
こんにちは!LayerX エンジニアの高際 @shun_tak と申します!
この記事ではLayerX インボイスを支える請求書AI-OCR (Optical Character Recognition; 画像からの文字認識) について、
- 開発における品質の考え方
- 開発の方針
- 請求書AI-OCRを構成する処理群
といった構成でお伝えしていきたいと思います。これ以外のトピックや、さらに深掘りした話も本ブログにて引き続き投稿していきます。
開発における品質の考え方
LayerX インボイスでは請求書AI-OCRの品質が顧客満足度に直結すると認識しており、その品質向上に注力しています。そのため、具体的な構成のお話をする前に、品質について簡単に述べておこうと思います。
品質の要素としてはいろいろありますが、請求書AI-OCRとしては以下に注目しています。
- 読み取り項目数
- 精度
- 応答速度
- スケーラビリティ
- 可用性
- コスト
それぞれ簡単に説明します。 「読み取り項目数」は支払期日や支払金額、取引先の情報(会社名や口座情報)など、請求書記載の情報をどれだけ読み取れるかという指標です。
「精度」は言葉のままで、実際の値とOCRで読み取った値を比較してどれだけ正解できたかの割合です。とはいえプロダクション環境ではお客さまのビジネス上の理由で実際の請求書の値から変更されることも多く、精度のモニタリングは簡単ではありません。
「応答速度」は、請求書1枚がアップロードされてから画面に表示されるまでにかかる時間のことです。スケーラビリティとも関連しますが、並列で複数枚アップロードされても性能が劣化しないように開発を進めています。
「スケーラビリティ」は同時に何枚の請求書を処理できるか表しています。
「可用性」は請求書AI-OCRのサービスが壊れず正常に動くことを表します。
最後に「コスト」。これはほとんどインフラコストと等価です。コストが高くなるとサービス価格やプロダクト開発への投資に影響することになるため、重要な要素の一つとして注意しています。
このように一言で品質と言っても様々な要素がありますが、次節ではこれらの品質を維持し高めていくための開発方針を説明します。
開発の方針
LayerX インボイスの請求書AI-OCR開発では以下を基本方針としています。
- SaaSやAWSマネージドサービスをフル活用
- 様々な観点での精度モニタリングを実施
- オペレーションを改善し続ける
これは、以前福島がnoteにてデジタルネイティブな会社の文化について執筆した内容に基づいています。

ノンコアは巨人の肩に乗り、SaaSやAWSマネージドサービスをフル活用することで、コアである顧客の利益に直結するような改善に集中することができます。また、スケーラビリティや可用性、コスト最適化といった課題もAWSのベストプラクティスにのっとることで様々な恩恵を受けることができます。
また、LayerX インボイスでの会計ソフト対応やワークフロー機能等ではユーザストーリーに基づき優先順位を決めることができますが、請求書AI-OCRでは読み取り精度の改善が主なミッションになります。
読み取り精度という結果は様々な要因によってもたらされるものですが、その要因の分析が大雑把だと、開発者それぞれに属人化した知識や経験といった勘に頼った改善になってしまいます。様々な観点での精度モニタリングを実施し、どこがボトルネックかを可視化することで、勘ではなく事実に基づく正しいアクションを実行し、効率よく精度の改善をしていくことができます。
また、請求書AI-OCRの開発には、精度改善のための学習データ作成をはじめとした様々なオペレーションがあります。そういったオペレーションを改善し続けることで、品質改善のサイクルを高速化していきます。データ量やデータ自体の品質が物を言う世界なので、データを増やし、精度を改善するためのオペレーションを大切にしています。
