LayerX の提供するバクラクAIエージェントを題材に、Langfuse を利用したAIエージェント機能の性能評価の取り組みについて紹介します。今回は、性能評価の肝であるデータセット構築について紹介します。次回は、そのデータセットを用いて実際に性能評価を実施する仕組みについて紹介します。
バクラクは、バックオフィスに特化したAIエージェントによって、日常業務の中で自然にAIを活用いただけるような体験を提供しています。
こちらは LayerX AI Agent ブログリレー 17日目の記事です。前回は @ta1m1kam による 『CopilotKitでアプリをAI化しないか?』 でした。今回はバクラク事業部 機械学習エンジニアの松村(@yu__ya4)からお届けします。

はじめに
世はまさに大AIエージェント時代。多くの企業・個人がAIエージェントを活用した開発を進めており、私たちLayerXも例外ではありません。海外企業を中心に様々な実践的な知見も世の中に出始めており、日々学ぶことが多く大変で楽しいです。
一方で、AIエージェントプロダクトの性能評価に関する実践的な知見はまだ多くはないように思います。これはAIエージェント機能を運用フェーズにまで持っていけているケースがまだまだ少ないことや、AIエージェント機能の性能評価が難しく、単純に正解が見えていないことが多いなどといった要因によるものと想像します。
私たちとしてもまだまだ正解は見えておらずより良い方法を模索し続けているのですが、現時点で行なっていることの一部をご紹介できればと思います。
経費精算申請のAIレビュー
本記事の題材として、LayerXが先日リリースした「AI申請レビュー」というバクラクのAIエージェントプロダクトを扱います。
AI申請レビューは、企業ごとの社内規程や過去の差し戻しデータなどから生成した申請ルールに基づき、経費精算や稟議を入力時点でレビューし、正しい申請をガイドすることで、ルールに基づかない申請をなくします。
その結果、従来多くの時間を割いていた差し戻し・修正・再申請・再承認・催促などの「本来必要ではないノンコア業務」を大幅に削減。申請者・承認者・経理/労務担当者がコア業務にあてる時間を創出し、全社的な生産性向上を実現します。
今回は、簡易的なAIレビューを行う機能を例として用意しました。
システムの入出力は以下のような形式とします。指定されたレビューの対象(review_target)が、与えられた経費精算申請の内容(expense_application)の中に正しく含まれるかをAIに確認させます。AIはレビューの結果(result)をその理由(reason)とともに申請者にフィードバックします。
