こんにちは!バクラク事業部 Platform Engineering部 SREグループの taddy(id:sadayoshi_tada)です。
みなさんはデータベースサーバのログの分析が必要になった時どのように対処されていますか?バクラクではAmazon Aurora MySQL互換(以降Auroraと呼称します)を使用していて、Aurora内部に保持しているログを収集し、分析する基盤を運用しているためこの記事でその紹介をします。
Aurora内部に保持しているログの出力
Aurora内部に保持しているログを別の場所に出力する方法として、CloudWatch Logsへの出力があります。以下のスクリーンショットのように指定したログをCloudWatch Logsに出力・閲覧できるようになります。例えば、このスクリーンショットだとError logをCloudWatch Logsに出力する設定になります。

Audit logなどを含む様々なログを出力したい要件がありCloudWatch Logsに出力していたのですが、CloudWatch Logsへログを出力する時にかかるコストが嵩んでいたことがあり( DataProcessing-Bytesという項目がCloudWatchのコストの約8割を占めていました)、CloudWatch Logsへの出力ではなく、AuroraからログをダウンロードしてAmazon S3(以降S3と呼称します)へ出力することにしました。
Auroraのログダウンロードのための手段検討
Auroraのログダウンロードをする方法としてDownloadDBLogFilePortion APIやDownloadCompleteLogFile APIを比較してみることにしました。
DownloadDBLogFilePortion APIを検証でダウンロードしてみたところ、ログメッセージが大きくなってしまった時に途中で切れてしまってログの欠損がありました。DownloadDBLogFilePortion APIは最大10,000行までのログメッセージの取得ができ、Markerを使って取得が切れているメッセージを取得可能かと思ったのですが、ログのサイズが肥大化した時の対応が難しくなると感じました。DownloadCompleteLogFile APIを試してみたところ、こちらはログの欠損が少なくログ収集ができたため、このAPIを使用してログダウンロードを行うことにしました。
AuroraのログダウンロードとS3アップロードの概要
以下はPythonでAuroraのログをダウンロードするサンプルコードになります。SigV4署名でのGETリクエストをダウンロードしたいDB インスタンスのログごとに実行します。また、デフォルトだとログファイル名を1000件までしか取得できないため、ページネーションで全件取得するようにしています。ログダウンロード後にtempfile に書き出して、このファイルをgzファイルにしてS3にアップロードすることにしました。
import boto3 from botocore.awsrequest import AWSRequest import botocore.auth as auth import requests import tempfile region = 'Auroraがあるリージョン名' session = boto3.session.Session() rds_endpoint = 'rds.' + region + '.amazonaws.com' rds = boto3.client('rds') parser = argparse.ArgumentParser() parser.add_argument('aurora_cluster_name', type=str) args = parser.parse_args() aurora_cluster_name = args.aurora_cluster_name def get_db_instance_identifiers(aurora_cluster_name: str) -> list[str]: target_db_instance_identifiers = [] response = rds.describe_db_clusters(DBClusterIdentifier=aurora_cluster_name) members = response['DBClusters'][0]['DBClusterMembers'] for member in members: target_db_instance_identifiers.append(member['DBInstanceIdentifier']) return target_db_instance_identifiers def get_log_file_names_from_aurora(db_instance_identifier: str) -> list[str]: download_log_files = [] describe_db_log_files_pagenator = rds.get_paginator('describe_db_log_files') describe_db_log_files_page_iterator = describe_db_log_files_pagenator.paginate(DBInstanceIdentifier = db_instance_identifier) for describe_db_log_files_page in describe_db_log_files_page_iterator: for describe_db_log_file in describe_db_log_files_page['DescribeDBLogFiles']: download_log_files.append(describe_db_log_file['LogFileName']) def download_rds_logfile(db_instance_identifier:str, log_file_name:str, region:str, rds_endpoint:str) -> str: download_complete_logfile_url = 'https://' + rds_endpoint + '/v13/downloadCompleteLogFile/' + db_instance_identifier + '/' + log_file_name credential = session.get_credentials() awsreq = AWSRequest(method = 'GET', url = download_complete_logfile_url) sigv4auth = auth.SigV4Auth(credentials, 'rds', region) sigv4auth.add_auth(awsreq) res = requests.get(download_complete_logfile_url, stream=True, headers={ 'Authorization': awsreq.headers['Authorization'], 'X-Amz-Date': awsreq.context['timestamp'], 'X-Amz-Security-Token': credential.token }) log_file_content = res.text res.close return log_file_content def main(): db_instance_identifiers = get_db_instance_identifiers(aurora_cluster_name) for db_instance_identifier in db_instance_identifiers: log_file_names = get_log_file_names_from_aurora(db_instance_identifier) for log_file_name in log_file_names: with download_rds_logfile(db_instance_identifier, log_file_name, region, rds_endpoint) as log_file_content: with tempfile.NamedTemporaryFile(dir=".",mode='w') as fp: fp.write(log_file_content) fp.seek(0) if __name__ == '__main__': main()
実行基盤の選定
AuroraのログのダウンロードとS3アップロードをどこで実行させるかを検討した際に、定期的にログをS3にアップロードするワンショットタスクの実行基盤としてAWS LambdaかAmazon ECS(以降ECSと呼称します)などのサーバーレス環境を候補としました。ログダウンロードとS3へのアップロードにかかる時間を計測したところ、実行時間が15分以上かかってしまいました。AWS Lambdaの実行時間は最大が15分なため、実行基盤としてECSを採用することにしました。
運用イメージとしては以下の構成図のとおりです。EventBridge SchedulerからECSタスクを実行し、Auroraからログをダウンロードとログ格納用バケットにアップロードします。S3にアップロードしたファイルは時間の経過と合わせてストレージクラスを変更し、コスト最適化を図っています。

S3に格納したログの分析
ここからはS3に格納したAuroraのログを調査で分析するケースについて触れます。この用途にはAmazon Athena(以降Athenaと呼称します)を使用しています。
S3に保管しているログのパス概観
Auroraのログはこの記事ではS3に s3://バケット名/Auroraクラスター名/各インスタンス名/YYYY-MM-DD/各種ログ名/ログファイル のパスで入っていることとします。tree形式で表すと、以下のようなパスイメージです。
