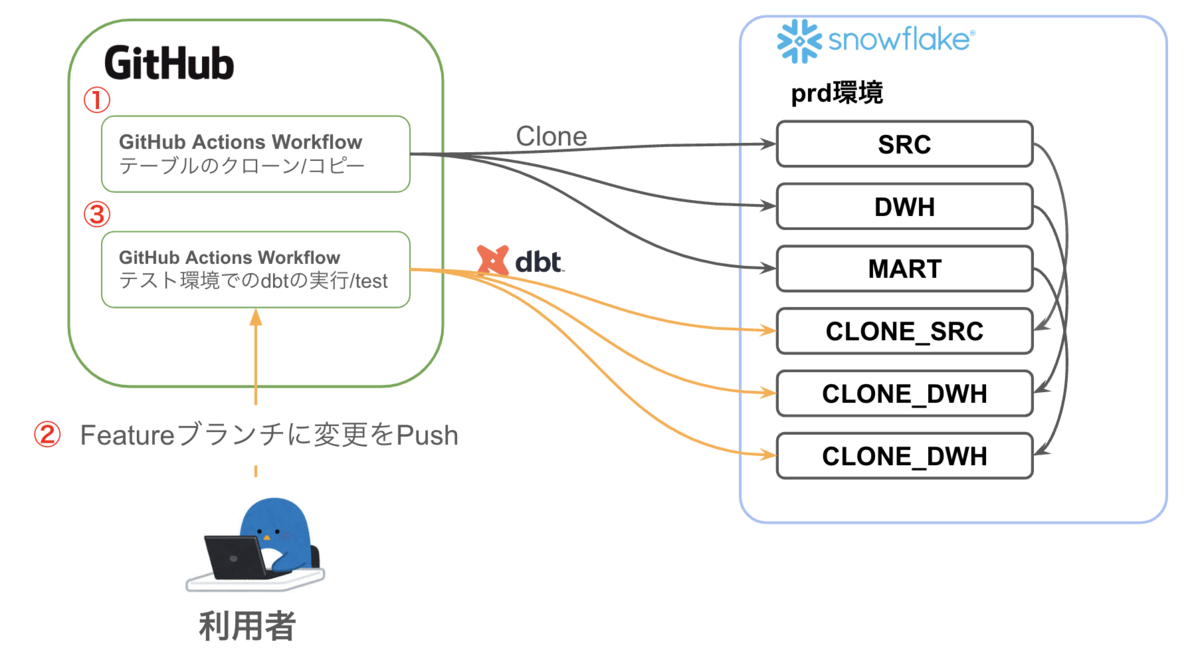
1. データのクローン/コピー: GitHub Actions Workflowを使用して、テスト環境のデータは毎日定期的に本番環境からクローンします (図の①)。
2. 利用者による変更のPush: 利用者は変更をGitHub上にPushします (図の②)。これにより、テスト環境でのdbtの実行やテストを行うGitHub Actions Workflowがトリガーされます。
3. GitHub Actions Workflow(テスト環境でのdbtの実行/test): Pushされた変更に基づいて、GitHub Actions Workflowがテスト環境でdbtの実行やテストを行います (図の③)。
アクセス制限
アクセス制限はデータベースレベルで行っています。クローンしたデータベースにアクセスできるユーザーはCI/CDで使用するdbt build用のユーザーとデータ基盤を管理する一部のユーザーのみとしています。他のユーザーはCIを通じて間接的に利用することが可能です。これにより、セキュリティとデータの一貫性を確保しています。
データのコピー戦略
テスト環境のデータは、本番環境のデータを定期的にクローンまたはコピーすることで維持しています。このプロセスはGitHub Actions上で毎日行われます。テスト環境ではデータの更新(update)は行わず、常に本番環境と同じデータを使用するようにしています。これにより、テスト環境でのテスト結果が本番環境でも再現性を持つことを保証しています。
dbtによるデータベースの切り替えについて
通常のデータベースに対してdbt buildを実行する場合と、クローンしたデータベースでdbtテストを実施する場合で、データベースを切り替える必要があります。この用途や環境に応じたデータベースの切り替えは、dbtマクロを使用して行います。dbt実行時に指定されたターゲットに基づいて、適切なデータベースに自動的に切り替わるよう設定しています。
1. dbt_project.ymlに用途・環境ごとの設定を変数として定義する
dbt_project.ymlに以下のようなvarsを定義します。このvarsは、環境ごとの変数を設定しています。各環境に対して、環境を示すenvと、dbtを実行するデータベースを決定するdatabaseというマップを定義しています。
vars: prd: env: prd database: src: src dwh: dwh mart: mart alert: alert prd-clone: env: prd database: src: clone_src dwh: clone_dwh mart: clone_mart alert: clone_alert
2. dbtマクロを使用し、ターゲットに基づいて用途・環境ごとの設定を読み込む
get_env_config dbtマクロを以下のように定義します。このマクロは、dbt実行時に指定されたターゲット名を基にvarsから値を読み取ります。ターゲット名から各環境(prdやprd-cloneなど)の名前を取得する処理は、get_env_namedbtマクロで行っています。
{#
This macro is used to get the variables for the current environment from vars.