from pydantic import BaseModel, Field class ReviewInput(BaseModel): review_target: str = Field(description="レビューの対象") expense_application: str = Field(description="経費精算申請の内容") class ReviewResult(BaseModel): reason: str = Field(description="レビューの理由") result: bool = Field(description="レビューの結果")
AIによるレビューは以下の処理で実現します。LLMを一度叩くシンプルな構成です。実際のAI申請レビューは、このようなAIによる処理・toolが複数連なって機能します。
def base_review_expense_application(*, review_input: ReviewInput) -> ReviewResult: """経費精算申請の中に指定された内容が正しく含まれているかをAIがレビューする""" prompt = [ {"role": "system", "content": "あなたは経理のスペシャリストです。従業員からの経費精算申請を確認して、指定された内容が正しく含まれているかをレビューしてください。"}, {"role": "user", "content": f"指定された内容:{review_input.review_target}、経費精算申請:{review_input.expense_application}"}, ] response = openai_client.responses.parse( model="gpt-4.1-mini", input=prompt, text_format=ReviewResult, ) return response.output_parsed
タクシーの乗車費用を経費精算申請する際には、それが業務上必要であったことが分かる「乗車理由」の記入が必要であるという運用をしている企業を想像してください。経費精算申請は、明細が1行含まれているようなシンプルな形式を取ることとします。そこに、タクシーに「なんとなくのってみた」不届者からの経費精算申請が上がってきました。
>>> review_input = ReviewInput(review_target="タクシー乗車理由", expense_application="2025年10月1日 タクシー代 1000円 なんとなくのってみた。")
実際に動かしてみると、見事にAIが弾いてくれています。ここまで極端なものは現実にはあまりないと信じていますが、「理由」など絶対的な基準が決めづらい内容を確認するのは、承認者や経理の方にとって非常に手間と時間のかかる作業です。
また、不十分な状態の申請を差し戻すコミュニケーションを申請者と行うのは精神的にも負荷がかかります。もちろん、申請者にとっても手間が増えるし嬉しい話ではありません。AI申請レビューは、このような本来必要のない業務から人間を解放するために開発されました。