ログ格納用バケット
└── Auroraクラスター名
└── Auroraインスタンス名
└── YYYY-MM-DD
└── audit
└── auditlog.gz
Audit logの分析例
例えば、以下は監査ログを検索するテーブル作成例となります。監査ログはドキュメントにも記載がありますが、UTF-8 形式のカンマ区切り変数 (CSV) ファイルになっており、フィールドもドキュメントに沿って定義します。 また、AthenaのテーブルではAuroraクラスター名、インスタンス名、ログの種類、日付をパーティションに使用してクエリパフォーマンスを向上させるようにしています。
CREATE EXTERNAL TABLE `テーブル名` ( `timestamp` string, `serverhost` string, `username` string, `host` string, `connectionid` string, `queryid` string, `operation` string, `database` string, `object` string, `retcode` string ) PARTITIONED BY (`db_cluster_identifier` string, `db_identifier` string, `day` string, `log_type` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( 'escapeChar' = '\\', 'quoteChar' = '`', 'separatorChar' = ',' ) LOCATION 's3://[ログの格納先バケット]/' TBLPROPERTIES ( 'projection.enabled' = 'true', 'projection.db_cluster_identifier.type'='injected', 'projection.db_instance_identifier.type'='injected', 'projection.log_type.type'='injected', 'projection.date_day.format' = 'yyyy-MM-dd', 'projection.date_day.range' = '2020-01-01,NOW', 'projection.date_day.type' = 'date', 'storage.location.template' = 's3://バケット名/${db_cluster_identifier}/${db_identifier}/${day}/${lod_type}/' );
作成したテーブルに対して管理者ユーザーの操作ログを以下のクエリで検索したとします。
SELECT serverhost, database, object FROM [テーブル名] where db_cluster_identifier = [Auroraクラスター名] and db_identifier = [WRITERインスタンス名] and username = [管理者ユーザー名] and log_type = 'audit' and day = [スキャンの日付]
検索した結果、スクリーンショットのように操作履歴を抽出することができました。必要に応じて過去に遡って特定日の操作ログを追うことができます。

SOC1監査での利用
先日のCloudNative Days Summer 2025にて弊社の星が発表した資料でも触れられていますが、SOC1の監査でもこの分析基盤は使用しています。 P24のスライドに記載のようにAuroraのログの一部をAthenaで集計し、証跡として提出しています。Athenaで提出するログをクエリ保存しておくことで、円滑な監査対応を行うことができています。
まとめ
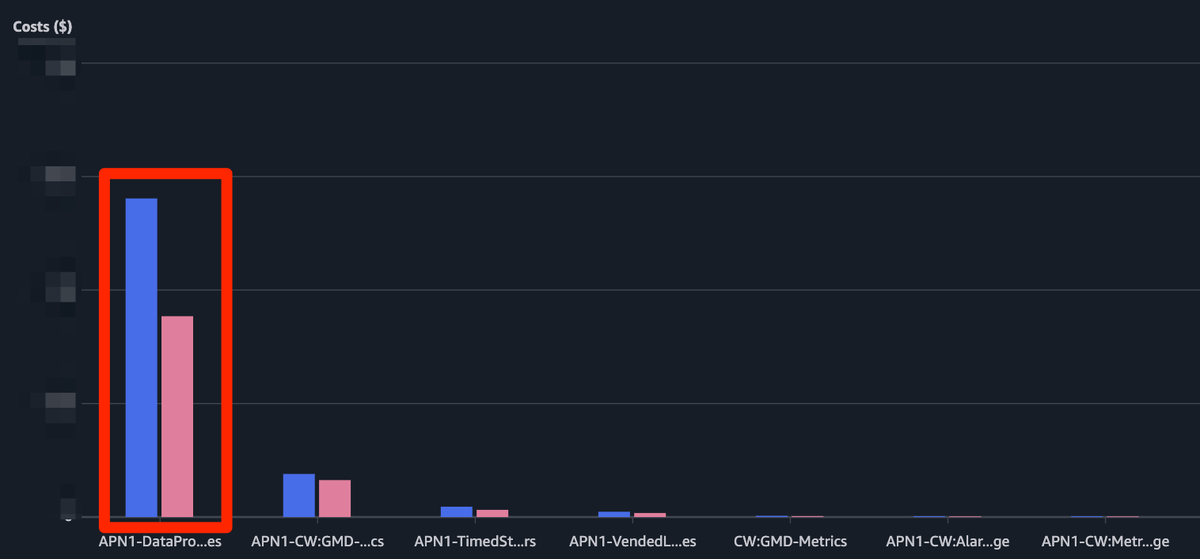
Auroraに保持している各種ログをDownloadCompleteLogFile APIを使ってS3にアップロードし、Athenaで分析するようにした運用事例を紹介しました。また、この運用にしたことでのコスト効果も簡単にまとめます。スクリーンショットの赤枠部分がDataProcessing-Bytesのコスト削減幅のグラフを示しており、青の棒グラフがCloudWatch Logsに出力していた期間のコストで、赤の棒グラフがCloudWatch Logs出力を停止して以降のコストになり、約37%ほどコストダウンができたのでコスト削減にも寄与できました。
終わりに
人々の「働くをラクに。ラクをもっと創造的に。」を目指したプロダクトの信頼性を共に高めていく仲間をSREグループでは募集しています。
まずは話だけでも、という方は是非カジュアル面談や、LayerX Casual Nightといったイベントにぜひ応募ください。