こんにちは。LayerX AI・LLM事業部 テックリード、osukeです。 Ai Workforce のプロダクト開発をしています。 この1年間で、Ai Workforceは初期フェーズのプロダクトとして成長し、より多くのお客様に提供されるサービスとして成長しています。 初期フェーズはプロダクトとしての機能が圧倒的に足りていなく、機能開発にほとんどのリソースが割かれる中、開発環境の整備にも一定の投資をしてきました。
ここでは、0->1フェーズでプロダクト開発を進めていく中で開発環境をどのように変化させてきたのか、そして今後どうしていきたいのか紹介してきます。
管理画面
初期フェーズ
管理画面開発者が都度、踏み台を経由してデータベースに直接データを書き込むことで運用していました。 これにより、開発者の手動による作業が多くなり、セキュリティ的なリスクや開発者の工数増加など課題がありました。
現在
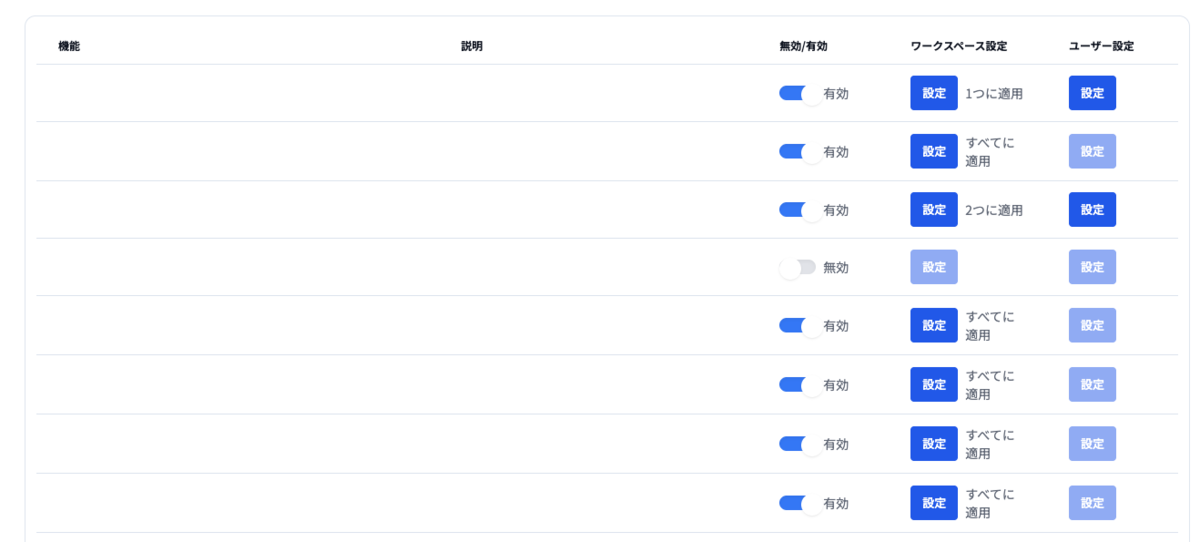
管理画面を整備し、テナントごとの設定や契約情報の閲覧などは開発者の手を使うことなく可能になりました。
Ai Workforceでは、企業ごとのテナントという概念の中に、さらに事業部単位などに分割可能なワークスペースという概念が存在します。 管理画面に存在するフィーチャーフラグ機能では、フィーチャーごとにワークスペースまたはユーザーまでを選択して管理することができるようになっています。
これにより、ベータ版の機能として特定のワークスペースだけ有効化したり、新規機能を本格導入する前の利用検証として、特定のワークススペースの特定のユーザーだけ有効化して試してもらう、といった柔軟な使い方が可能になっています。
これから
管理画面の機能がまだまだ足りていなく開発が必要です。管理画面の機能拡充は、開発者を超えてカスタマーサクセス業務をはじめとした他の業務の効率化にも直結します。
また、フィーチャーフラグは便利ではあるものの、その便利さゆえにたくさんのフィーチャーフラグが追加されてしまい、不具合の原因になったりコードの複雑性があがりがちです。なので、フィーチャーフラグごとにオーナーを明確にし、削除基準や想定利用期間を定め、本来不要なフィーチャーフラグの棚卸しを定期的に実施しようとしています。
静的解析ツール・型チェッカー・パッケージ管理
前提として、Ai Workforceは、現時点では以下のようなフレームワーク・ライブラリが利用されています。
- フロントエンド:TypeScript、Next.js、urql
- バックエンド:Python、FastAPI、Strawberry GraphQL、SQLAlchemy
初期フェーズ
バックエンド(Python)
- Linter/Formatter:Flake8、isort、Black
- 型チェッカー:mypy
- テスト:pytest
- パッケージ管理:requirements.txt + pip
フロントエンド(React)
- Linter/Formatter: ESLint, Prettier
- テスト: Jest
- パッケージ管理:Yarn
現在
移行した部分を太字にしています。
バックエンド(Python)
- Linter/Formatter:Ruff
- 型チェッカー:mypy
- テスト:pytest
- パッケージ管理:uv
フロントエンド(React)
- Linter/Formatter: ESLint, Biome
- テスト: Vitest
- パッケージ管理:pnpm
Linter/Formatterは、バックエンド・フロントエンドともに、RuffやBiomeに移行しました。 これにより、より高速に動作するようになり、LinterとFormatter両方の機能を兼ね備えて、依存ツールを減らすことができました。 Biomeは、一部ルール互換性の問題で、ESLintとのハイブリッド構成となっています。
パッケージ管理もそれぞれuvとpnpmに移行しています。これにより、ライブラリのインストール速度の向上やlockfileで依存管理の厳密性も向上しました。
