こんにちは。Ai Workforce事業部 FDEグループエンジニアのkoseiと申します。
以下本文は、以前インターンとして一緒にプロジェクトを進めてくれた @kimu さんが在籍中に執筆したものです(冒頭のみkoseiが追記しています)。
本ブログで紹介したアルゴリズムにより精度が向上し、お客様に高い価値を提供することができました。(本手法については特許出願済み)
そこに至るまでの開発の様々な学びが詰まっているので、是非じっくりとお読みください!
はじめに
こんにちは!LayerX Ai Workforce 事業部 FDEグループで2025年3月から11月まで約8ヶ月間インターンをしていた@kimuです。インターンでは主にFDE(Forward Deployed Engineer。顧客課題に密着してプロダクト実装まで担うエンジニア)として、生成AIプラットフォーム「Ai Workforce」上でワークフロー(LLMを用いた文書処理のアルゴリズム)を構築し、お客様の業務効率化に取り組んでいました。
本記事では、リース業界向け「Ai Workforce リースソリューション」のワークフローにおいて、非定型の見積書からの明細データ抽出精度を約80%から約95%に改善した取り組みと、その過程で得た知見をご紹介します。
精度改善の背景と取り組む課題
「Ai Workforce リースソリューション」のワークフローでは、見積書の明細に記載されている物品データの抽出をはじめ、抽出結果に基づくコードの自動付与や、見積書内に特定の物品や記述が含まれていないかの判定といった、リース業務に必要な一連の処理を自動化しています。
このワークフローは実運用に耐える精度は確保できていましたが、処理の一部である「見積書からの明細データ抽出」タスクを改善すると更なる省力化効果が期待できたため、精度改善に取り組むことにしました。というのも、明細データ抽出タスクは正解が一つに決まりやすい一方でエッジケースが多く、精度改善が人手による確認・修正作業の削減に直結するためです。
明細データの抽出タスクの具体的な処理としては、以下画像左側のような非定型の見積書から、全ての項目についてそれぞれの「品名」「数量」「金額」を漏れなく被りなく構造化データとして抽出します。(抽出結果を表形式で記載すると以下画像右側のようになります。)

非定型の見積書からの明細データ抽出タスクにおいて、既存のアルゴリズムでは約80%を達成していましたが、更なる精度改善のためには以下のようなケースが課題として挙げられました。
・長大な見積書で取り漏れが起きやすい
明細が100行を超える(場合によっては400行近いこともある)見積書では、明細の取り漏れが起きやすい
・罫線のないフォーマットでずれが生じる
セルの境界が曖昧なため、項目と金額の対応関係がずれやすい
・スキャン品質の低い文書(FAXなど)で誤読が起こる
文字の潰れや傾きによって文字や数値を誤読してしまう
・不要行(小計・大項目)の混入
除外すべき小計行や大項目が誤って抽出されてしまう
例えば以下の見積書は1ページ目に大項目が存在し、2ページ目以降に各大項目の内訳明細が記載されています。
ワークフローは1ページ目の大項目を全く抽出せずに内訳明細の項目のみを抽出する必要があります。
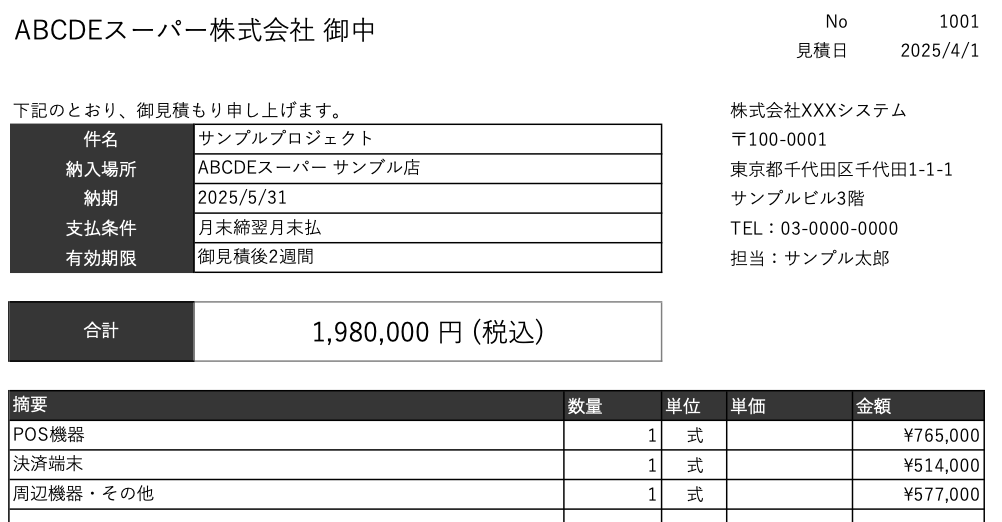
当社作成のサンプル見積書の一部(1ページ目)
大項目のみが記載されている。

