
こんにちは!Ai Workforce事業部FDEの恩田(さいぺ)です。
7月にFDE(Forward Deployed Engineer)の募集を開始し、早半年が経過しようとしています。本記事では、FDE組織の募集を開始してから現在までをふりかえりつつ、2026年のFDEやLLMについて、組織・技術の両面から綴ってみたいと思います。
FDEの募集を始めたのは今年7月なのですが、この半年で突然生まれた職種というわけでなく、その原型はLayerXの創業当時まで遡ります。LayerXでは祖業のBlockchain時代から当時のCTOがお客さまのところに足繁く通ってきました。また、三井物産さまとのジョイントベンチャーである三井物産デジタル・アセットマネジメントにはCTOクラスのメンバーをはじめ、複数のメンバーがフルコミットしています。私自身、LayerXでBlockchain/PrivacyTech時代(Ai Workforce事業部の歴史については下記画像を参照)にはインターネット投票、医療、クレジットカード、パーソナルデータ、走行データ、不動産など様々なドメインに向き合ってきました。時には政府のワーキンググループの議事録をすべて読んだり、関連法令や業界団体の規制、その立法背景などをお客さまと議論できるレベルまでキャッチアップし、現場ではそのデータでどのような業務がなされているかヒアリングを重ねるなど、FDEの原型となるような働き方をしてきました。
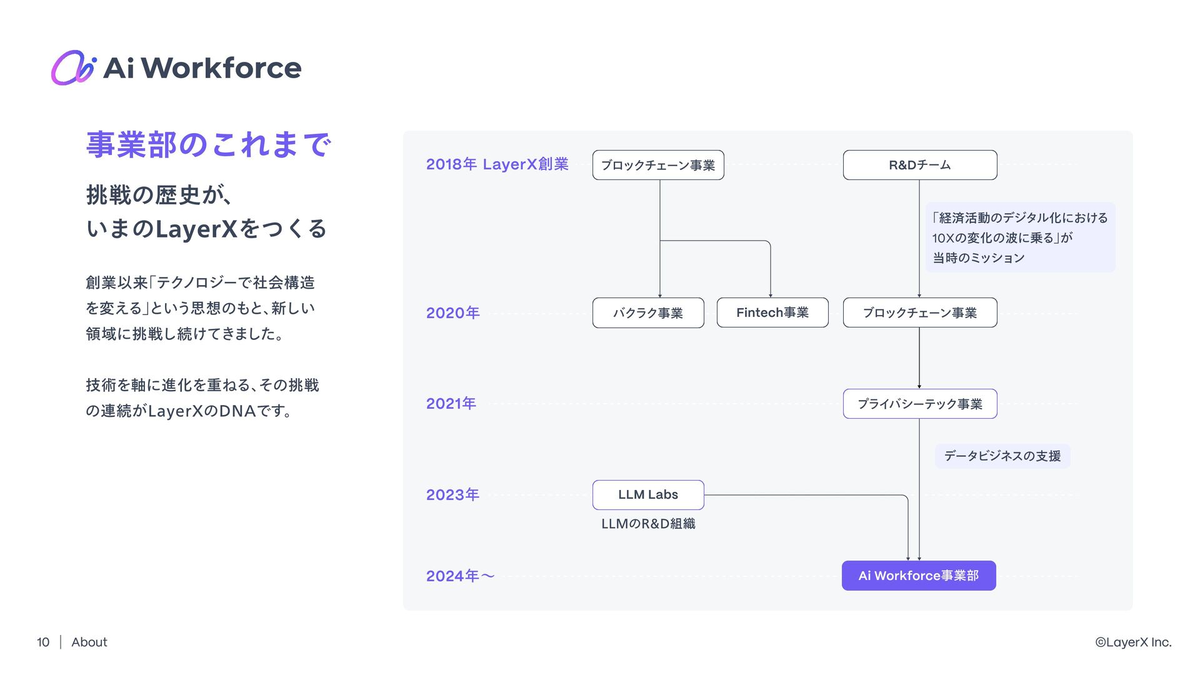
FDEの原型という意味では、LayerXには創業以来の積み重ねがあります。また、FDEの生みの親であるPalantirの研究活動もBlockchain時代から行っており、当時の採用ピッチデックにも残っています(昔のロゴやカラーも懐かしい)。

一方で、FDEのJDを公開するとなると、FDEという職種は日本では知名度がなく、閑古鳥が鳴いてしまうのではないかという不安がありました。しかし、自分たちの職業を言い表す言葉としてFDEほど的確なものはなく、むしろ自分たちで盛り上げていこうという強い気持ちを持って公開に踏み切りました。公開してからは、兎にも角にもまずはFDEという職種を知ってもらおうとpodcastを配信したり、メンバーからもブログを発信したり、イベントを開催したりしました。
open.spotify.com open.spotify.com tech.layerx.co.jp layerx.connpass.com note.com
事前の予想とは裏腹に、2025年下半期はFDEという職種がにわかに盛り上がったのではないかと思います。ありがたいことに社内イベントだけでなく、外部のイベントやpodcast、YouTube、テレビ、記事でも取り上げていただくことができました。
txbiz.tv-tokyo.co.jp blog.allstarsaas.com
x.comNIKKEI Tech Talk #38 のテーマは、「AIと人が共創する個別ニーズへの対応〜情報処理から価値創出への転換〜」です。AIやMLを駆使して、お客様の個別ニーズにどう応えるか――最前線の事例と実践的なアプローチを学べる技術勉強会です。 #nikkei_tech_talk https://t.co/T4EQd5hu5Z
— NIKKEI Developers (@nikkeideveloper) 2025年10月23日
x.com www.youtube.com xtech.nikkei.com open.spotify.com📣生成AI時代の新キャリア「FDE」に関するオンラインイベントを実施します!
— Findy(ファインディ) (@findy_code) 2025年10月27日