さらに、言語横断の静的解析ツールとしてsemgrep、secretlint、ls-lintなども導入しています。 特に、semgrepは柔軟にカスタムルールを追加することができ、セキュリティガードレールやコード規約の強制のために重宝しています。
これから
Pythonは動的型付け言語のため型チェッカーは不可欠です。そのため現状mypyを利用していますが、かなり動作が遅いのが難点です。そこで、最近になって astral-sh/ty や facebook/pyrefly など高速な型チェッカーが登場してきています。 執筆時点では、Production Readyではないので導入を見送っていますが、今後移行していく予定です。
また、よりコードベースが肥大化、複雑化し、開発者が増え、チームが分割していく中で、フロントエンドではTurborepoを使ったmonorepo構成に移行しつつあります。これにより、モジュールごとの責務分離を強化しつつ、汎用コードの再利用性を向上させていきます。
ディレクトリ構成
初期フェーズ
バックエンドでは、下記のように大きく3層に分けて、それぞれのレイヤーごとに機能群を配置するディレクトリ構成を取っていました。レイヤーごとにディレクトリを切ることで、シンプルな構造ゆえコードベース全体でのレイヤーの責務が明確化し、小規模な開発チームで進めていくのには適していました。 また、プロダクト立ち上げ期でドメイン構造が明確に決まっていない段階でスピーディに開発を進めていくことができました。
├── api/
│ ├── management.py
│ ├── search.py
│ └── workflow.py
├── service/
│ ├── management.py
│ ├── search.py
│ └── workflow.py
└── repository/
├── management.py
├── search.py
└── workflow.py
現在
より開発規模が大きくなるに伴い、また機能が安定しドメイン境界が明確になるに伴い、以下のように機能別の縦割り構成に移行しました。これにより、機能ごとの完結性が高く特定のディレクトリ内だけで開発が完結することが多くなり、開発がより容易になります。チーム分割とも相性が良く、ディレクトリごとにオーナーチームを割り当てて保守性が上がります。
├── management/
│ ├── resolver/
│ ├── service/
│ └── repository/
├── search/
│ ├── resolver/
│ ├── service/
│ └── repository/
└── workflow/
├── resolver/
├── service/
└── repository/
これから
上記のように、機能別の構成にすることで柔軟性が上がる一方で、機能ディレクトリ内で一定の実装ルールを整備しないとプロダクト全体での統一性が失われてしまいます。例えば、ls-lintで機能ディレクトリ内で作成可能なディレクトリ名をルール付けるなどのバリデーションが必要と考えています。 また、ドメイン境界がよりはっきりしたことで、それぞれの依存関係を整理することが可能となりました。依存関係を整理することで、開発に伴う影響範囲を絞り込むことができます。
さらに、フロントエンド側のディレクトリ構成も整備していく必要があります。その布石として、上述のようにturborepoの導入を進めているのと、フロントエンドはより開発者ごとに実装がバラバラになりやすく、全体的な統一性を高めるための静的解析やコード規約の整備が重要になると考えています。
さいごに
プロダクト開発において、特に初期フェーズではDevOps的な取り組みのバランスが難しいですが、ここで紹介した取り組みが参考になれば嬉しいです。
AI・LLM事業部では、ソフトウェアエンジニアをはじめとして様々な職種で仲間を求めています。
Xの @LayerX_techアカウントではLayerXの様々な取り組みを発信していますので、是非こちらもフォローしてください。