>>> from langfuse.openai import openai >>> openai_client = openai.OpenAI() >>> base_review_expense_application(review_input=review_input) ReviewResult(reason='経費精算申請には、タクシー乗車理由が記載されていますが、『なんとなくのってみた』は具体的な業務目的や必要性が示されていません。そのため、経費として認められるための正当な理由とは言えません。', result=False)
今回のケースではうまく動いたように見えますが、実際にプロダクトに組み込んでお客様に届けるまではまだまだ距離があります。デモを行うだけならこれでもいいのですが、実際のユースケースでは本当に様々な使われ方をするので、その状況でもきちんと価値を届けられるかを確認する必要があります。それに必要な、AIを利用した機能の性能評価について紹介します。
AIエージェント機能の性能評価
AIエージェント機能の性能評価がなぜ重要で、一般的にどのように進めるべきかの説明は他のリソースに任せます。大まかな流れは以下のような形で、手元でのオフライン評価と実環境でのオンライン評価をうまく組み合わせた継続改善サイクルを構築することが重要です。
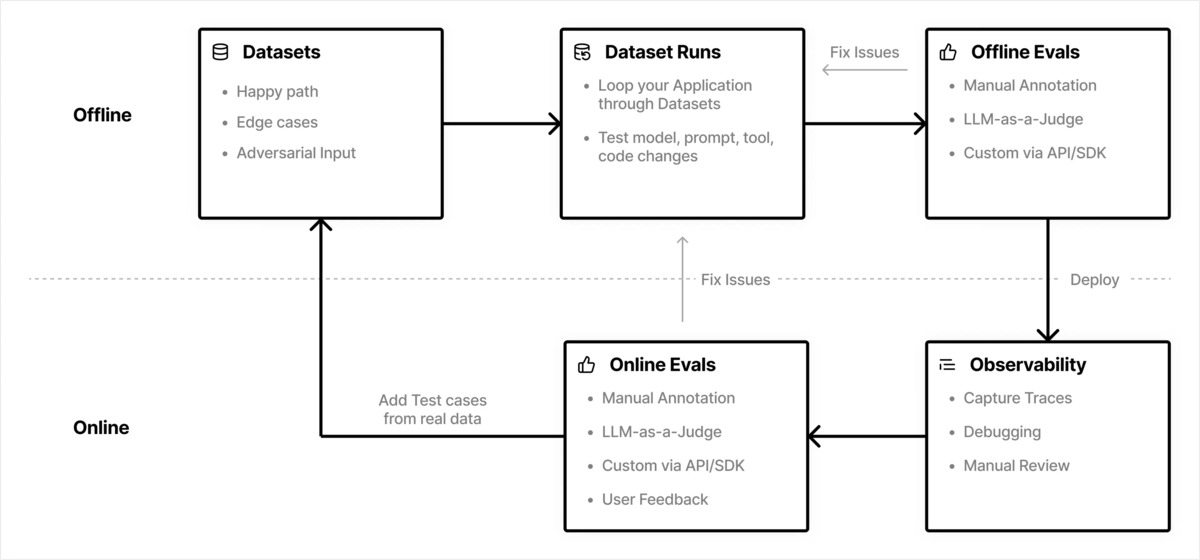
AI申請レビューでは現在、この一連の流れの実現に Langfuse を採用しています。当社の Langfuse に関連する以下の発信も是非ご覧ください。
今回は、Langfuse を利用してどのように評価用 Datasets を作成し、どのように性能評価を行っているのかを2部に分けて紹介します。実環境におけるモニタリングやオンライン評価の話は別の機会にて。
評価用 Dataset の作成
Langfuse には Datasets 機能が備わっており、こちらを利用します。UIからの操作とSDK経由での操作性がともに良く、後述の実験管理も行いやすいと感じています。また、LLMの登場によりAIを扱う開発者の数が大きく増えているため、関係者でデータセットをうまく共有できるだけでも嬉しいと感じています。詳細は以下のドキュメントをご覧ください。
以下のようにitem ごとにユニークなIDが振られ、Dataset への追加日が記録されます。一度追加した item の編集はできないので不便に感じる人もいるかもしれませんが、実験の再現性の観点ではあるべき仕様だと思います。入力(Input )と期待する出力(Expected Output)をJson format で登録します。itemの追加は UI からぽちぽちでも、CSVアップロードでも、SDK経由でも、好きな方法を取れます。
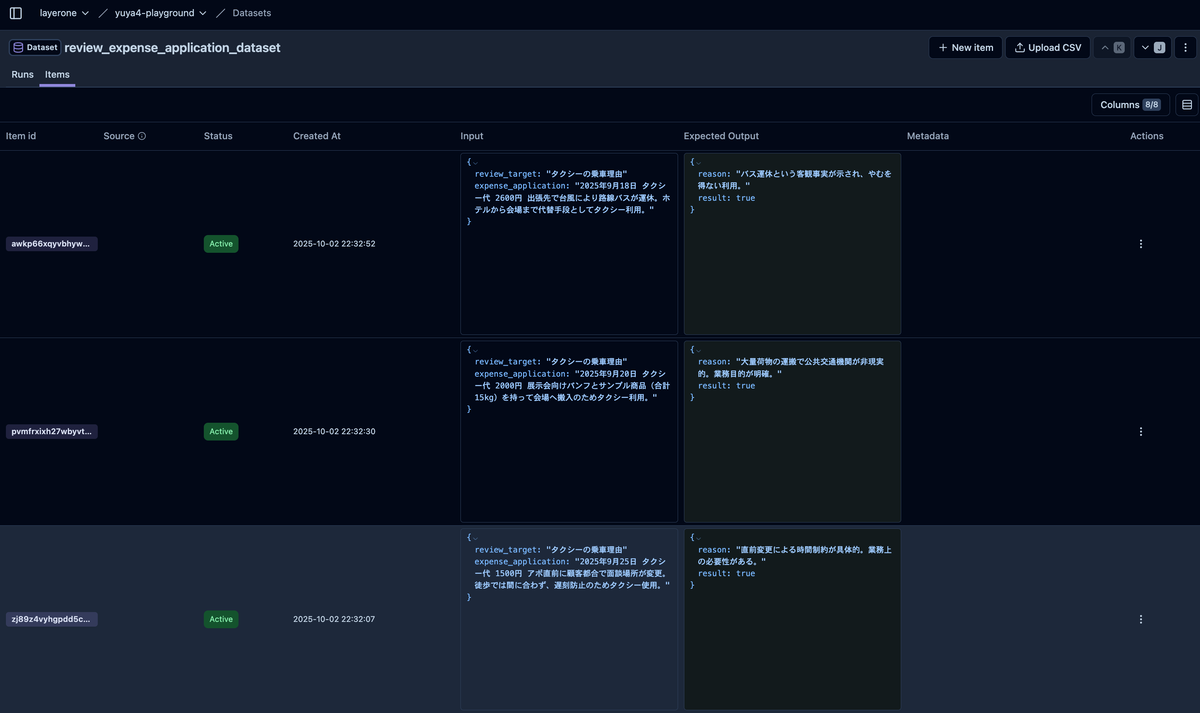
この item を作成する方法を2パターン紹介します。
LLM によるサンプルデータの生成