LayerXとファストドクターに聞く!OpenAIでも募集しているAI特化の職種とは?
〜生成AI時代の新職種 FDE(Forward Deployed Engineer)を深堀り〜https://t.co/q8IHGOgeiH
x.com#Newbee 1月の番組表です!
— はち🐝 Newbee 代表 (@PassionateHachi) 2025年12月24日
Special Thanks:@kyuns , @productken , @evelyn_mawuli , @onishiki_plus . @kawaguti , @Nunerm , @pauli_agile , @cipepser , @mawarisuru pic.twitter.com/2j7kSX42L2
実際に組織拡大という観点でも、OpenDoorで断続的にご連絡を頂けたり、採用のご応募もこれまでの数倍に増え、FDEの盛り上がりを感じています。
また、組織としても大きな転換点を迎えたのがこの下半期でした。10月にはCTO経験者の白井がEMとして参画し、マネジメント層が大幅に強化され、チームの規模も倍以上になりました。年明けに参画予定のメンバーも続々とおり、来年はより飛躍の一年となりそうです。
FDEがどう事業に貢献しているか
FDEはAi Workforce導入の最前線にいます。お客さまの課題を最前線で定義して解決していく役割ですが、客観的にLayerXのFDE組織ではこの点にはまだまだ成長の余地があります。よく「常駐してるんですか?」と質問をいただくのですが、正直に答えるとごく一部のみに留まっています。あくまで常駐は手段でしかなく、その目的によって意義や常駐する人のモチベーションが大きく変わってきます。Ai Workforce導入の入口となるプロジェクトでは、お客さまの資料をお預かりし、それを入力に理想の出力を出すためのエージェントやAIワークフロー構築が主な業務となります。まずはそこで結果を出すことが、次のステップへと繋がります。当然ではありますが、お客さまは特定の資料を特定の出力にする業務だけを行っているわけではありません。他部署や関係会社、取引先とのやり取りや基幹システムや台帳への記載など「前後の業務」が必ず存在しますし、全く異なる業務もされています。Ai Workforceはプラットフォームプロダクトのため、特定のユースケースに留まらず、幅広い業務を対象としています。こういったお客さまの業務を深く知る意味では、常駐は強力な武器になり得ます。
FDEはプロダクトへのフィードバックサイクルを劇的に早める役割も果たしています。 例えば、Ai Workforceはこの秋、システム・アーキテクチャを刷新しました。その際、既存のアーキテクチャ上で本番利用頂いているお客さまのユースケースを損なうことなく移行する必要があります。お客さまにヒアリングせずとも既存のユースケースの業務を熟知しているFDEが社内にいることで、PdM(プロダクトマネージャー)やデザイナーに新しいアーキテクチャ上での体験について素早くフィードバックを行うことが可能です。かくいう私も今週はFigma Makeで画面イメージを作成し、ユーザーストーリーを作成する動きをしていました。
