
こちらは LayerX AI Agentブログリレー 4日目の記事です。
3日目の記事はomori(@onsd_)さんによる 安定したAIエージェント開発・運用を実現するLangfuse活用方法 でした。実際に本番稼働しているサービスのLLMOps事例は本当に貴重で大変勉強になりました。
こんにちは、全ての経済活動をデジタル化したいTomoaki(@tapioca_pudd)です。
この大生成AI時代に生きていれば、3度のメシよりRAGが欲しくなることはよくあると思いますが、皆さんはどのように構築していますか?
弊社においても、カスタマーサポートや営業の生産性向上が重要な課題であり、サポートサイトやプロダクト仕様をデータソースとするRAG(Retrieval-Augmented Generation)を構築し、お客様からのお問い合わせに対して回答案を自動で生成するエージェントの開発などを進めております。こうした背景から、RAGの重要性はますます高まっています。
イントロ
AWS社が提供するAmazon Bedrock Knowledge Bases (以降Knowledge Basesと呼ぶ)はRetrieval Augmented Generation (RAG)を簡単に実現するためのマネージドサービスです。
Knowledge Basesはデータの前処理、データベースの構築、データの取得までエンドツーエンドでサポートしており、自然言語のクエリの構造化データ用のクエリに変換、RAGの取得結果の自然言語による要約生成など、RAGのワークフローをフルマネージドサポートしてくれます。
特に個人的に魅力的に感じているのは、ベクトルストアを簡単に構築できる点で、Amazon S3で管理している非構造化データからsyncコマンド1つ実行するだけでベクトルストアを構築してくれます。 ベクトルストアはこれまではOpenSearchが主流だったのかと思いますが、最近はS3 Vectorsがpreviewとして登場したことによりコスト的にも非常にリーズナブルにRAGが構築可能になり、非常に期待が高まりますね。
ちなみに余談ですが、S3 Vectors からOpenSearch Serverlessコレクションへのワンクリックエクスポートもサポートされており、より高速なクエリパフォーマンスが必要な場合は状況に応じてOpenSearchを利用可能です。頻繁にクエリされないベクトルを S3 Vectors に保持し、高度な検索機能を必要とするようなレイテンシの制約が最も高い操作には OpenSearch を使用することで、ベクトルワークロードを分散させ、コスト、レイテンシー、精度を最適化できます。 aws.amazon.com
今回のブログではKnowledge BasesでRAGを構築する際のTipsをご紹介します。
検索の限界
RAGに限らず検索全般に言えるかと思いますが、どんなに性能のいいモデルやアルゴリズムを利用したとしても検索結果が"絶対"正しいということはありません。 そして、生成AIがRAGによる検索結果を利用した回答を生成する場合、仮に誤った情報源を取得したとしてもその誤った情報を元にあたかも正しいように回答してしまうことはよくあります。
ある程度精通した領域の内容であれば、その内容が間違っているかどうかわかるかもしれないですが、基本的に生成AIに問い合わせている時点で精通してない可能性の方が高く、生成AIの回答が誤っているかどうかを区別するのは至難の業です。
このように、RAGの性能は完璧ではないので、構築する上で大事なのは回答を生成するために利用した情報源をエンドユーザーが検証可能であることだと思います。
例えば、バクラクというサービスのサポートサイトのページをデータソースとしたRAGを作り、プロダクトに関する質問に何でも回答してくれるチャットボットを作成するとします。 生成した回答と一緒に回答の生成に利用されたサポートサイトの具体的なページのURLもセットで回答してあげることで、ユーザーは実際に生成内容を検証したり、より詳細な情報を調べにいくことが容易にできます。 逆にリンクがないと、生成AIの回答を信じるしかないですが、生成AIの回答精度は100%にはならないという性質上あまりよろしくありません。
では、Knowledge BasesでRAGを構築する場合、この"元のリンクとセット"で検索結果が取得できるRAGはどのようにしたら構築できるでしょうか?