If the dbt target is 'dev-via-sso', the vars are the same as "var('dev')".
The following mapping is used to determine the environment:
dev-via-sso -> dev
dev-via-user -> dev
stg-via-sso -> stg
stg-via-user -> stg
prd-via-sso -> prd
prd-via-user -> prd
Usage:
{{ get_env_config()['foo'] }}
#}
{% macro get_env_config() %}
{% set environment = get_env_name() %}
{% if environment in ['dev', 'stg', 'prd', 'dev-clone', 'stg-clone', 'prd-clone'] %}
{% set vars = var(environment) %}
{% else %}
{{ exceptions.raise_compiler_error("Unknown environment: " ~ environment) }}
{% endif %}
{{ return(vars) }}
{% endmacro %}
ターゲットから環境名を取得するget_env_name dbtマクロは次のようになっています。
{% macro get_env_name() %}
{% set target_name = target.name %}
{% if target_name in ['dev-via-sso', 'dev-via-keypair'] %}
{% set environment = 'dev' %}
{% elif target_name in ['prd-via-sso', 'prd-via-keypair'] %}
{% set environment = 'prd' %}
{% elif target_name in ['stg-via-sso', 'stg-via-keypair'] %}
{% set environment = 'stg' %}
{% elif target_name in ['dev-clone-via-keypair'] %}
{% set environment = 'dev-clone' %}
{% elif target_name in ['stg-clone-via-keypair'] %}
{% set environment = 'stg-clone' %}
{% elif target_name in ['prd-clone-via-keypair'] %}
{% set environment = 'prd-clone' %}
{% else %}
{{ exceptions.raise_compiler_error("Unknown target name: " ~ target_name) }}
{% endif %}
{{ return(environment | trim) }}
{% endmacro %}
3. SQL内でdbtマクロを呼び出し、configマクロにデータベースを指定する
SQLから get_env_config dbtマクロを呼び出し、dbtを実行するデータベースを取得します。取得したデータベース名をconfigに設定し、データベースを実行環境毎に切り替えます。
{% set env_config = get_env_config() %}
{% set database = env_config['database']['dwh'] %}
{{
config(
enabled=true,
full_refresh=false,
owner="data-platform",
materialized="view",
database=database,
schema="example",
alias="test",
persist_docs={"relation": true, "columns": true},
labels={'modeled': 'dbt', 'contains_pii': 'false', 'owner': 'data-platform'},
tags=['daily'],
)
}}
select
...
このように、dbtマクロをSQL内で呼び出すことで、実行環境ごとにdbtの対象データベースを動的に切り替えています。
データのクローンについて
GitHub Actions上でのデータクローンプロセスでは、SnowflakeのCREATE TABLE … CLONEステートメントを活用しています。このステートメントの実行には、Snowflakeのコマンドラインインターフェース(CLI)ツール「snow」を使用しています。これにより、データクローン処理をスクリプト化し、自動化することが可能になります。以下に示すシェルスクリプトは、GitHub Actions上で実行される具体的なクローン処理の一部です。このスクリプトは、データベース全体を効率的にクローンし、テスト環境に本番と同等のデータセットを準備します。
echo "Checking snowsql connection..."
rye run snow sql --temporary-connection --query "select 1"
echo "Generating create clone sql..."