FDEはハイパフォーマーが大きな価値を発揮しやすい職種ですが、こと事業活動においてはFDEをエンパワーするプラットフォームの存在が欠かせません。例えば、Ai Workforceはエンタープライズのお客さまにご提供しているため、アクセス制御が必ず求められます。また、Ai Workforce内で完結しない業務向けに成果物をWordやExcelにエクスポートする機能が実装されています。現場では前後の業務と滑らかに接続できることが求められますし、毎度こういった機能をFDEが実装していると時間がいくらあっても足りません。FDEが本来解くべき課題に集中できるようにするためにもプロダクト自体の進化は必要不可欠です。現場で発生した事例をベースにプロダクトへフィードバックするのはもちろんですが、こういった機能をFDE自身が開発することもあり、プロダクトへの貢献もFDEの大きなミッションの一つです。目指すべき先人としてPalantirに目を向けると、彼らのOntologyでデータを扱うためのData Connectionは、一度接続したシステムのデータの再利用性を高める機能で、強力なmoatでしょう。こういった方向性も今後推進したいトピックの一つです。
2026年の展望
LLMの勝ち筋となる領域はどこか
LLMの業務利用が進み、相性の良い領域が少しずつ見えてきたように思います。まずエンジニアとしてもわかりやすいのが、開発領域です。プログラミング言語は人工的な言語であることから構造化されており、LSPやgrepツールなどにより高い精度で必要なコンテキストをLLMに渡しやすく、単体テストにより評価まで自動化できるという、品質向上の弾み車が回る条件が整った領域です。構造化された入力、単一タスクの高精度、評価といった条件が揃う領域は、LLMにとって典型的な勝ち筋になりやすいでしょう。
別の観点ではROIが得やすい領域です。例えば、従業員数によってスケールしたり、リース業界の資産管理業務は主たる業務の一つであり、必然的に業務量が多くなります。このような領域は、部分的な効率化であっても削減される業務量自体が大きくなる傾向があり、ROIが見込める領域です。 FDEはお客さまの業務の中でこういった領域の問題に落とし込める見識が必要です。
人間の負荷を少なくするLLMの使い方を発明する
AIやLLMを業務に溶け込ませるために難しいのは、LLMが確率的な挙動をするためだと考えています。ただ、現場目線ではLLMが出した答えをそのままノーチェックで次の業務に渡すことができない点がハードルです。さらにいうと、LLMから出てきた答えを「すべて」人間がチェック・レビューしないといけない点です。これに対して、LLMに信頼度を合わせて出力させる、LLM as a judgeによるレビューなどを検討された方も多いとは思うのですが、結局LLMを信頼できるのかという問題に帰着し、失敗が許されない領域ではやっぱり人間が全量チェックしなければならなくなっているケースも多いと思います。現在当チームでは、「全量チェック」から「人間が見るべき箇所を減らす」というスコープの絞り込みの問題に落とし込むことに挑戦しています。これが成功すれば、「業務で使えるLLM」に大きく近づく予定です。
Long Tasksを解く
人間は、数分の単発タスクだけでなく、数カ月に渡る長期間の業務を行います。こうした実業務を代替・支援していくために、Effective harnesses for long-running agentsやMeasuring AI Ability to Complete Long Tasksで述べられているようなLong Tasksが一つのトレンドになると思います。
この領域ではSolving a Million-Step LLM Task with Zero Errorsという論文がとてもおもしろかったです。タイトルの通り、100万ステップの問題を一つのエラーもなく解こうという内容です。LLMは確率的な挙動を取るため、なかなか精度100%を達成することは難しいのですが、100万ものステップがあるタスクでは、仮に単発のステップが99.99%の成功確率であったとしてもすべてのステップが成功し切るのは天文学的な確率になってしまいます。