まだ開発段階であり実際のデータが存在しない場合は、LLMを使ってサンプルデータを作成してもらうことが多いです。
もちろん、ユースケースを調査・ヒアリングすることで必要なケースを洗い出したり、自ら考えて作ることも重要なのですが、それだけではバイアスがかかってデータに偏りが出てしまう可能性も高いです。特に、ベストプラクティスとして、王道のケースだけではなくエッジケースや異常ケースをデータセットに含めておくべきということが知られています。
このようなケースを自らの力だけで洗い出すのは非常に骨が折れますので、LLMの幅広い知識に頼りましょう。いい時代になりました。ただし、生成させたデータは人間の目で確認し、最終的に Dataset に追加するかは可能な限り人間が判断するべきです。
今回は ChatGPTに以下のようなプロンプトを与えて生成してみました。
経費精算申請において、指定された値が正しく申請内に記載されているかを判定し、判定結果をその理由とともに表示してくれるAIエージェントを開発しています。
たとえば、タクシーの経費精算申請において、業務上タクシーに乗る必要があったことの分かる妥当な理由が記載されているかどうかをチェックする場合は以下のような入出力となります。
## 例1
入力:
{
"review_target": "タクシーの乗車理由",
"expense_application": "2025年10月1日 タクシー代 1000円 最寄駅からお客様オフィスまでの公共交通機関がなかったため、タクシーを利用しました。"
}
出力:
{
"reason": "経費精算申請にはタクシーの乗車理由が明確に記載されており、最寄駅からお客様オフィスまでの公共交通機関がなかったためタクシーを利用したことが説明されています。指定された内容が正しく含まれています。",
"result": true
}
## 例2
入力:
{
"review_target": "タクシーの乗車理由",
"expense_application": "2025年9月23日 タクシー代 1000円 なんとなくのってみた"
}
出力:
{
"reason": "経費精算申請にはタクシーの乗車理由が「なんとなくのってみた」と記載されていますが、これは業務上の正当な理由とは認められません。したがって、指定された内容を満たしておらず承認できません。",
"result": false
}
AIエージェントの性能検証に使うデータセットを作成したいです。例のような「タクシーの乗車理由」の記載をチェックするケースの入出力のパターンを複数提示してください。
よくあると考えられる王道のケースやニッチなケースなど幅広くカバーしてほしいです。
以下のようなケースが出力されました。妥当ケースでは、「お客様のオフィスまで公共交通機関がなかったため」や「障害対応で終電を逃したため」という王道に感じるパターンもあれば、「悪天候の中で機材を安全に運ぶため」という、少なくとも私はぱっと思いつかなかったシチュエーションのものも出力されました。