Knowledge Basesのレスポンス
Knowledge BasesでRetriveを実行したときのレスポンスは以下のようになります。
HTTP/1.1 200 Content-type: application/json { "guardrailAction": "string", "nextToken": "string", "retrievalResults": [ { "content": { "byteContent": "string", "row": [ { "columnName": "string", "columnValue": "string", "type": "string" } ], "text": "string", "type": "string" }, "location": { "confluenceLocation": { "url": "string" }, "customDocumentLocation": { "id": "string" }, "kendraDocumentLocation": { "uri": "string" }, "s3Location": { "uri": "string" }, "salesforceLocation": { "url": "string" }, "sharePointLocation": { "url": "string" }, "sqlLocation": { "query": "string" }, "type": "string", "webLocation": { "url": "string" } }, "metadata": { "string" : JSON value }, "score": number } ] }
レスポンスの中にはlocationというフィールドがあり、例えばS3をデータソースとした場合、検索にヒットしたチャンクが具体的にS3のどのオブジェクト由来だったのかをs3Locationで教えてくれます。 s3Locationは開発者としては嬉しいですが、例えばチャットボットのエンドユーザーなどはAWS上のS3オブジェクトを見れるわけではないので、これだけでは"元のリンクとセット"で検索結果が取得できるRAGは作れなそうです。
ただ、S3にはメタデータを付与できる機能があるので、あらかじめS3オブジェクトのメタデータにリンクをセットしておけば、取得した結果のs3LocationからS3オブジェクトのメタデータのリンクを引っ張ってくることができそうです。
まぁ、悪くはないですが、毎回RAGの最後にS3のメタデータを取得するのは地味にめんどくさいですよね。。。
あぁ、Knowledge Basesに直接メタデータを付与できればいいのに。
Knowledge Basesのメタデータフィルタリング
なんと、Knowledge Basesにはメタデータを付与する機能があるじゃありませんか。
ブログでは、今回のような"元のリンクとセット"で検索結果が取得するという用途ではなく、フィルタリングによって検索性能を上げる手段として紹介されています。
Knowledge Basesでは各文書に対してカスタムメタデータファイル(最大 10KB まで)を指定でき、データ取得時にベクトルストアに対してメタデータに基づき事前にフィルタリングした上で、関連する文書を検索できる機能のようです。 この方法によって取得される文書を制御することができ、特にクエリの解釈が曖昧な場合に検索性能の向上に寄与するということです。
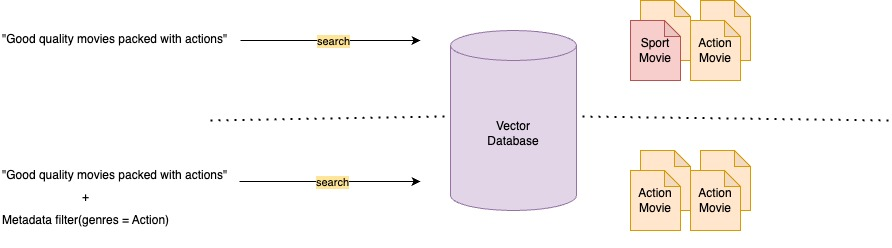
例えば、映画の検索において、「Good quality movies packed with actions」というクエリはアクション映画に加えてスポーツ映画もヒットしてしまいますが、アクション映画というメタデータでフィルタリングすれば検索の正確性が向上し、さらに検索対象となるチャンクの数を減らすこともできるのでパフォーマンスも向上します。
メタデータの付与は非常に簡単で、ソースデータファイルと同じ名前に .metadata.json のsuffixを付けたメタデータファイルを同じ階層に保存するだけで付与されます。メタデータは文字列、数値、bool値のいずれかで設定可能です。以下は、メタデータファイルの例です。
{ "metadataAttributes" : { "tag" : "project EVE", "year" : 2016, "team": "ninjas" } }
機能の趣旨としてはcontextにメタデータに関する情報を渡し、クエリ時にメタデータである程度フィルタリングしておけば、性能が上がるよというシンプルなものです。
メタデータに基づいてフィルターされるということは、ベクトルストアのチャンクに対して任意の情報をメタデータとして付与できるのではないでしょうか?