そこでこの論文ではFirst-to-ahead-by-k Votingによる誤り訂正を行っています。何度もLLMを実行し、k票差付けてトップになった候補を採用することで、たまのLLMの失敗を誤り訂正しようという発想です。この論文のおもしろいのは、この誤り訂正の方式そのものではなく、このkがステップ数に対して対数でスケールすることを示している点です。他にもLLMの実行コストのスケーリング則についても言及されていたりと、特に3.2節が面白いのでぜひ読んでみてください。一方で、この論文で扱っているのは、ハノイの塔を100万ステップで解くという問題のため、各ステップが均一的です。実際の業務はタスクが不均一であり、適切なステップに分解する問題は依然として難しいというのは論文でも言及されている課題です。このような課題があるため、すぐにAi Workforceに応用できるわけではないのですが、誤り訂正については別のアプローチで検証を行っています。
使えば使うほど、エッジケースの網羅率が上がるプロダクト
FDEはエージェントやAIワークフローを構築していますが、現実の業務はそんなに単純にモデル化できません。どこまでいっても、構築時に想定していなかった入力が当たり前のように発生します。事前にこのパターンをできるだけ網羅することも大事ですが、そもそも外部環境も変化する以上、事前に網羅率を100%にするだけでは実業務に耐えられません。人間の助けを借りてでもロバストにエッジケースに対応し、二度目はシステム単独で対処できるようにすることが実業務に使えるアプリケーションです。
この「使えば使うほど賢くなるプロダクト」というコンセプトは誰もが思いつくものです。プロダクト提供者にとってはmoatとして競争力に繋がりますし、お客さまにとってもどんどん便利になるため、win-winな形で望まれるものですが、その設計は非常に難しいです。世の中の「使えば使うほど賢くなるプロダクト」の実例は、問い合わせに対して類似の回答例をRAGで取ってくる、というようなパターンが多いように感じています。これ自体はうまくワークすれば強力なのですが、実際には使えば使われるほど検索対象となるデータが増加し、Retrieve精度の悪化を招きやすくなるという性質があります。
Knowledge Graphを始めとしてAgent Memoryの進化は2026年の一つのトレンドになるでしょう。この進化と並行して、未知のエッジケースに対して、human feedbackによって解決した方法を組み合わせるとエラー訂正になるという仮説を考えています。発見すべきはナレッジや回答そのものではなく、その検証手順であるという仮説です。我々が属人化と呼んでいるものの一つの正体が、ある業務をするときに複数存在する業務手順のことなのであれば、ある業務を実現するときに適切な手順を適切な数だけ取ってくることができれば、業務のエッジケースの網羅性を上げられるのではないかと考えています。
最後に
年末ということでキャリアを考える方もいらっしゃるかと思います。FDEは公開して半年の職種ではありますが、経営陣もチーム設計や報酬設計に深く切り込んでいます。
x.comFDEについてです。チーム設計や報酬設計などかなり根本に切り込んで、新しい職種を作っていきます。興味がある方はぜひ松本か私と面談してみてください!
— 福島良典 | LayerX (@fukkyy) 2025年12月22日
FDEというあり方── エンジニアキャリアと経営・CTOをつなぐ新たな一歩として|Matsumoto Yuki @y_matsuwitter https://t.co/89bLmnboeS
FDEに興味があるという方はお気軽に以下のリンクからカジュアル面談にお声掛けください。 また、採用ページからのご応募もお待ちしています。それでは皆さま良いお年をお迎えください。