不適切ケースにある、「電車より早いからタクシーにしました」というのもリアルです。本当は事情があるのに、十分に背景を説明できていないようなシチュエーションが想像できます。「私物の大型観葉植物を自宅に持ち帰るため」というのは絶対に自分では思いつきません。
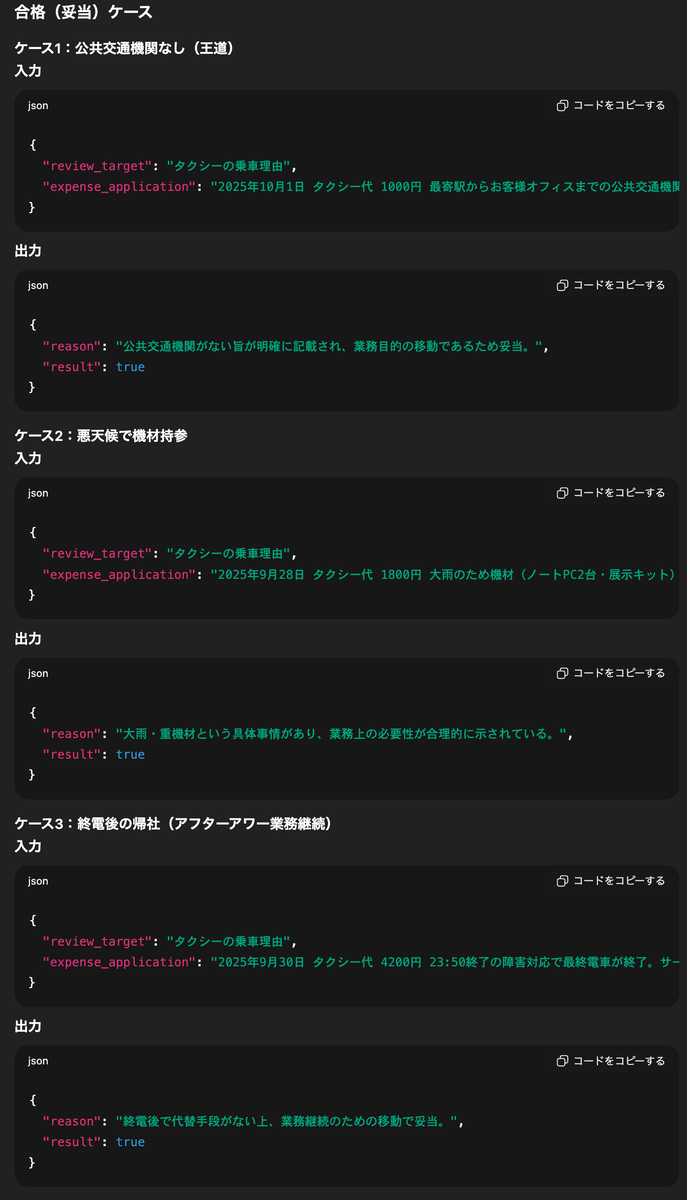

日付や金額を少しずつ変えてくれているのも嬉しい点です。注目している箇所と関係ないからと、すべてのサンプルを同じ日付や金額で作成してしまうなんてこともあるあるなのですが、AIの学習や推論に際してそれが悪影響を及ぼしてしまう可能性があります。昔はこういう値をうまくバラすためのコードを自分で書いて生成したりしていたことを考えると、いい時代になったものです。
実環境からのサンプリング
AI申請レビューのように実ユーザーに提供しているプロダクトにおいては、実際に使われたログデータから必要なデータをサンプリングして Dataset を構築することが可能です。
実データは膨大ですので、どのようにデータをサンプリングするかは腕の見せ所です。よくあるのは、実環境上でAIが間違えたケースを Dataset に追加することでAIの性能改善に活かすという方法です。「AIが間違えたケース」をどのように決定するのかも非常に深遠な問題です。AIプロダクトにおいては、性能評価までを見据えた上でプロダクトの体験を考えて機能に落とし込んだり、ログ・データ構造を設計することが重要です。
一例として、AI申請レビューでは、AIによるFBが間違えていた際にスキップできる機能を提供しています。
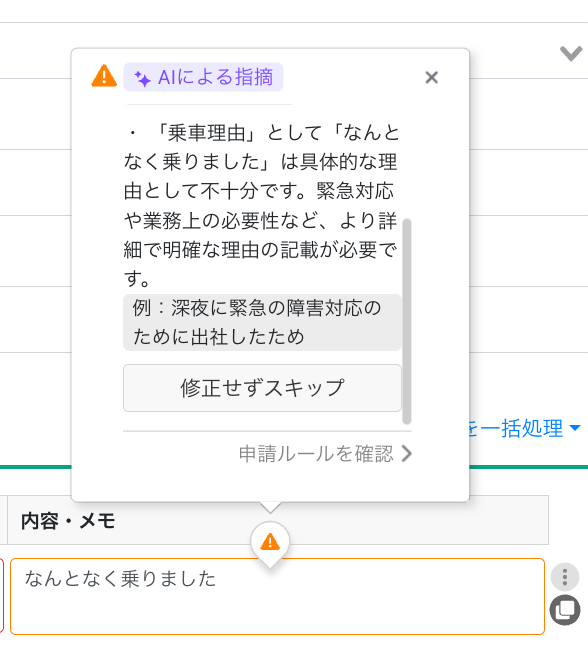
これには、AIの性能が至らなかった場合でもユーザーの業務を止めないようにするという狙いと、ユーザーからの報告を利用して「AIが間違えたケース」を収集する狙いがあります。
LLMの出力に対して「👍(good)」や「👎(bad)」のFBをつける体験には慣れてきた人も多いのではないでしょうか。このように、ユーザーから明確に提供されるフィードバックを明示的フィードバック(Explicit Feedback)と呼びます。
逆に、ユーザーが明確にフィードバックしたわけではない中で、データなどから類推して獲得するフィードバックを暗黙的フィードバック(Implicit Feedback)と呼びます。こちらも非常に奥深くて楽しい部分なのですが、また別の機会に紹介できればと思います。
Langfuse には Scores 機能が備わっており、LLMの実行を含む trace に対してスコアを付与することができます。この機能を使うことで、プロダクト上のフィードバックに基づいて trace を区別したり、後編で紹介するような評価性能実験をうまく管理することができます。