チームによって方針は様々だと思いますが、わたしたちの場合はこのように開発生産性を高め、勘ではなく事実に基づき、同時にオペレーションも磨きながら日々品質向上に努めています。
それではいよいよ次節から請求書AI-OCRの仕組みについて解説していきます。
請求書AI-OCRを構成する処理群
LayerX インボイスの請求書AI-OCRは、以下の図のように複数の処理で構成されています。
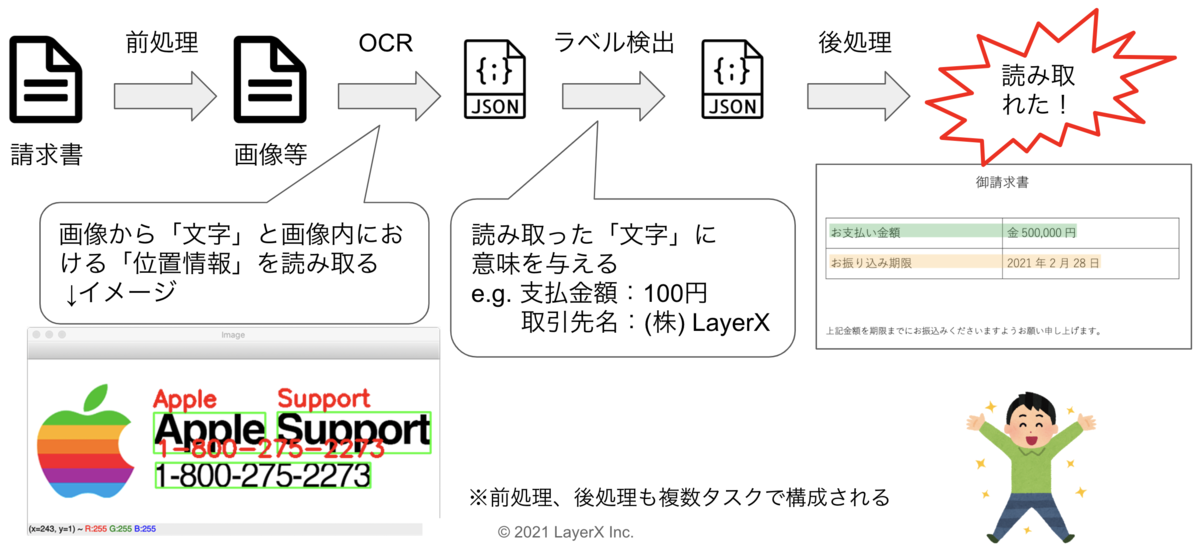
LayerX インボイスが請求書を受け取ると、まずはいくつかの前処理を行います。リサイズやノイズ除去、ファイル変換といった処理を行います。
前処理が一通り完了すると、いわゆる汎用のOCRが実行されます。これは例えば画像を入力すると、その中に含まれる「文字」と画像内における「位置情報」を返すといった処理です。以下のような画像をイメージしていただければわかりやすいと思います。

この処理で得た結果は「意味」を持たず、ただの文字列に過ぎません。LayerX インボイスで入力補助として利用するにはもう一つ処理が必要になります。それがわたしたちがラベル検出と呼んでいる処理です。ラベル検出を実行することで、読み取った「文字」に意味を与えることができます。
この他にもいくつかの後処理を行い、一連の処理が完了します。
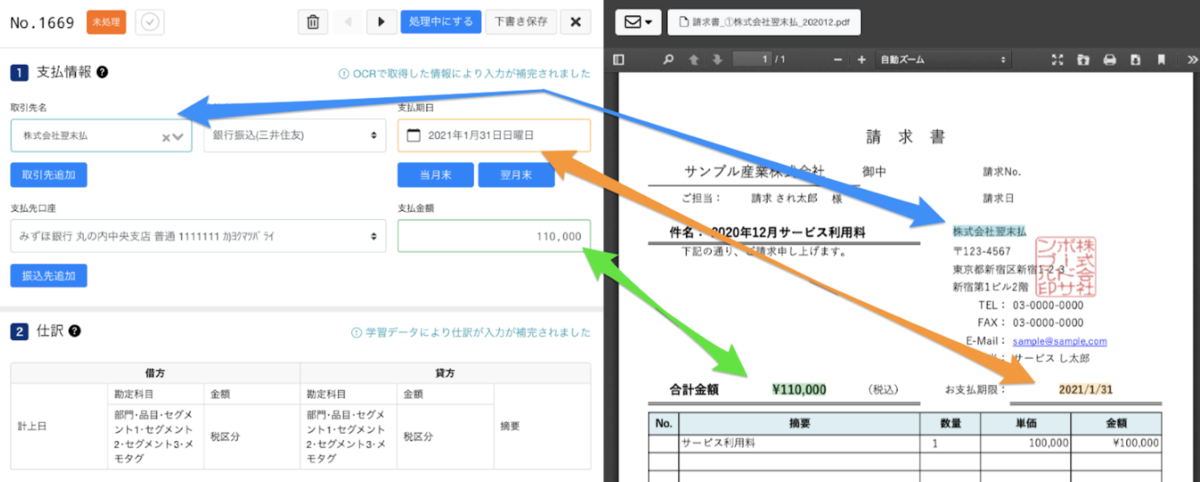
最後まで処理が完了すると、以下の図のようにユーザーの画面に読み取った結果が表示されます。
■ 処理を複数に分ける理由
このように、LayerX インボイスの請求書AI-OCRは複数の処理で構成されています。請求書を入力するとラベル検出まで一気通貫で処理する、いわゆるEnd-to−Endのモデルを作ることも可能ですし、いくつか論文も出ていますが、わたしたちは処理を分けることにしました。
処理を分けるメリットとしては
- 柔軟に処理を組み替えやすい
- 処理ごとに改善しやすい
- エラー時にどこで何が起こってるか分析しやすい
といったものがあります。逆にデメリットとしては
- デプロイするものが多くなる
- 多数の処理をモニタリングする必要がある
- 処理ごとに異なる技術を要求される
- 処理間のオーバーヘッドで全体の応答速度が遅くなる
- 壊れる箇所が増える
- リトライしても冪等にする必要がある
といったものがあり、はじめに述べたようなといった品質の注力要素全てを高めていくには工夫が必要です。そういった工夫や実装の詳細については、本ブログにて定期的に発信していこうと思います。
また、請求書AI-OCR機能の配信だけでなく、学習フェーズでもたくさんの工夫をしているので、そのあたりも今後書いていけたらなと思っています。
追記:非同期処理について執筆しました
まとめ
というわけで、この記事ではLayerX インボイス請求書AI-OCR開発における品質の考え方、開発方針、請求書AI-OCRを構成する処理群について紹介しました。
請求書AI-OCRというと、今までのLayerXとだいぶ違うものを作ってる感じがするかもしれません。しかし、コア・ノンコアの考え方や、データを集め勘ではなく事実に基づいてアクションするというところは、行動指針に「Fact Base」を掲げるLayerXらしさが出ているんじゃないかと感じています。
まだまだ作りたい新機能もたくさんあり、機能や精度の改善、オペレーション改善、インフラの改善などやりたいことが山積しています。採用もオープンになっていますので、少しでも興味ありましたら、一度話を聞きに来てください!