実際に試してみましょう。
URLをメタデータとして付与
ブログで紹介されているようにソースデータファイルと同じ名前に .metadata.json のsuffixを付けたメタデータファイルをつけられるということだったので今回は以下のスキーマでメタデータを付与してみます。
{ "metadataAttributes": { "original-url": "<ソースのURL>" } }
ちなみに試しに8個ほどメタデータを付与しようとしたところMetadata object must have at most 10 keysというエラーに遭遇しました。
ドキュメントには見当たらなかったですがクオータがあるようですね。
今回は8個しか設定してないのにエラーがでたので実際ユーザーが設定できる数が10個というわけではなく、このブログの最後のretrieve結果を見るとデフォルトでシステム側で勝手に生成されるメタデータが3つあったことから、おそらく実質10から3を引いた7個がユーザーが設定できるメタデータの最大数だと推察します。
今回はバクラクのお知らせにあるプレスリリースをいくつかピックアップしmarkdown形式でS3に保存してRAGを構築してみようと思います。メタデータには実際のプレスリリースのページのURLを指定します。

Knowledge Basesの構築方法は今回は割愛しますが、S3 Vectorsでベクトルデータベースを構築しました。
aws bedrock-agent-runtime retrieve \ --knowledge-base-id '<knowledge-base-id>' \ --retrieval-query '{"text": "バクラクではETCカードは発行できる?"}'
では実際にretrieveを実行してみます。サンプルデータにはETCカードに関するプレスリリースを入れたので、ETCカードが発行できるかを聞いてみます。
緊張の瞬間ですね。
{ "retrievalResults": [ { "content": { "text": "[](data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==)  バクラクがわかる3点セット 資料ダウンロード 無料 ](/contact/) [050-1790-5547(平日 10:00 - 18:00)](tel:050-1790-5547) [資料ダウンロード](https://bakuraku.jp/resources/product/resources-series-bakuraku/) [お問合せ](https://bakuraku.jp/contact/) 公開日:2025/09/04 「バクラクビジネスカード」が年会費無料・クレカ紐付け不要の独立型ETCカードをリリース。高速道路利用の統制強化と経費管理を効率化。 ================================================================= ![「バクラクビジネスカード」が年会費無料・クレカ紐付け不要の独立型ETCカードをリリース。高速道路利用の統制強化と経費管理を効率化。]", "type": "TEXT" }, "location": { "s3Location": { "uri": "s3://tmp-tomoaki-bakuraku-resources/bakuraku_jp_1757574469716.md" }, "type": "S3" }, "metadata": { "x-amz-bedrock-kb-source-uri": "s3://tmp-tomoaki-bakuraku-resources/bakuraku_jp_1757574469716.md", "original-url": "https://bakuraku.jp/news/20250903/", "x-amz-bedrock-kb-chunk-id": "cbfd48ff-cfdc-431e-b288-e59cdf3ea86b", "x-amz-bedrock-kb-data-source-id": "XXXXXXXXX" }, "score": 0.6693078260533764 }, { "content": {他の結果} }, { "content": {他の結果} }, ] }
見事ETCカードのリリースに関するプレスリリースと記事が検索のトップに来ました。そして、metadataフィールドを見ると
"original-url": "https://bakuraku.jp/news/20250903/",
元のリンクぽいのが取得できています!!! 実際にページを見てみましょう!
ちゃんとETCカードのリリースに関するプレスリリースの記事になっていました!
利用する“前後”の業務もラクになるバクラクビジネスカード、今ならキャッシュバックもしているし、ETCカードも対応しているしとても便利でおすすめです!
めでたし!!!
おわりに
LayerXでは圧倒的に使いやすいプロダクトを届け、利用者がワクワクするような体験作りを目指して日々開発しています。 最近はBet AIを掲げAIにフルベットして開発していますので少しでも興味が湧いた方はぜひカジュアル面談しましょう!