当社作成のサンプル見積書の一部(2ページ目)
大項目「POS機器」の内訳として具体的な項目とその金額が記載されている。
結果
上記のような様々なケースに対応できるアルゴリズムに改善することで、大幅な精度向上を実現することができました。
・評価指標:明細項目(商品・費用・値引き)の金額を漏れなく被りなく抽出できている見積書の数の割合
・結果:約80% → 約95%(約100件の見積書で評価)
具体的なアルゴリズムの改善について、次のセクションで説明していきます。
改善アプローチ
今回の改善では、明細抽出の精度を高めるために大きく2つのアプローチを実施しました。
1. OCR結果に画像情報を組み合わせる
従来は Azure AI Document Intelligence による見積書のOCR結果のみをLLMの入力として用いていました。OCRの段階で構造認識を誤ってしまうと、その後どれだけLLMの処理を工夫しても、ミスが発生してしまいます。
その一例として、罫線のない見積書があります。

(例)当社作成のサンプル見積書。内訳明細のカラムごとに縦線が引かれていない。
このような見積書では列の境界が不明瞭なため、OCRの出力として正しい項目と金額の対応関係が得られず、結果としてLLMの出力項目と金額の対応関係が間違っていたり、そもそも抽出が漏れたりする事象が見られました。
この課題に対しては、OCR結果に加えて見積書画像そのものをLLMの入力として併用するようにすることで改善しました。画像情報を補助的に使うことでLLMが項目の対応関係を把握できるようになり、罫線の欠如や文字潰れといったOCRの誤認識の悪影響が軽減し、結果として全体の精度が向上しました。
2. 差分チェックで取り漏れや誤抽出を自動修正
明細抽出の精度をさらに高めるため、差分を利用した再推論プロセスに変更しました。全体像は以下の通りです。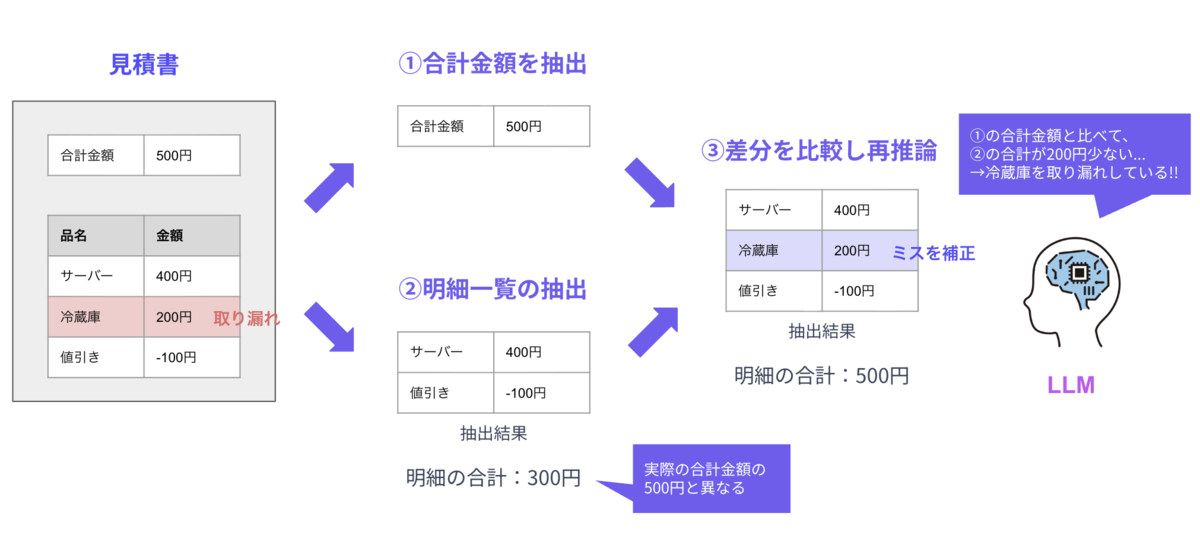
①合計金額を抽出
最初に、LLMは見積書の冒頭に記載されている合計金額を抽出します。
以下の画像の見積書においては、「4,180,000円(税込)」の部分が該当します。
当社作成のサンプル見積書の一部。
②明細一覧の抽出
続いて、明細データをLLMで抽出します。
400行を超えるような長大な見積書にも対応するため、PDFを1ページごとに分割して処理し、その結果を結合しています。
ただし、ページ単位で処理を行うため、前後ページの文脈を考慮できず、サマリ行などの判別が難しくなるケースがあり、この段階ではまだ抽出漏れや誤抽出が存在しています。
③差分を比較し再推論
ここが今回の精度向上において特に重要な点なのですが、最後に②で抽出した明細の合計金額と、①で取得した合計金額を比較します。
この差分の計算をルールベースで行い、金額に差分がある場合のみ、LLMがその情報をもとに再推論を実行し、取り漏れや誤抽出を検出します。
差分チェックと再推論を繰り返すことで、項目数が多い・大項目を含むような複雑な見積書でも、抽出精度を向上させることができました。
得た学び
学び①:ワークフローを先に作ることで、正解データ作成を効率化する
精度改善プロジェクトにおいて、まず最初に取り組んだのが、Langfuseを使った検証環境の構築でした。
ワークフローの各ステップの出力やスコアを記録し、精度を定量的に評価できるようにするためです。
精度を評価するには正解データの作成が必要ですが、この工程は一般的に工数を要する部分です。
特に見積書の中には300行を超えるものもあり、すべての明細に対して「品名」「数量」「金額」の正解データをゼロから人手で正確に整備するのは現実的ではありません。
そこで、今回のプロジェクトでは次のような流れで正解データを作成しました。
- 既存ワークフローの出力を活用
すでに約80%の精度で動作していたend-to-endのワークフローがあったため、その出力結果をベースに正解データを作成する。 - 出力結果の確認と修正
ワークフローの出力を、確認しやすい形式(今回はビジネスメンバー向けにExcel)に転記し、人手で確認・修正を行う - 修正したデータをJSONに変換
修正を終えたExcelデータをPythonスクリプトでJSONに変換し、検証で扱いやすい形式にする
今回の経験から、まずある程度の精度で動くワークフローを作り、その出力を基に正解データを整備するというプロセスが効率的だと感じました。
この方法によって、正解データをより短時間で作成できるだけでなく、金額の桁数ミスなどのヒューマンエラーを減らすことができ、速く・正確にデータを作れるようになったと実感しています。
学び:ある程度の精度で動くワークフローを先に作り、その出力を活用することで、正解データをより速く、より正確に作れる。
学び②:LLMの特性を踏まえてモデルを使い分ける
今回の改善では、LLMのモデルをどのように使い分けるかが、精度と処理速度を両立する上で重要なポイントでした。
前提として、LLMには以下の2つの特性があります。
- モデルによって精度と処理速度にトレードオフがある
例:
o3:高い精度を発揮する一方、処理時間は長い
GPT-4.1:処理は高速だが、精度はやや劣る
それ以外にもOpenAIの公式ドキュメントにはさまざまなモデルの特性がまとめられており、読んでみると面白いです! - LLMの処理時間は出力トークン数に大きく依存する
出力が長くなるほど、処理時間もコストも飛躍的に増加してしまう