# NOTE: ${{ github.workspace }}/databases.txtにclone対象のするデータベースが列挙されている
cat <<EOT | tee ${{ github.workspace }}/databases.txt
${{ inputs.databases }}
EOT
for db in $(cat ${{ github.workspace }}/databases.txt); do
# 'snow sql --format json' は、クエリが失敗してもエラーメッセージを返しません。そのため、まずクエリを実行し、その後で終了コードを確認します。
rye run snow sql --temporary-connection --query "select * from $db.information_schema.tables limit 0"
# https://docs.snowflake.com/en/sql-reference/info-schema/tables#columns
# 有効な値は、BASE TABLE、TEMPORARY TABLE、EXTERNAL TABLE、EVENT TABLE、VIEW、または MATERIALIZED VIEW です。
rye run snow sql --temporary-connection --format json --query "select * from $db.information_schema.tables where table_type = 'BASE TABLE'" \
| tee ${{ github.workspace }}/$db.json
cat ${{ github.workspace }}/$db.json \
| jq -r '.[] | "CREATE SCHEMA IF NOT EXISTS CLONE_" + .TABLE_CATALOG + "." + .TABLE_SCHEMA + " WITH MANAGED ACCESS;"' \
| tee -a ${{ github.workspace }}/create_schemas.sql
cat ${{ github.workspace }}/$db.json \
| jq -r '.[] | "CREATE OR REPLACE TABLE CLONE_" + .TABLE_CATALOG + "." + .TABLE_SCHEMA + "." + .TABLE_NAME + " CLONE " + .TABLE_CATALOG + "." + .TABLE_SCHEMA + "." + .TABLE_NAME + ";"' \
| tee -a ${{ github.workspace }}/create_clones.sql
done
echo "Executing create clone sql..."
rye run snow sql --temporary-connection --filename ${{ github.workspace }}/create_schemas.sql
rye run snow sql --temporary-connection --filename ${{ github.workspace }}/create_clones.sql
スクリプトの処理の流れは以下の通りです:
1. 接続確認:snow sqlコマンドを使用してSnowflakeへの接続を確認します。簡単なクエリ(select 1)を実行し、接続が確立されているか検証します。
2. データベースリストの作成:クローンを作成する対象のデータベースをリスト化し、このリストを基に後続の処理を進めます。
3. クローンSQLの生成:データベース内のテーブル構造を確認し、各テーブルのクローンを作成するSQLを自動生成します。情報スキーマ(information_schema)からテーブル情報を取得し、「CREATE OR REPLACE TABLE ... CLONE ...」形式のSQLを生成します。また、スキーマが存在しない場合は「CREATE SCHEMA IF NOT EXISTS … WITH MANAGED ACCESS」文も生成します。
4. クローンSQLの実行:生成されたクローン作成用SQLをSnowflakeに対して実行し、クローンを作成します。これにより、テスト環境に本番データと同等のデータを準備できます。
クローンの注意点
Snowflakeでテーブルクローンを作成する場合、クローン元のテーブルとストレージを共有するため、追加コストは発生しません。ただし、クローンしたテーブルに変更を加えると、その変更分は別のストレージに保存され、課金対象となります。そのため、クローンしたテーブルに頻繁に多くの変更を加える場合、ストレージコストが予想以上に高くなる可能性があります。
詳細はSnowflakeドキュメントを参照してください。
まとめ
本記事では、Snowflake上での本番同様のデータを扱えるdbtテスト環境の構築方法について詳細に解説しました。この環境により、本番データと同等のデータセットを使用したテストが可能となり、より信頼性の高いデータ処理と分析が実現できます。また、dbtマクロを活用した動的な環境切り替えや、Snowflakeのクローン機能を利用したデータ複製プロセスなど、効率的かつ安全なテスト環境の構築手法を紹介しました。
これらの方法を適用することで、データチームの生産性向上とデータ品質の維持に大きく貢献することが期待できます。