こんにちは!LayerXバクラク事業部 OCRチーム ソフトウェアエンジニアの秋野(@akino_1027)です。 この記事では、バクラクシリーズの機能であるOCRのテスト基盤について紹介していきます。
※本記事は LayerX Tech Advent Calendar 2022 11日目の記事となります。
背景
バクラクでは手入力ゼロを目指すべく、 OCR機能(文書の読み取り機能)を提供しています。
以下、OCRで書類が読み取られる様子
OCR機能は「手入力不要」という価値に直結するため、OCR精度を常に高い水準で保っておく必要があります。 安心してコード変更を取り込めるように
- 今まで読み取れてたのに読み取れなくなった書類はないか
- 新たに読み取れるようになった書類はどれか
を確認する仕組みが必要でした。
OCRテスト基盤の開発
そこでOCR精度を担保するためにテスト基盤の開発を行いました。
【やりたいこと】
- ファイル情報をinputにして、コード変更をトリガーにテストを実行
- 実行結果をGithubのPull Requestで確認できるようにする
【制約】
- テスト対象のファイルは大量にある(数十万件程度)
- ファイルはS3に保存されている
それでは実際の設計・実装した順に、考えていたことも含めて紹介していきます。 コードの詳細や細かい設定は解説に含めず、全体のアーキテクチャの紹介と課題の解決アプローチをメインにお伝えしていきます。
Github Actionsでシュッと実装できるのでは?

他のテストでもGithub Actionsが使われているため、OCRテスト基盤も同じようにシュッと実装しようとしました。 しかし、問題点がいくつか浮き彫りに。
問題点
- (1)Github Actionsのサーバーに数十万件のファイルをS3からGETさせるのは厳しい
- (2)Github Actionsに対してS3 GETの権限与えたくない
- (3)できればAWSリソース内で完結させたかった
顧客が実際にアップロードしたファイルの一部を利用しているため、Github Actionsサーバー内でファイルを扱いたくありませんでした。
ほとんどの場合、コードだけでテストが完結するのでGithub Actionsだけで要件は満たせると思います。 しかし今回の場合はファイルをInputとして扱うため、別の方法を検討することに。
実行環境をCodeBuildにしてみた

AWSが提供しているaws-codebuild-run-buildを使用することで、Github ActionsからサクッとCodeBuildを実行することができました。
しかし後述するEFSの影響でCodeBuildをプライベートサブネットにおく必要がありました。そのためNAT ゲートウェイを介してインターネットに接続されるために費用が少し高めになってしまいました。
Github ActionsでDockerビルド→CodeBuildを実行
先述したaws-codebuild-run-buildを使うことで、コードをよしなにCodeBuildの実行環境に持っていってくれるのですが、それだと料金が高くなってしまいました。 そこでDockerイメージを経由させることに。流れとしては下記の通りです。
- Github ActionsでコードをDockerビルド
- DockerイメージをECRにプッシュ
- Github ActionsからAWS CLIでCodeBuildを実行
さらに、大量のファイルを捌くためにS3からGETしてくる時間を短縮する必要もありました。
EFSの導入

EFSを簡単に解説すると
- AWSが提供しているファイルシステムストレージサービス
- Fargate, EC2, CodeBuild等にマウント可能

S3よりも高速に処理することが期待できるので、導入しました。
さて、最終的なテストの流れは以下のようになりました。
- Githubがコードの変更を検知
- Github Actions内でDockerビルドしてCodeBuildをキック
- CodeBuild内で先ほどビルドしたDockerイメージを使ってテストを実行
- 実行結果をGithub APIを使用して、該当Pull Requestのコメントに出力
しかし、まだ問題が残っていました
実行時間が長い...
テストケースが大量にあり、実行時間が長くなってしまいました。 変更を加えたらテストが終わるまでかなり待たなければいけなかったので、とても非効率に。
そこで、アプリケーション内でテストを並列実行させて1/10程度に実行時間を削減しました。 ここら辺は大変頼りになる同僚のmiwaさん(@coco_tyw)が実装してくださりました!感謝🙏
完成...?
これにてコードを変更するとテストが実行され、迅速に結果がPull Requestで確認できるようになりました。 流れをまとめると下記のようになります。
- GithubのPRにコミット
- Github ActionsでコードをDockerビルド、ECRにプッシュ、CodeBuildをキック
- CodeBuild内でECRからDockerイメージをプル、テストを実行
- テストを実行するアプリ内で並列処理して高速化
- ファイルはS3からではなく、EFSからGETする
- テスト結果を該当のPRのコメントに出力
PRのコメントでテスト結果が出力されている様子
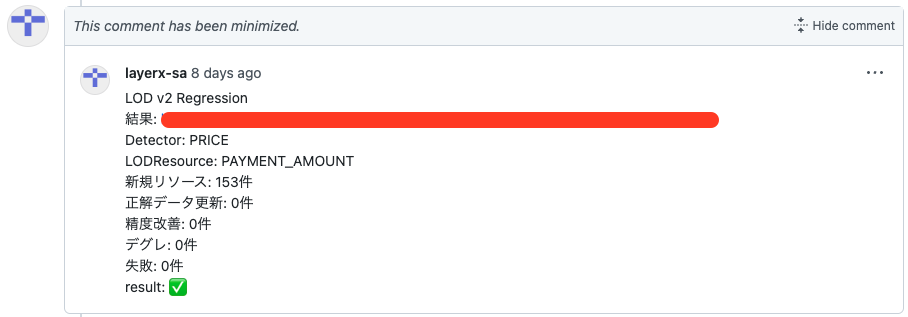
これで安心してコード変更をガンガン取り込むことが可能に!
しかし、歴史的背景からCodeBuild内のDockerでテストを実行していますが、少し気持ちが悪いのでFargateに移行したいと考えています。
最後に
他にもOCR精度周りだけでなく、データ基盤やパイプラインやモニタリングなどの分野でもまだまだ課題だらけです。 少しでも興味がある方は下記のリンクからご応募お持ちしております!