出所:https://platform.openai.com/docs/guides/latency-optimization#generate-fewer-tokens 出力トークン数をコントロールするためのTIPSは以下の記事でも紹介しています。
これらの前提を踏まえ、精度と処理速度を両立するために、次の2点を意識してモデルを使い分けました。
- reasoning modelを使うのは、難易度が高く必要な箇所だけに限定する
それ以外の処理は、ルールベースや高速なモデルで対応する - reasoning modelを使う場合は、出力トークンをできるだけ減らす
処理速度を小さくするために、最小限の情報だけを出力させる
例えば、今回作成したワークフローの明細抽出処理は以下のようなモデルの使い分けを行っています。

-
明細一覧の抽出:GPT-4.1を使用
このステップでは、すべての明細を抽出するため出力トークンが多くなります。
処理速度と精度のバランスを考慮し、GPT-4.1を採用しました。 - 差分の比較と再推論:o3を使用
合計金額と抽出結果を比較し、抜け漏れや誤抽出を推論するステップです。
このステップでは、抜け漏れや誤抽出が同時に起こっているケースなどがあり、より高度な推論や整合性の判断が求められるため、精度の高いo3を使用しました。
o3は高精度な一方で処理時間が長いため、この短所をカバーする目的で出力トークンを削減しました。具体的には、すべての明細を再生成せずに「抜け漏れた明細」と「余分な明細」だけを特定・出力させ、その結果を②の抽出結果にルールベースでマージして明細を補完・修正しています。
学び: reasoning modelは、難易度の高いタスクにのみ限定して使用し、出力を最小化することで処理時間とコストを抑える。
おわりに
この記事では、見積書からの明細データ抽出精度を約80%から約95%に改善するまでの取り組みと、その中で得られた工夫や学びを紹介しました。
8ヶ月のインターンシップの中で、今回紹介させていただいたワークフローの改善の他にも、プラットフォームの開発、資料作成、お客様への改善結果のご報告など幅広い業務に携わることができ、とても貴重な経験を積むことができました。
もしこの記事を読んで興味を持っていただけた学生の方は、ぜひLayerXのインターンに応募してみてください!
【Ai Workforce】AIワークフローエンジニア(実務インターン) / 株式会社LayerX
【Ai Workforce】ソフトウェアエンジニア_実務インターン / 株式会社LayerX
また、本記事でご紹介したような「LLMをうまく扱ってお客様に価値を届けるエンジニアリング」についてもっと話したい・聞きたい方は是非カジュアル面談でお話ししましょう!