AI申請レビューではこの機能を利用して、先ほど紹介した「AIが間違えたケース」としてユーザーが報告してくれた trace にスコアを付与しており、以下のように該当する trace をフィルタリングすることができます。
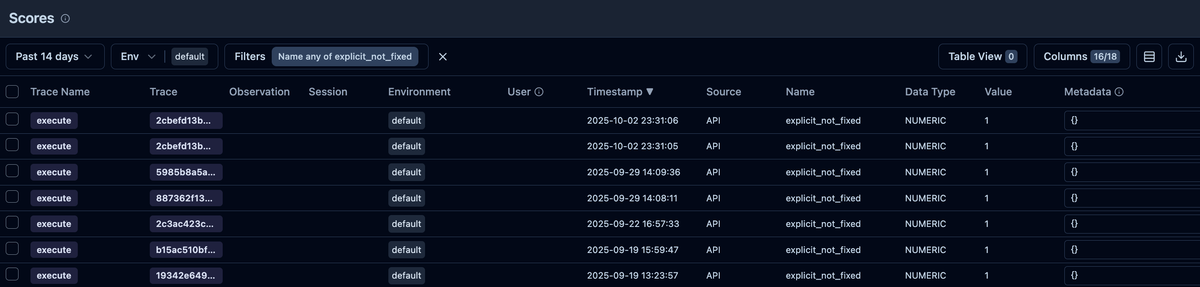
一覧から特定の trace に遷移した後、UI上から Dataset の item として追加する(Add to datasets)ことができます。trace から追加した item は、Dataset 上から元の trace を辿れるのも便利です。
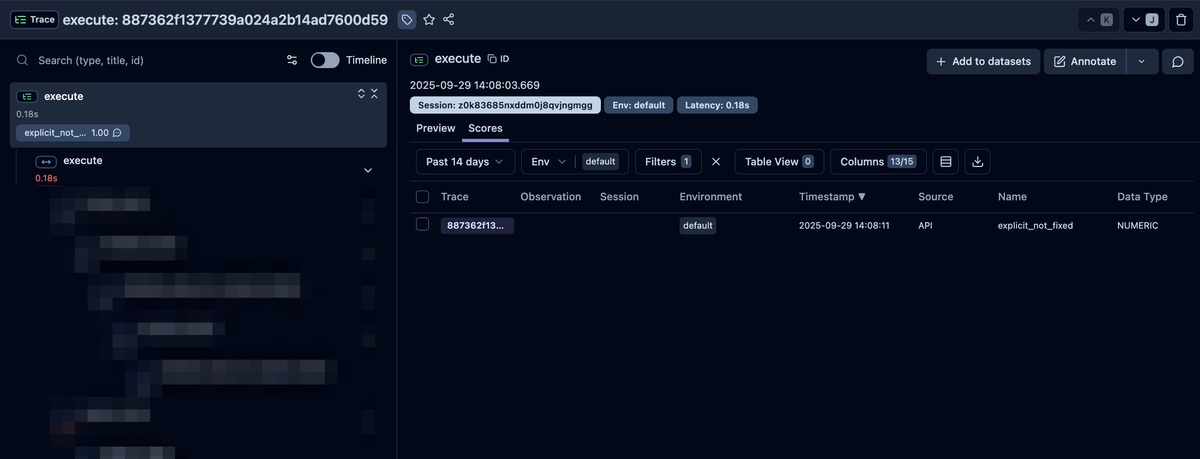
こうして、実環境のデータも活用することで、より実態に即したデータセットを構築することができ、より良い体験を提供するための性能評価に役立ちます。
どのようなデータをデータセットに追加するかを決めるのも腕の見せ所です。頻繁に報告されるケースは迅速にデータセットに追加することで、性能改善やモニタリングに活かすべきでしょう。思いもよらなかったエッジケースが見つかった場合もデータセットに追加しておくことで役立つことがあります。
また、データセットをどのような単位で作成するかというのも考えるべき点です。たとえば、申請の種別によって分けることや、実行する tool 単位で分けること、あるいはお客様単位で分けることなども考えられます。これは、どのような目的でどのような性能評価を行うかによって変わるところです。
結びと次回予告と宣伝
ここまで、AIエージェント機能の性能評価に必要なデータセットの構築について実例とともに紹介しました。実際は他にも様々な手段も取っており、かつ、日々試行錯誤しながらアップデートを重ねています。データセットをどのような考えでどのように作るのかが、性能評価あるいはその先の性能改善やユーザー体験の測定の出来を左右します。
実態に即さない、実環境におけるユーザー体験を反映させられていないデータセットを作成してしまい、それを持って性能評価を行うことで誤ったリリース判断に至って痛い目を見るというのは、みなさんの想像以上に世の中で起こっていることです。そのような場合、実環境のユーザー体験も正確に測定できていないことが多いです。良くない状況にあることさえ検知できず、気づいたときにはユーザーが離れてしまっていたという最悪の事態を防ぐためにも、正しくAIプロダクトの性能を評価できるデータセットを作っていきたいものです。
次回はこのデータセットを用いて実際に性能評価を行なっていきます。性能評価には、先日リリースされた Langfuse の Experiment runner SDK を利用しています。実例はまだ少ないと思いますのでお楽しみに!
LayerXではこのAIエージェント時代をともに駆け抜ける仲間を全方位募集中です。本当に毎日が刺激的で面白いです。少しでも興味を持っていただけたなら是非ともXのDMや以下のフォームなどからご連絡ください。